第一章 语言基础
MetaQuotes Language 5(MQL5)是一种面向对象的高级编程语言, 用于编写自动交易策略、用于分析各种金融市场的自定义技术指标。 它不仅可设计编写各种EA系统用于实时操作,而且还可以创建自己的图形工具来帮助您做出交易决策。 MQL5基于流行的编程语言c++的概念。与MQL4相比,这种新语言现在具有枚举、结构、类和事件处理。 通过增加嵌入式主类型的数量, MQL5中的可执行程序通过 dll 与其它应用程序之间的交互现在变得尽可能容易。 MQL5语法类似于c++的语法,这使得从现代编程语言转换为 MQL 程序非常容易。
为了帮助您学习MQL5语言,将所有主题分成以下几个部分:
- 语法
- 数据类型
- 运行式和表达式
- 运算符
- 函数
- 变量
- 预处理程序
- 面向对象的程序设计
# 1.1 语法
在语法上,MQL5语言与c++语言非常相似,除了以下一些特性:
- 没有运算地址;
- 没有goto语句;
- 不能声明匿名枚举;
- 没有多重继承.
相关参考
枚举、 结构和类、 继承
# 1.1.1 注释
多行注释使用 /* 作为开始,用 */ 表示结束,在这之间不能够嵌套。 单行注释使用 // 作为开始,直以到一行结束,可以被嵌套到多行注释之中。
示例:
//---单行线注释
/* Multi-
line //嵌入式单行线注释
comment
*/
2
3
4
5
# 1.1.2 标识符
标识符用来给变量和函数进行命名,长度不能超过63个字节。 可以用在标识符中的字符包括: 数字0-9、拉丁字母大写A-Z和小写a-z(大小写有区别)还有下划线(_)。 此外,首字母不可以是数字,标识符不能和 保留字 冲突。
示例:
NAME1 namel Total_5 Paper
相关参考
变量, 函数
# 1.1.3 关键词(保留字)
下面列出的是固定的保留字标识符,每个保留字标识符相当于一个动作,不能用来操作其他命令。
数据类型
| bool | float | uint |
| char | int | ulong |
| class | long | union |
| color | short | ushort |
| datetime | string | void |
| double | struct | |
| enum | uchar |
访问分类符
| const | private | virtual |
| delete | protected | |
| override | public |
存储类型
| extern | input | static |
操作符(语句)
| break | dynamic_cast | operator |
| case | else | pack | continue | for | return |
| default | if | sizeof |
| delete | new | switch |
| do | offsetof | while |
其他
| this | #define | #import |
| true | #ifdef | #include |
| false | #ifndef | #property |
| template | #else | #group |
| typename | #endif | #namespace |
# 1.2 数据类型
任何程序都依靠数据来运作,数据有不同的用途,因此分为不同的类型 。 比如,访问数组的序号可以用整数型,价格可以用双精度的浮点型数据。 在 MQL5 中没有专门用来标记货币的数据类型。 各种数据类型有不同的处理速度,整数型是最快的。 双精度的数据处理需要特殊的协同处理器,因此处理浮点型数据比较复杂,所以它比处理整数型数据慢一些。 字符串的处理速度最慢的,因为它需要动态的存取内存。
基本数据类型:
- 整数型 (char, short, int, long, uchar, ushort, uint, ulong)
- 逻辑型 (bool);
- 字符型 (ushort);
- 字串型 (string);
- 浮点型 (double, float);
- 颜色 (color);
- 日期和时间型 (datetime);
- 枚举型 (enum).
复杂的数据类型:
- 结构(structures);
- 类(classes).
就OOP(面向对象的程序设计)而言,复杂数据类型又被称作 抽象数据类型。
颜色 和 时间日期 类型可以使我们清楚直观的区分图表上的内容。 以及在 EA 和 自定义指标 中输入外部参数时经常使用这些数据类型(输入外部参数的标签颜色)。 颜色 和 日期时间 数据用整数来表示。整型数据 和 浮点数据 都属于数值(数字)型。
只有在表达式中使用隐式类型的类型,除非指定了显式的类型。
TIP
(智能交易*姚提示——意即,在 表达式 中,常量或变量的类型没有声明的,即 隐藏式 的。 当然也可以声明。如
Print(1+2.0);
// 这里表示打印输出 1+2.0 的结果,1 可能是整数型,2是浮点数型,表达式中,数据类型是 隐式 的。
Print((int)1 + (double)2.0);
// 这一行与上一行结果一致,当然很少这样写 表达式。这里,数据类型是 显式 的。
2
3
4
5
相关参考
类型分类
# 1.2.1 整数型
在MQL5中整数有11个类型,如果逻辑程序需要,一些类型能与另一些类型一起使用, 但是在此种情况下,请记住类型转换规则。 下面列表中显示了每一种类型的特性,此外,最后一列与C++语言中的整数类型进行了比较。
| 类型 | 字节大小 | 最小值 | 最大值 | C++ 类比 |
|---|---|---|---|---|
| c | 1 | -128 | 127 | char |
| uchar | 1 | 0 | 255 | unsigned char, BYTE |
| bool | 1 | 0(false) | 1(true) | bool |
| short | 2 | -32768 | 32767 | short, wchar_t |
| ushort | 2 | 0 | 65 535 | unsigned short, WORD |
| int | 4 | -2147483648 | 2147483647 | int |
| uint | 4 | 0 | 4294967295 | unsigned int, DWORD |
| color | 4 | -1 | 16 777 215 | int, COLORREF |
| long | 8 | -9 223 372 036 854 775 808 | 9 223 372 036 854 775 807 | __int64 |
| ulong | 8 | 0 | 18 446 744 073 709 551 615 | unsigned __int64 |
| datetime | 8 | 0 (1970.01.01 0:00:00) | 32 535 244 799 (3000.12.31 23:59:59) | __time64_t |
整数类型的值也可以作为数值常量、颜色值、字符、日期时间的值、字符常量和枚举值。
相关参考
数据变换, 数值类型常量
# 1.2.1.1 字符型、短整型、整型和长整型
char
字符型数值在内存中占用的存储空间为1个字节(8位元组),最多可以表达2^8=256个不同的值。字符型包括正值和负值,因此范围在 -128 到 + 127之间。
uchar
无符号字符型和字符型一样,也占据1字节内存,但与之不同的是,它只有正值。最小值是0,最大值是255,无符号字符型的第一个字母u,即unsigned的缩写。
short
短整型数据占用2字节(16位元组)的空间,所以它可以表达2^16 = 65 536个不同的值,短整型包含一个符号位,因此包括正值和负值,范围在 -32768 到 +32767之间。
ushort
无符号短整型是ushort,也占用2字节,最小值是0,最大值是65535。
int
整型占用4字节内存(32元组),最小值是-2147483648,最大值是2147483647。
uint
无符号整型是uint。它占用4字节内存,取值范围是0到4294967295之间。
long
长整型占用8字节(64元组),最小值是-9223372036854775808,最大值是9223372036854775807。
ulong
无符号长整型也占用8字节,能存储从0到18 446 744 073 709 551 615之间的值。
示例:
char ch=12;
short sh=-5000;
int in=2445777;
2
3
DANGER
无符号长整型不能表达短整型的负值,如果赋值为负数会导致意外的结果。下面的示例脚本会无限循环:
//--- 无限循环
void OnStart()
{
uchar u_ch;
for(char ch=-128;ch < 128;ch++)
{ //因为 ch 是 char 类型 ,最大值为 127,因此 ch < 128 结果永远为 真
u_ch=ch;
Print("ch = ",ch," u_ch = ",u_ch);
}
}
2
3
4
5
6
7
8
9
10
11
# 1.2.1.2 字符常量
在 MQL5 中,单个字符是组成字符串的要素,是按Unicode字符集的索引排序的。 它们可以转换成十六进制整数,也可以像整数一样进行加减运算操作。 用单引号括起来的任何一个单一字符 或 十六进制的 ASCII 代码 (如:'\x10') 都可以被当做字符常量,和无符号短整型数值, 例如,’0’ 对应的整型数值是 30,对应于字符表中索引0的字符。
示例:
void OnStart()
{
//--- 声明字符常量
int symbol_0='0';
int symbol_9=symbol_0+9; // 获得字符 '9'
//--- 输出常量值
printf("In a decimal form: symbol_0 = %d, symbol_9 = %d",symbol_0,symbol_9);
printf("In a hexadecimal form: symbol_0 = 0x%x, symbol_9 = 0x%x",symbol_0,symbol_9);
//--- 输入常量成字符串
string test="";
StringSetCharacter(test,0,symbol_0);
StringSetCharacter(test,1,symbol_9);
//--- 这里看起来就像字符串一样了
Print(test);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在程序源代码中处理文本常量时,反斜线 字符是编译器的控制字符,一些符号, 例如,单引号('),双引号("),反斜杠()和一些控制字符都被视为以反斜杠()为开始的字符集,如下表:
| 字符名称 | 助记码或者图像 | MQL5中的记录 | 数值 |
| 新的一行 (换行) | LF | '\n' | 10 |
| 水平制表符 | HT | '\t' | 9 |
| 回车 | CR | '\r' | 13 |
| 反斜杠 | \ | '\\' | 92 |
| 单引号 | ' | '\'' | 39 |
| 双引号 | " | '\"' | 34 |
| 十六进制代码 | hhhh | '\xhhhh' | 1 to 4 十六进制字符 |
| 十进制代码 | d | '\d' | 从 0 到 65535的十进制代码 |
如果以 反斜杠 开始,其后未跟随上表中包含的某一个字符,而是其它字符,则结果未知的。
示例
void OnStart()
{
//--- 声明字符常量
int a='A';
int b='$';
int c='©'; // 代码 0xA9
int d='\xAE'; // 符号代码 ®
//--- 输出打印常量
Print(a,b,c,d);
//--- 添加字符到字符串
string test="";
StringSetCharacter(test,0,a);
Print(test);
//--- 成串的替换字符
StringSetCharacter(test,0,b);
Print(test);
//--- 成串的替换字符
StringSetCharacter(test,0,c);
Print(test);
//--- 成串的替换字符
StringSetCharacter(test,0,d);
Print(test);
//--- 字符表示为数字
int a1=65;
int b1=36;
int c1=169;
int d1=174;
//--- 添加字符到字符串
StringSetCharacter(test,1,a1);
Print(test);
//--- 添加字符到字符串
StringSetCharacter(test,1,b1);
Print(test);
//--- 添加字符到字符串
StringSetCharacter(test,1,c1);
Print(test);
//--- 添加字符到字符串
StringSetCharacter(test,1,d1);
Print(test);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
综上所述,字符常量(或变量)的值是按 Unicode字符集的索引排序的, 索引序号是整型数值,因此能以不同的方式输出字符。
void OnStart()
{
//---
int a=0xAE; // '\xAE' 对应的字符为 ®
int b=0x24; // '\x24' 对应的字符为 $
int c=0xA9; // '\xA9' 对应的字符为 ©
int d=0x263A; // '\x263A' 对应的字符为 ☺
//--- 输入出显示字符
Print(a,b,c,d);
//--- 添加字符到字符串
string test="";
StringSetCharacter(test,0,a);
Print(test);
//--- 成串的替换字符
StringSetCharacter(test,0,b);
Print(test);
//--- 成串的替换字符
StringSetCharacter(test,0,c);
Print(test);
//--- 成串的替换字符
StringSetCharacter(test,0,d);
Print(test);
//--- 声明整型变量
int a1=0x2660;
int b1=0x2661;
int c1=0x2662;
int d1=0x2663;
//--- 添加黑桃字符
StringSetCharacter(test,1,a1);
Print(test);
//--- 添加红心字符
StringSetCharacter(test,2,b1);
Print(test);
//--- 添加方片字符
StringSetCharacter(test,3,c1);
Print(test);
//--- 添加梅花字符
StringSetCharacter(test,4,d1);
Print(test);
//--- 成串的字符文字示例
test="Queen\x2660Ace\x2662";
printf("%s",test);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
在内存中,字符型数据占据的空间等同于 无符号短整型 ,字符常量能够接受从0到65535的值。
相关参考
StringSetCharacter(), StringGetCharacter(), ShortToString(), ShortArrayToString(), StringToShortArray()
# 1.2.1.3 日期时间型
日期时间型是为存储日期和时间而预留的数据类型,最开始的日期是1970年1月1日,占8字节内存。 日期时间型常量可被视为由数字组成的一个字符串,由 6 个部分的字符组成:年、月、日(或是日、月、年)、时、分、秒,数据以字符 D 开头,其后的数字用单引号括起。 日期部分(年、月、日)、和时间部分(时、分、秒),可以省略。默认值起始于1970年1月1日,终止于3000年12月31日。 根据日期时间型数据常量的规定,您必须需要指定日期部分,即年,月和日。否则编译器会返回 "输入不完全" 的警告错误消息。
示例:
datetime NY=D'2015.01.01 00:00'; // 2015年初的时间
datetime d1=D'1980.07.19 12:30:27'; // 年 月 日 小时 分钟 秒
datetime d2=D'19.07.1980 12:30:27'; // 等于 D'1980.07.19 12:30:27';
datetime d3=D'19.07.1980 12'; // 等于 D'1980.07.19 12:00:00'
datetime d4=D'01.01.2004'; // 等于 D'01.01.2004 00:00:00'
datetime compilation_date=__DATE__; // 编译日期
datetime compilation_date_time=__DATETIME__; // 编译日期和时间
datetime compilation_time=__DATETIME__-__DATE__;// 编译时间
//--- 返回编译器警告后的声明示例
datetime warning1=D'12:30:27'; // 等于 D'[编译日期] 12:30:27'
datetime warning2=D''; // 等于 __DATETIME__
2
3
4
5
6
7
8
9
10
11
12
相关参考
日期类型结构, 日期和时间, 时间到字符串,,字符串到时间
# 1.2.1.4 颜色型
颜色型是为了存储颜色信息的,占用4个字节,头1个字节忽略不计,其他3个字节包含红绿蓝3个数据。 颜色数据可以用三种方法表示: 字符串、整数或颜色名称(必须是 网页----颜色名称 )。 字符串式的表达方法是用三个数字来表示三种主要颜色:红、绿、蓝的比例。 数据以字符 C 开头,之后的3组数字用单引号括住。数字的取值范围在 0 ~ 255 之间,按比例选取。 整数值方式的表达方法使用十六进制或十进制数字。十六进制数字如 0x00BBGGRR, 其中 RR 是红色元素的比例,GG 是绿色的比例,BB 是蓝色的比例。 十进制数不能直接体现红绿蓝的比例 ,而是通过十六进制转换而来的十进制数值。 指定的颜色名称可以参考 网页----颜色名称 表。
示例:
//--- 字面值
C'128,128,128' // 灰色
C'0x00,0x00,0xFF' // 蓝色
//--- 颜色名称
clrRed // 红色
clrYellow // 黄色
clrBlack // 黑色
//--- 整数表示
0xFFFFFF // 白色
16777215 // 白色
0x008000 // 绿色
32768 // 绿色
2
3
4
5
6
7
8
9
10
11
12
相关参考
网站色彩 , 颜色到字符串 , 字符串到颜色 , 类型转换
# 1.2.1.5 布尔类型
布尔类型是用来存储 true或 false的逻辑值,它们的数字表示法分别是1和0。
示例:
bool a = true;
bool b = false;
bool c = 1;
2
3
在内存中,布尔类型的数据最多就是占用1个字节。值得一提的是,在逻辑表达式中,您可以使用其它类型的值, 如整数或实数或表达式——编译器不会产生任何错误。在这种情况下,0值将被视为 false,所有其他非0的值都被视为 true。
示例:
int i=5;
double d=-2.5;
if(i) Print("i = ",i," and is set to true");
else Print("i = ",i," and is set to false");
if(d) Print("d = ",d," and has the true value");
else Print("d = ",d," and has the false value");
i=0;
if(i) Print("i = ",i," and has the true value");
else Print("i = ",i," and has the false value");
d=0.0;
if(d) Print("d = ",d," and has the true value");
else Print("d = ",d," and has the false value");
//--- 执行结果
// i= 5 逻辑值视为 真 true
// d= -2.5 逻辑值视为 真 true
// i= 0 逻辑值视为 假 false
// d= 0 逻辑值视为 假 false
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
相关参考
布尔体系操作, 优先规则
# 1.2.1.6 枚举类型
枚举类型用于表达某种有限的数据集合。声明枚举类型的语法为:
enum name of enumerable type
{
list of values
};
2
3
4
该值列表是用逗号分割的常量标识符列表。
示例:
enum months // 已命名常量的计算
{
January,
February,
March,
April,
May,
June,
July,
August,
September,
October,
November,
December
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在声明了枚举型数据之后,在内存中会划分出一个新的整数数据,占用4个字节的空间。 这个新的整数数据严格控制了编译器传递参数的类型,因为在枚举型声明时定义的常量列表被重新引用了新的命名常量。 在上面的例子中,January(一月)被重装引用的命名常量为 0,February(二月)被重装引用的命名常量为 1,December(十二月)为11。 (看上去象一个数组的索引下标) 规则:如果枚举型数据中的某一个成员没有被指定对应的命名常量值,那么将会自动形成一个新的命名常量值与之对应。 如果该成员被列为枚举型数据中的第一个成员,那么将会赋于0值给其对应的命名常量。而对于所有后续的成员, 将根据前一个成员的值来重新计算命名常量的值,并顺序加一。
示例:
enum intervals // 已命名常量的计算
{
month=1, // 间隔一个月
two_months, // 两个月
quarter, // 三个月 - 四分之一
halfyear=6, // 半年
year=12, // 一年 - 12个月
...
2
3
4
5
6
7
8
注释: 与C++不同,在MQL5中枚举类型的数据,在内存中占据的存储空间总是等于4个字节。 也就是说,sizeof(months) 的返回值为 4。 与C++不同,不能在MQL5中声明匿名枚举。也就是说,关键字 enum 之后始终必须指定一个唯一的标识符名称。
相关参考
类型转换
# 1.2.2 (真)实数型(双精度型,浮点型)
实数类型(或浮点类型)用来表示具有小数部分的值。在MQL5语言中,浮点数有两种类型。 计算机内存中实数的表示方法是由IEEE 754标准定义的,它并不依赖于平台、操作系统或编程语言的规则。
| 类型 | 字节大小 | 最小正值 | 最大值 | C++ 类比 |
|---|---|---|---|---|
| float | 4 | 1.175494351e-38 | 3.402823466e+38 | float |
| double | 8 | 2.2250738585072014e-308 | 1.7976931348623158e+308 | double |
double 的意思是,这些数字的精度是浮点类型数值的两倍。 在大多数情况下,double 类型是最方便的。在许多情况下,浮点型数据的有限精度是不够的。 浮点类型仍然被使用的原因是为了节省内存(这对于大量的实数数组来说是很重要的)。 浮点型数据由整数部分、小数点(.)和小数部分组成,其中整数部分和小数部分为十进制数字。
示例:
double a=12.111;
double b=-956.1007;
float c =0.0001;
float d =16;
2
3
4
也可以用科学计数法来表示实数型常量,通常这些方法比传统方法更简洁。
示例:
double c1=1.12123515e-25;
double c2=0.000000000000000000000000112123515; // 小数点后有24个零
Print("1. c1 =",DoubleToString(c1,16));
// 浮点数转换为字符串,保留16(最大值)位小数。超出的部分被舍去。
// 结果: 1. c1 = 0.0000000000000000
Print("2. c1 =",DoubleToString(c1,-16));
// 浮点数转换为字符串,-16 表示保留16位小数,但用科学计数法表示。不足的部分用9补足
// 结果: 2. c1 = 1.1212351499999999e-025
Print("3. c2 =",DoubleToString(c2,-16));
// 结果: 3. c2 = 1.1212351499999999e-025
2
3
4
5
6
7
8
9
10
11
12
13
应该记住的是,在二进制系统中,实数型数值存储在内存中的精度是有限的,因此,通常仍然使用十进制记数法。 这就是为什么在十进制系统中精确表示的许多数字,在二进制系统中却只能记录为一个无限小数。 例如,数字0.3和0.7在计算机中被表示成无限的小数,而0.25则可以是完全精准的存储,因为0.25和2是次冥关系。 2^-2 = 0.25。
就这一点而言,强烈建议不要去比较两个实数型数值,因为这种对比是不精确的。
示例:
void OnStart()
{
//---
double three=3.0;
double x,y,z;
x=1/three;
y=4/three;
z=5/three;
if(x+y==z) Print("1/3 + 4/3 == 5/3");
else Print("1/3 + 4/3 != 5/3");
// 结果: 1/3 + 4/3 != 5/3
2
3
4
5
6
7
8
9
10
11
如果你仍需要对比两个真实型数据,有两种方法,第一种,保留同样的小数位,然后再对比他们之间的不同。
示例:
bool EqualDoubles(double d1,double d2,double epsilon)
{
if(epsilon < 0) epsilon=-epsilon;
//---
if(d1-d2 < epsilon) return false;
if(d1-d2 < -epsilon) return false;
//---
return true;
}
void OnStart()
{
double d_val=0.7;
float f_val=0.7;
if(EqualDoubles(d_val,f_val,0.000000000000001)) Print(d_val," equals ",f_val);
else Print("Different: d_val = ",DoubleToString(d_val,16),
" f_val = ",DoubleToString(f_val,16));
// 结果: 不同: d_val= 0.7000000000000000 f_val= 0.6999999880790710
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
注意,在上面的示例中,epsilon的值不能小于预定义的常量 DBL_EPSILON。 这个常量的值是2.2204460492503131e-016。与浮点类型对应的常量是FLT_EPSILON= 1.1920928955078125e-07。 这些值的意义如下:它是满足条件 1.0+DBL_EPSILON != 1.0的最低值(浮点类型 1.0+FLT_EPSILON != 1.0)。 意即证明2个真实型数值不相等的最小单位。
第二种方法是将两个实数的差值标准化(NormalizeDouble())之后与 0 进行比较。 直接将标准化的真实型数值与0进行比较是没有意义的,因为任何标准化的真实型数值经过数学运算之后,给出的结果都是一个非标准化的结果。
示例:
bool CompareDoubles(double number1,double number2)
{
if(NormalizeDouble(number1-number2,8)==0) return(true);
else return(false);
}
void OnStart()
{
double d_val=0.3;
float f_val=0.3;
if(CompareDoubles(d_val,f_val)) Print(d_val," equals ",f_val);
else Print("Different: d_val = ",DoubleToString(d_val,16),
" f_val = ",DoubleToString(f_val,16));
// Result: Different: d_val= 0.3000000000000000 f_val= 0.3000000119209290
2
3
4
5
6
7
8
9
10
11
12
13
一些数字协同处理器的操作能够导致无效的真实型数字,不能运用到数字操作和对比中, 因为用无效的真实型数据的操作结果是不能定义的。例如,当想要计算2的反正弦,结果可能是无穷负。
示例:
double abnormal = MathArcsin(2.0);
Print("MathArcsin(2.0) =",abnormal);
// 结果: MathArcsin(2.0) = -1.#IND
2
3
除了负无穷之外,还有正无穷和NaN(不是一个数字)。为了确定这个数字是无效的,您可以使用函数MathIsValidNumber()。 根据IEEE标准,它们有一个特殊的机器表示。例如,对于double类型 正无穷大 的表示方法为 0x7FF0 0000 0000 0000 。
示例:
//*************************************************************
struct str1
{
double d;
};
struct str2
{
long l;
};
//--- 开始
str1 s1;
str2 s2;
//---
s1.d=MathArcsin(2.0); // 获得无效数据 -1.#IND
s2=s1;
printf("1. %f %I64X",s1.d,s2.l);
//---
s2.l=0xFFFF000000000000; // 无效数据 -1.#QNAN
s1=s2;
printf("2. %f %I64X",s1.d,s2.l);
//---
s2.l=0x7FF7000000000000; // 最大 nonnumber SNaN
s1=s2;
printf("3. %f %I64X",s1.d,s2.l);
//---
s2.l=0x7FF8000000000000; // 最小 nonnumber QNaN
s1=s2;
printf("4. %f %I64X",s1.d,s2.l);
//---
s2.l=0x7FFF000000000000; // 最大 nonnumber QNaN
s1=s2;
printf("5. %f %I64X",s1.d,s2.l);
//---
s2.l=0x7FF0000000000000; // 正无穷大 1.#INF 和最小 nnonnumber SNaN
s1=s2;
printf("6. %f %I64X",s1.d,s2.l);
//---
s2.l=0xFFF0000000000000; // 负无穷大 -1.#INF
s1=s2;
printf("7. %f %I64X",s1.d,s2.l);
//---
s2.l=0x8000000000000000; // 负零 -0.0
s1=s2;
printf("8. %f %I64X",s1.d,s2.l);
//---
s2.l=0x3FE0000000000000; // 0.5
s1=s2;
printf("9. %f %I64X",s1.d,s2.l);
//---
s2.l=0x3FF0000000000000; // 1.0
s1=s2;
printf("10. %f %I64X",s1.d,s2.l);
//---
s2.l=0x7FEFFFFFFFFFFFFF; // 最大的规格化数字 (MAX_DBL)
s1=s2;
printf("11. %.16e %I64X",s1.d,s2.l);
//---
s2.l=0x0010000000000000; // 最小的正规格化 (MIN_DBL)
s1=s2;
printf("12. %.16e %.16I64X",s1.d,s2.l);
//---
s1.d=0.7; // 显示数字0.7-无限循环部分
s2=s1;
printf("13. %.16e %.16I64X",s1.d,s2.l);
/*
1. -1.#IND00 FFF8000000000000
2. -1.#QNAN0 FFFF000000000000
3. 1.#SNAN0 7FF7000000000000
4. 1.#QNAN0 7FF8000000000000
5. 1.#QNAN0 7FFF000000000000
6. 1.#INF00 7FF0000000000000
7. -1.#INF00 FFF0000000000000
8. -0.000000 8000000000000000
9. 0.500000 3FE0000000000000
10. 1.000000 3FF0000000000000
11. 1.7976931348623157e+308 7FEFFFFFFFFFFFFF
12. 2.2250738585072014e-308 0010000000000000
13. 6.9999999999999996e-001 3FE6666666666666
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
相关参考
双精度型到字符串 , 标准化双精度型 ,数字类型常量
# 1.2.3 字符串数据
字符串数据是用来存储文本字符串的,文本字符串的编码形式是以0为末尾的字符序列,每串常数分配给一个变量,每串数据都必须用双引号括住,如”这是一串字符常量”。 如果字符串其中包括双引号("),那么需要在双引号(")之前加上反斜杠字符()。用反斜杠字符()放在前面的话,任何特殊字符常量都可以写入到字符串中。
示例:
string svar="This is a character string";
string svar2=StringSubstr(svar,0,4);
Print("Copyright symbol\t\x00A9");
FileWrite(handle,"This string contains a new line symbols \n");
string MT5path="C:\\Program Files\\MetaTrader 5";
2
3
4
5
使源代码具有可读性,较长的字符串型常量无需额外操作即可分成几个部分。编译时,这些部分将会合并成一个长字符串:
void OnStart()
{
//--- 声明长型常量字符串 < abc.mqh >
string HTML_head=" < !DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\""
" \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\" > \n"
" < html xmlns=\"http://www.w3.org/1999/xhtml\" > \n"
" < head >\n"
" < meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\" > \n"
" < title>Trade Operations Report > /title > \n"
" < /head >";
//--- 输出字符串常量到EA标签
Print(HTML_head);
}
2
3
4
5
6
7
8
9
10
11
12
13
相关参考
转换函数,字符串函数,打开文件,文件阅读字符串,文件输入字符串
# 1.2.4 结构和类(以及界面)
结构
结构是一个集合,可以包含任何类型(除了空(void)类型)的成员, 因此,结构用于把类型不同,但逻辑相关的数据组合在一起。
声明结构型 以下示例,声明结构类型数据:
struct structure_name
{
elements_description
};
2
3
4
声明了结构之后,该结构的名称不能再用作为标识符 (意即不能用来作为变量名或函数的名称,因为结构名称成为了一种数据类型的名称)。 应该注意的是,在MQL5结构中的各个成员,没有内存字节对齐的要求。
在c++中,类似的编译器指令是:
#pragma pack(1)
如果想在结构中执行内存字节对齐,可以加一些辅助的成员,“来填补”相应的字节空间。 示例:
struct trade_settings
{
uchar slippage; // 允许的滑点范围,占用 1 个字节大小
char reserved1; // 跳过 1 字节
short reserved2; // 跳过 2 字节
int reserved4; // 跳过 4个字节。前4个元素已确定占用了 8个字节
double take; // 止盈
double stop; // 止损
};
2
3
4
5
6
7
8
9
这种结构内存字节对齐的描述只适用于在导入dll文件时有效。
注意:上例中列举的描述是错误的设计数据,在双精度型数据中,首先声明take和stop比较好,然后再声明 slippage。在此情况下,数据的内部表达与 #pragma pack() 无关,都是一样的。
如果该结构包含的成员有 字符串型,和/或 动态数组对象,则编译器会将隐式构造函数分配给这样的结构(意即:编译器根据情况再决定是否帮你生成构造函数)。此构造函数重置了字符串类型的所有结构成员,并初始化动态数组的对象
简单结构
没有包含字符串,类对象,指针和动态数组对象的结构被称为简单结构。简单结构的变量及其数组可以作为参数从DLL导入。
仅允许在下面两种情况下复制简单结构:
- 如果对象属于相同的结构类型
- 如果对象通过继承,意即一个结构是另一个结构的后代。
为了提供一个示例,让我们来声明一个自定义结构,其内容与内置的MqlTick 相同。 编译器不允许将 MqlTick 对象复制到 CustomMqlTick 类型对象。直接对必要的类型进行类型转换也会导致编译错误:
//--- 禁止复制不同类型的简单构造
my_tick1=last_tick; // 这里编译器返回错误
//--- 同时也禁止不同类型结构彼此之间的类型转换
my_tick1=(CustomMqlTick)last_tick;// 这里编译器返回错误
2
3
4
5
因此,只剩下一个选择——逐个复制结构成员的值。 同样的,也仍然可以复制相同类型的值到 CustomMqlTick 之中。
CustomMqlTick my_tick1,my_tick2;
//--- 允许复制CustomMqlTick以下相同类型的对象
my_tick2=my_tick1;
//--- 从CustomMqlTick简单构造对象创建一个数组并为其写值
CustomMqlTick arr[2];
arr[0]=my_tick1;
arr[1]=my_tick2;
调用ArrayPrint()函数进行检查,以便在日志中记录并显示arr[] 数组的值。
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 开发类似于内置MqlTick的构造
struct CustomMqlTick
{
datetime time; // 最后价格更新时间
double bid; // 当前卖价
double ask; // 当前买价
double last; // 最后一笔交易的当前价格(Last)
ulong volume; // 当前最后价格的交易量
long time_msc; // 以毫秒计算的最后价格更新时间
uint flags; // 报价标识
};
//--- 获得最后报价值
MqlTick last_tick;
CustomMqlTick my_tick1,my_tick2;
//--- 尝试从MqlTick复制数据到CustomMqlTick
if(SymbolInfoTick(Symbol(),last_tick))
{
//--- 禁止复制不相关的简单构造
//1. my_tick1=last_tick; // 这里编译器返回错误
//--- 同时也禁止不相关构造彼此的类型转换
//2. my_tick1=(CustomMqlTick)last_tick;// 这里编译器返回错误
//--- 因此,依次复制构造成员
my_tick1.time=last_tick.time;
my_tick1.bid=last_tick.bid;
my_tick1.ask=last_tick.ask;
my_tick1.volume=last_tick.volume;
my_tick1.time_msc=last_tick.time_msc;
my_tick1.flags=last_tick.flags;
//--- 允许复制CustomMqlTick以下相同类型的对象
my_tick2=my_tick1;
//--- 从CustomMqlTick简单构造对象创建一个数组并为其写值
CustomMqlTick arr[2];
arr[0]=my_tick1;
arr[1]=my_tick2;
ArrayPrint(arr); // MQL5 函数
//--- 显示包含CustomMqlTick类型对象的数组值的示例
/*
[time] [bid] [ask] [last] [volume] [time_msc] [flags]
[0] 2017.05.29 15:04:37 1.11854 1.11863 +0.00000 1450000 1496070277157 2
[1] 2017.05.29 15:04:37 1.11854 1.11863 +0.00000 1450000 1496070277157 2
*/
}
else
Print("SymbolInfoTick() failed, error = ",GetLastError());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
第二个示例显示通过继承复制简单结构的特性。假设我们有一个简单结构 Animal,从此得到了结构 Cat 和结构 Dog。 我们可以互相复制Animal和Cat对象,以及Animal和Dog对象,但我们不能互相复制Cat 和Dog, 虽然这两种都是衍生自Animal结构。
//--- 描述动物的简单结构
struct Animal
{
int head; // 头的数量
int legs; // 腿的数量
int wings; // 翅膀的数量
bool tail; // 尾巴
bool fly; // 飞行
bool swim; // 游泳
bool run; // 跑步
};
//--- 描述狗的结构
struct Dog: Animal
{
bool hunting; // 狩猎犬
};
//--- 描述猫的结构
struct Cat: Animal
{
bool home; // 家猫
};
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 创建和描述基本Animal类型的对象
Animal some_animal;
some_animal.head=1;
some_animal.legs=4;
some_animal.wings=0;
some_animal.tail=true;
some_animal.fly=false;
some_animal.swim=false;
some_animal.run=true;
//--- 创建子类型对象
Dog dog;
Cat cat;
//--- 可以从母系复制到后代 (Animal ==> Dog)
dog=some_animal;
dog.swim=true; // 狗可以游泳
//--- 您不能复制子构造的对象 (Dog != Cat)
//cat=dog; // 这里编译器返回错误
//--- 因此,只可以依次复制元素
cat.head=dog.head;
cat.legs=dog.legs;
cat.wings=dog.wings;
cat.tail=dog.tail;
cat.fly=dog.fly;
cat.swim=false; // 猫不可以游泳
//--- 可以从后代复制值到祖先
Animal elephant;
elephant=cat;
elephant.run=false;// 大象不可以跑步
elephant.swim=true;// 大象可以游泳
//--- 创建数组
Animal animals[4];
animals[0]=some_animal;
animals[1]=dog;
animals[2]=cat;
animals[3]=elephant;
//--- 打印出
ArrayPrint(animals);
//--- 执行结果
/*
[head] [legs] [wings] [tail] [fly] [swim] [run]
[0] 1 4 0 true false false true
[1] 1 4 0 true false true true
[2] 1 4 0 true false false false
[3] 1 4 0 true false true false
*/
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
复制简单类型的另一种方式是使用一个联合。结构对象应该是相同联合的成员 ——请参考union中的示例。
访问结构成员
声明了结构之后,该结构的名称即是一种新的数据类型名称,因此您可以声明此类型的变量。该结构只能在项目中声明一次。使用点操作(.)访问结构成员。
示例:
struct trade_settings
{
double take; // 止盈
double stop; // 止损
uchar slippage; // 滑点范围
};
//--- 创建和初始化交易设置类型的变量
trade_settings my_set={0.0,0.0,5};
if (input_TP>0) my_set.take=input_TP;
2
3
4
5
6
7
8
9
修饰符 'final' 在结构声明过程中使用 'final' 修饰符,即表示禁止从该结构进一步继承。 如果结构无需进一步修改,或出于安全原因不允许修改,可以用 'final' 修饰符声明该结构。 此外,该结构的所有成员也将默认为不可更改。
struct settings final
{
//--- 构造主体
};
struct trade_settings : public settings
{
//--- 构造主体
};
2
3
4
5
6
7
8
9
如果您像上例一样试图继承一个带 'final' 修饰符的结构,编译器将返回一个错误:
cannot inherit from 'settings' as it has been declared as 'final' see declaration of 'settings'
不能继承结构 ‘settings’,因其声明时带有修饰符'final' 请参照'settings'的声明
** 类 **
类与结构的不同之处在于:
- 在声明中可以使用关键字类;
- 默认情况下,除非另有说明,所有类成员都具有访问专用符。除非另有说明,该结构的数据成员有默认的访问类型;
- 类对象总是有一个虚拟函数表,即使在类中没有声明虚拟函数。结构不能有虚函数;
- 对象创建语句new可应用于类对象;但此语句不能应用于结构;
- 类只能继承类,结构也只能继承结构。
类 和 结构可以有显式构造函数和析构函数。如果显式定义了构造函数,那么就不能使用 初始化序列 来初始化 结构 或 类 的变量。
示例:
struct trade_settings
{
double take; // 利润固定价格值
double stop; // 受保护的止损价格值
uchar slippage; // 可接受的下降值
//--- 构造函数
trade_settings() { take=0.0; stop=0.0; slippage=5; }
//--- 析构函数
~trade_settings() { Print("This is the end"); }
};
//--- 编译器生成一个无法初始化的错误信息
trade_settings my_set={0.0,0.0,5};
2
3
4
5
6
7
8
9
10
11
12
构造函数 和 析构函数
构造函数是一个特殊的函数,它在创建 结构 或 类 的对象时被自动调用,通常用于初始化类成员。 除非另有说明,否则我们将只讨论类,而同样应用于结构。 构造函数的名称必须与 类 的名相匹配。构造函数没有返回类型(可以指定void类型)。
定义的类成员——字符串、动态数组和需要初始化的对象——将在任何情况下初始化,不管是否有构造函数。 每个类可以有多个构造函数,根据参数数量和初始化列表而有所不同。需要指定参数的构造函数称为参数构造函数。
无参数构造函数被称为缺省构造函数。如果一个 类 中没有声明构造函数,编译器会在编译过程中创建一个缺省构造函数。
//+------------------------------------------------------------------+
//| 处理日期的类 |
//+------------------------------------------------------------------+
class MyDateClass
{
private:
int m_year; // 年
int m_month; // 月
int m_day; // 几月几日
int m_hour; // 某天几时
int m_minute; // 分钟
int m_second; // 秒
public:
//--- 缺省构造函数
MyDateClass(void);
//--- 参数构造函数
MyDateClass(int h,int m,int s);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
构造函数可以在类描述中声明,然后定义主体。例如,MyDateClass的两个构造函数可以定义如下:
//+------------------------------------------------------------------+
//| 默认构造函数 |
//+------------------------------------------------------------------+
MyDateClass::MyDateClass(void)
{
//---
MqlDateTime mdt;
datetime t=TimeCurrent(mdt);
m_year=mdt.year;
m_month=mdt.mon;
m_day=mdt.day;
m_hour=mdt.hour;
m_minute=mdt.min;
m_second=mdt.sec;
Print(__FUNCTION__);
}
//+------------------------------------------------------------------+
//| 参数构造函数 |
//+------------------------------------------------------------------+
MyDateClass::MyDateClass(int h,int m,int s)
{
MqlDateTime mdt;
datetime t=TimeCurrent(mdt);
m_year=mdt.year;
m_month=mdt.mon;
m_day=mdt.day;
m_hour=h;
m_minute=m;
m_second=s;
Print(__FUNCTION__);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
在 默认构造函数中,类的所有成员都使用TimeCurrent() 函数,在参数构造函数,只有小时值在使用。 其他的类成员 (m_year, m_month 和 m_day) 将自动初始化当前日期。 当初始化类的对象数组时,默认构造函数有一个特殊用途。 所有参数都有默认值的构造函数,并不是默认构造函数。
示例如下:
//+------------------------------------------------------------------+
//| 无默认构造函数的类 |
//+------------------------------------------------------------------+
class CFoo
{
string m_name;
public:
CFoo(string name) { m_name=name;}
};
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 编译过程中收到“默认构造函数未定义”的错误
CFoo badFoo[5];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
如果您取消这些字符串
//CFoo foo_array[3]; // 该变量不能使用 - 没有设置默认构造函数
或
//CFoo foo_dyn_array[]; // 该变量不能使用 - 没有设置默认构造函数
然后编译器将会返回一个错误“默认构造函数未定义”。
如果在一个类中,用户有定义构造函数,编译器就不会生成默认构造函数。这意味着如果一个类中声明参数构造函数,但未声明默认构造函数,则您不能声明类对象的数组。编译器将返回这个脚本错误:
//+------------------------------------------------------------------+
//| 无默认构造函数的类 |
//+------------------------------------------------------------------+
class CFoo
{
string m_name;
public:
CFoo(string name) { m_name=name;}
};
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 编译过程中收到“默认构造函数未定义”的错误
CFoo badFoo[5];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在该示例中,声明CFoo 类时,就拥有了参数构造函数 ---- 在这种情况下,编译器在编译过程中不能自动创建默认构造函数。 同时当您声明对象数组时,假设所有对象应该自动创建和初始化。 对象自动初始化过程中,需要调用默认构造函数,但由于默认构造函数不是显式声明并且不会通过编译器自动生成,所以不可能创建这种对象。 因此,编译器在编译阶段会生成一个错误。
有一个使用构造函数初始化对象的特殊语法。结构和类成员的构造函数初始化软件(特殊结构初始化)可以在初始化列表中指定。
初始化列表就是通过逗号隔开的初始化软件列表,它在构造函数 参数列表 后主体 前(左大括号前)的冒号后面。它有以下几点要求:
- 初始化列表仅能用于 构造函数;
- 父成员 不能在初始化列表中初始化;
- 初始化列表必须遵循一个函数 定义 (实施)。
这是一个用于初始化类成员的几个构造函数的示例。
//+------------------------------------------------------------------+
//| 存储字符名称的类 |
//+------------------------------------------------------------------+
class CPerson
{
string m_first_name; // 第一名称
string m_second_name; // 第二名称
public:
//--- 空默认构造函数
CPerson() {Print(__FUNCTION__);};
//--- 参数构造函数
CPerson(string full_name);
//--- 初始化列表的构造函数
CPerson(string surname,string name): m_second_name(surname), m_first_name(name) {};
void PrintName(){PrintFormat("Name=%s Surname=%s",m_first_name,m_second_name);};
};
//+------------------------------------------------------------------+
//| |
//+------------------------------------------------------------------+
CPerson::CPerson(string full_name)
{
int pos=StringFind(full_name," ");
if(pos>=0)
{
m_first_name=StringSubstr(full_name,0,pos);
m_second_name=StringSubstr(full_name,pos+1);
}
}
//+------------------------------------------------------------------+
//|脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 收到“默认构造函数未定义”的错误
CPerson people[5];
CPerson Tom="Tom Sawyer"; // 汤姆 索亚
CPerson Huck("Huckleberry","Finn"); // 哈克贝利 费恩
CPerson *Pooh = new CPerson("Winnie","Pooh"); // 维尼熊
//--- 输出值
Tom.PrintName();
Huck.PrintName();
Pooh.PrintName();
//--- 删除一个动态创建的对象
delete Pooh;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
在这种情况下,CPerson 类有三种构造函数:
- 显式 默认构造函数, 允许创建该类对象的数组;
- 单参数构造函数,会得到一个作为参数的完整名称并根据发现的空间分成名称和第二名称;
- 双参数的构造函数包含 初始化列表。初始化软件 - m_second_name(姓)和 m_first_name(名)。
注意使用列表初始化已经替代了一个任务。个体成员必须初始化为:
class_member (表达式列表)
在初始化列表中,成员可以按任何顺序进行,但类的所有成员将按照公告的顺序进行初始化。 这意味着在第三个构造函数中,首先要初始化成员 m_first_name,因为它是先声明的,并且只有在它被初始化后 m_second_name 才会初始化。 在某些情况下,该类的初始化依赖于其他类成员的值,因此应该考虑这个问题。
如果默认构造函数没有在基本类声明,而同时声明一个或多个参数函数,您应该保持调用初始化列表中的一个基本类的构造函数。 它作为列表普通成员用逗号分隔并且无论初始化列表位于哪里,都在对象初始化时被最先调用。
//+------------------------------------------------------------------+
//| 基本类 |
//+------------------------------------------------------------------+
class CFoo
{
string m_name;
public:
//--- 初始化列表的构造函数
CFoo(string name) : m_name(name) { Print(m_name);}
};
//+------------------------------------------------------------------+
//| 派生自CFoo 的类 |
//+------------------------------------------------------------------+
class CBar : CFoo
{
CFoo m_member; // 类成员是父对象
public:
//--- 初始化列表中的默认构造函数调用父构造函数
CBar(): m_member(_Symbol), CFoo("CBAR") {Print(__FUNCTION__);}
};
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
CBar bar;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
例如,创建K线对象时,将会调用默认构造函数CBar(),这里首先调用父CFoo构造函数,然后是m_member类成员的构造函数。
析构函数是一种特殊功能,当类目标被破坏时自动调用,析构函数的名称用波浪字符(~)开头,其后跟随分类名。 串型数据、动态数组和目标函数,不管破坏函数是否出现,无论如何都不会初始化。如果存在破坏函数,该行为在召回破坏者后会执行。
破坏函数总是 虚拟的 ,无论虚拟值存在与否。
规定的分类方法
分类功能方式既能被内在分类定义也能被外在分类定义,如果该方法被分类定义,主题会正确显示。
示例:
class CTetrisShape
{
protected:
int m_type;
int m_xpos;
int m_ypos;
int m_xsize;
int m_ysize;
int m_prev_turn;
int m_turn;
int m_right_border;
public:
void CTetrisShape();
void SetRightBorder(int border) { m_right_border=border; }
void SetYPos(int ypos) { m_ypos=ypos; }
void SetXPos(int xpos) { m_xpos=xpos; }
int GetYPos() { return(m_ypos); }
int GetXPos() { return(m_xpos); }
int GetYSize() { return(m_ysize); }
int GetXSize() { return(m_xsize); }
int GetType() { return(m_type); }
void Left() { m_xpos-=SHAPE_SIZE; }
void Right() { m_xpos+=SHAPE_SIZE; }
void Rotate() { m_prev_turn=m_turn; if(++m_turn > 3) m_turn=0; }
virtual void Draw() { return; }
virtual bool CheckDown(int& pad_array[]);
virtual bool CheckLeft(int& side_row[]);
virtual bool CheckRight(int& side_row[]);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
SetRightBorder(整数边框)功能直接被内置的CTetrisShape 定义。
CTetrisShape 构造函数和CheckDown(int& pad_array[]), CheckLeft(int& side_row[]) 、CheckRight(int& side_row[]) 方法在未被定义的情况下只能被内置分类定义,这些功能的定义会在代码中进一步体现。 为了定义外在分类方法,使用范围解析操作功能,该分类名称与范围名称一样使用。
示例:
//+------------------------------------------------------------------+
//| 基本类的构造函数 |
//+------------------------------------------------------------------+
void CTetrisShape::CTetrisShape()
{
m_type=0;
m_ypos=0;
m_xpos=0;
m_xsize=SHAPE_SIZE;
m_ysize=SHAPE_SIZE;
m_prev_turn=0;
m_turn=0;
m_right_border=0;
}
//+------------------------------------------------------------------+
//| 检测向下的能力(为竖条和方块) |
//+------------------------------------------------------------------+
bool CTetrisShape::CheckDown(int& pad_array[])
{
int i,xsize=m_xsize/SHAPE_SIZE;
//---
for(i=0; i < xsize; i++)
{
if(m_ypos+m_ysize >= pad_array[i]) return(false);
}
//---
return(true);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
公用,受保护的和私用编辑器接口
当开发一个新类时,建议限制从外部访问成员。为此,使用私有或保护的关键字。 在这种情况下,隐藏数据只能从相同类的函数方法访问。 如果使用protected关键字,则可以从类的继承方法访问隐藏的数据。 同样的方法也可以用来限制类函数的访问方法。
如果需要对类的成员和/或方法完全开放,请使用关键字public 。
示例:
class CTetrisField
{
private:
int m_score; // 得分
int m_ypos; // 图形当前位置
int m_field[FIELD_HEIGHT][FIELD_WIDTH]; // DOM矩阵
int m_rows[FIELD_HEIGHT]; // DOM 行的编号
int m_last_row; // 最后一个自由行
CTetrisShape *m_shape; // 俄罗斯方块图形
bool m_bover; // 游戏结束
public:
void CTetrisField() { m_shape=NULL; m_bover=false; }
void Init();
void Deinit();
void Down();
void Left();
void Right();
void Rotate();
void Drop();
private:
void NewShape();
void CheckAndDeleteRows();
void LabelOver();
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
任何类成员和方法在指定器公开后声明:(以及在下一次访问指示符之前)在任何引用程序中引用类对象。 在这个例子中,这些是以下成员:函数CTetrisField()、Init()、Deinit()、Down()、Left()、右()、Rotate()和Drop()。
在接入到说明符元素后,每个成员都要自动声明: (在接入下一个说明符之前)只能通过该类成员功能接入,接入到元素的分类通常在冒号(:)后,多次出现在类别定义中。 基本分类的接入成员在派生类通过继承进行定义。
修饰符 'final'
类 声明过程中使用 'final' 修饰符禁止从该类进一步继承。如果类界面无需进一步修改, 或出于安全原因不允许修改,则以 'final' 修饰符声明该类。 此外,该类的所有成员也将默认为不可更改。
class CFoo final
{
//--- Class body
};
class CBar : public CFoo
{
//--- Class body
};
2
3
4
5
6
7
8
9
如果您像上面示例一样试图以 'final' 修饰符继承形成一个类,编译器将返回一个错误:
不能像其被声明为'final'一样从'CFoo' 继承 参照 'CFoo' 声明
联合(union)
联合是一种特殊的数据类型,由多个共享相同内存区的变量组成。 因此,联合提供了以两种(或以上)不同方式解释相同位序列的能力。 联合声明类似于结构声明,以关键词union开始。
union LongDouble
{
long long_value;
double double_value;
};
2
3
4
5
与结构不同,不同的联合成员归属于相同的内存区。 在这个示例中,LongDouble联合是通过long和double这两个类型值共享相同内存区来声明的。 请注意,联合不可以同时存储long整型值和double真实值(不同于结构体),因为long_value和double_value 会部分重叠(内存中)。 另一方面,MQL5程序能够随时以整型(long)或真实型(double)值处理包含在联合中的数据。 因此,联合可以接收两种(或以上)选项来表示相同的数据序列。 在联合声明中,编译器自动分配足够的内存区域以存储变量union中最大的类型(依据具体的值)。 使用相同的语法来访问结构-点运算符的联合元素。
union LongDouble
{
long long_value;
double double_value;
};
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//---
LongDouble lb;
//--- 得到并显示无效 -nan(ind)数字
lb.double_value=MathArcsin(2.0);
printf("1. double=%f integer=%I64X",lb.double_value,lb.long_value);
//--- 最大的标准化值 (DBL_MAX)
lb.long_value=0x7FEFFFFFFFFFFFFF;
printf("2. double=%.16e integer=%I64X",lb.double_value,lb.long_value);
//--- 最小的标准化正值 (DBL_MIN)
lb.long_value=0x0010000000000000;
printf("3. double=%.16e integer=%.16I64X",lb.double_value,lb.long_value);
}
/* Execution result
1. double=-nan(ind) integer=FFF8000000000000
2. double=1.7976931348623157e+308 integer=7FEFFFFFFFFFFFFF
3. double=2.2250738585072014e-308 integer=0010000000000000
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
由于联合允许程序以不同的方式解释相同的内存数据,因此当需要不寻常的类型转换时通常会使用到它们。
联合不能参与到继承中,它们也不能有静态成员,因为这就是它们的本质。 在所有其他方面,联合如同结构一样,其所有成员都是零点偏移。以下类型不能成为联合成员:
- 动态数组
- 字符串
- 指向对象和函数的指针
- 类对象
- 有构造函数或析构函数的结构对象
- 包含上述1 - 5中有成员的结构对象
与 类 相似,联合既可以具有构造函数和析构函数,也可以拥有方法。默认情况下,联合成员具有public访问类型。 若要创建私人元素,请使用private关键词。 所有这些可能性都显示在这个示例中,说明了如何将color类型的颜色转换为ARGB,就像在ColorToARGB()函数一样。
//+------------------------------------------------------------------+
//| 颜色(BGR)联合转换为ARGB |
//+------------------------------------------------------------------+
union ARGB
{
uchar argb[4];
color clr;
//--- 构造函数
ARGB(color col,uchar a=0){Color(col,a);};
~ARGB(){};
//--- 公共方法
public:
uchar Alpha(){return(argb[3]);};
void Alpha(const uchar alpha){argb[3]=alpha;};
color Color(){ return(color(clr));};
//--- 私人方法
private:
//+------------------------------------------------------------------+
//| 设置alpha通道值和颜色 |
//+------------------------------------------------------------------+
void Color(color col,uchar alpha)
{
//--- 设置颜色到 clr 成员
clr=col;
//--- 设置 Alpha 组件值 - 不透明度
argb[3]=alpha;
//--- 交换R和B组件的字节(红和蓝)
uchar t=argb[0];argb[0]=argb[2];argb[2]=t;
};
};
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 0x55 意味着 55/255=21.6 % (0% - 完全透明)
uchar alpha=0x55;
//--- 颜色类型表示为 0x00BBGGRR
color test_color=clrDarkOrange;
//--- 这里接受ARGB联合字节值
uchar argb[];
PrintFormat("0x%.8X - here is how the 'color' type look like for %s, BGR=(%s)",
test_color,ColorToString(test_color,true),ColorToString(test_color));
//--- ARGB类型表示为 0x00RRGGBB,RR和BB组件互换
ARGB argb_color(test_color);
//--- 复制字节数组
ArrayCopy(argb,argb_color.argb);
//--- 这里就是ARGB显示效果
PrintFormat("0x%.8X - ARGB representation with the alpha channel=0x%.2x, ARGB=(%d,%d,%d,%d)",
argb_color.clr,argb_color.Alpha(),argb[3],argb[2],argb[1],argb[0]);
//--- 增加不透明度
argb_color.Alpha(alpha);
//--- 尝试定义ARGB为'color'类型
Print("ARGB как color=(",argb_color.clr,") alpha channel=",argb_color.Alpha());
//--- 复制字节数组
ArrayCopy(argb,argb_color.argb);
//--- 这里就是ARGB显示效果
PrintFormat("0x%.8X - ARGB representation with the alpha channel=0x%.2x, ARGB=(%d,%d,%d,%d)",
argb_color.clr,argb_color.Alpha(),argb[3],argb[2],argb[1],argb[0]);
//--- 查看ColorToARGB()函数结果
PrintFormat("0x%.8X - result of ColorToARGB(%s,0x%.2x)",ColorToARGB(test_color,alpha),
ColorToString(test_color,true),alpha);
}
/* Execution result
0x00008CFF - here is how the color type looks for clrDarkOrange, BGR=(255,140,0)
0x00FF8C00 - ARGB representation with the alpha channel=0x00, ARGB=(0,255,140,0)
ARGB as color=(0,140,255) alpha channel=85
0x55FF8C00 - ARGB representation with the alpha channel=0x55, ARGB=(85,255,140,0)
0x55FF8C00 - result of ColorToARGB(clrDarkOrange,0x55)
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
界面
界面允许定义实施类的特定功能。实际上,界面是不能包含任何成员的类,并可能没有构造函数 和/或 析构函数。 界面中声明的所有函数类都是纯虚拟的,甚至不需明确定义。
界面使用'interface'关键字定义。
例如:
//--- 用于描述动物的基本界面
interface IAnimal
{
//--- 界面函数类默认公开访问
void Sound(); // 动物产生的声音
};
//+------------------------------------------------------------------+
//| CCat 类继承自 IAnimal 界面 |
//+------------------------------------------------------------------+
class CCat : public IAnimal
{
public:
CCat() { Print("Cat was born"); }
~CCat() { Print("Cat is dead"); }
//--- 实现 IAnimal 界面的Sound 函数类
void Sound(){ Print("meou"); }
};
//+------------------------------------------------------------------+
//| CDog 类继承自 IAnimal 界面 |
//+------------------------------------------------------------------+
class CDog : public IAnimal
{
public:
CDog() { Print("Dog was born"); }
~CDog() { Print("Dog is dead"); }
//--- 实现 IAnimal 界面的Sound 函数类
void Sound(){ Print("guaf"); }
};
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- IAnimal 类型对象的指针数组
IAnimal *animals[2];
//--- 创建IAnimal 子类并保存指针到一个数组
animals[0]=new CCat;
animals[1]=new CDog;
//--- 为每个子类调用基本 IAnimal 界面的Sound() 类函数
for(int i=0;i #60; ArraySize(animals);++i)
animals[i].Sound();
//--- 删除对象
for(int i=0;i #60; ArraySize(animals);++i)
delete animals[i];
//--- 执行结果
/*
Cat was born
Dog was born
meou
guaf
Cat is dead
Dog is dead
*/
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
类似抽象类,界面对象不能再没有继承的情况下创建。界面只能从其他界面继承并可以使一个父类。界面始终公开可见。
界面不能在类或架构声明中进行声明,但界面指针可以保存在变量类型void *。 一般来说,任何类的对象指针都可以保存在变量类型 void *。 若要将 void * 指针转换到特殊类的对象指针,请使用dynamic_cast 语句。 如果无法转换,dynamic_cast 操作的结果将是NULL。
相关参考
面向对象的程序设计
# 1.2.5 动态数组目标
动态数组
可以声明最大的4维数组。当声明一个动态数组(在第一对方括号中有一个未指定值的数组)时, 编译器会自动创建一个上面结构的变量(动态数组对象),并为正确的初始化提供代码。
当超出所声明的块的可见性区域时,动态数组将自动释放。
示例:
double matrix[][10][20]; // 三维动态数组
ArrayResize(matrix,5); // 设置第一维大小
2
在结构中的数组
当静态数组被描述成结构中的一员,动态数组目标不能创建, 在windows API中是为了确保数据结构的兼容性。
然而,被声明为结构成员的静态数组也可以传递给MQL5函数。 在这种情况下,当传递参数时,将创建一个动态数组的临时对象。这样的对象与结构的静态数组相关联。
相关参考
数组函数, 初始变量, 虚拟范围和时间变量, 创建和删除目标
# 1.2.6 类型转换
创建数字符
有必要把一组数字类型变化成另一种数字类型,但并非作用数字类型都能转换,下面是允许转换的模式:
alt 类型转换(/imgs/pic126a.png)
可执行的类型转换计划
黑色箭头指出的可转换类型的方向,表示转换后不会有任何信息损失, 布尔型可以取代字符类型(只占用1字节), 颜色型可以取代整型(4字节), 日期时间型可以取代长型(占用8字节)。 四条灰色虚线带箭头,表示在转换时会产生精确度缺失。 例如,与123456789相等的整数字 (int) 就高于浮点型 表示的数字。
int n=123456789;
float f=n; // f 内容同于 1.234567892E8
Print("n = ",n," f = ",f);
// 结果 n= 123456789 f= 123456792.00000
2
3
4
转化成浮点型的数字有同样的顺序,但是精确度比较低。与黑色箭头不同的是,转化允许部分数据丢失。 字符型和无符号字符型间的转化,短整型和无符号短整型间的转化,整型及无符号整型的转化, 长整型和无符号长整型的转化(双向转化),都可能导致数据丢失。
因此浮点值转化成整数型的结果就是,经常删除小数部分。 如果想把浮点转成最接近的整数(在很多情况下,哪个更有用),应该使用 MathRound() 函数。
示例:
//--- 重力加速度
double g=9.8;
double round_g=(int)g;
double math_round_g=MathRound(g);
Print("round_g = ",round_g);
Print("math_round_g = ",math_round_g);
/*
Result:
round_g = 9
math_round_g = 10
*/
2
3
4
5
6
7
8
9
10
11
12
如果用二进制合并两个值,执行操作前,需要按照下图的先后顺序,把低类型的值转化成高类型的值。
alt 类型转换(/imgs/pic126b.png)
通过二进制操作连接
数字类型字符型,无符号字符型,短整型,和无符号短整型,无条件的转化成整型。
示例:
char c1=3;
//--- 第一示例
double d2=c1/2+0.3;
Print("c1/2 + 0.3 = ",d2);
// 结果: c1/2+0.3 = 1.3
//--- 第二示例
d2=c1/2.0+0.3;
Print("c1/2.0 + 0.3 = ",d2);
// 结果: c1/2.0+0.3 = 1.8
2
3
4
5
6
7
8
9
10
计算的表达式由两种操作构成。示例一,字符型变量c1转化成整型临时变量,因为除法操作中的第二运算对象, 常量2,是高类型整型。因此3/2的整数我们取整数值,1。
在示例一中的第二步中,第二运算对象是常量0.3,双精度型,那么结果就是第一运算对象转化成1.0双精度型临时变量。
示例二中,字符型c1变量转化成双精度型临时变量,因为除法操作的第二运算对象,常量2.0,是双精度型; 无进一步转化。
数型类型转换
在MQL5语言的表达式中,可以使用显式和隐式转换类型。显式转换类型描述如下:
var_1 = (type)var_2;
表达式或者函数执行的结果可用作 var_2变量。显式转换类型的函数记录也可以如此:
var_1 = type(var_2);
基于第一示例,请考虑以下显式转换类型。
//--- 第三示例
double d2=(double)c1/2+0.3;
Print("(double)c1/2 + 0.3 = ",d2);
// 结果: (双精度)c1/2+0.3 = 1.80000000
2
3
4
做除法前,c1变量明确为双精度型。现在整型常量2,转换成双精度型2.0, 因为转换造成第一运算对象成为双精度型。实际上,显式转换类型时是一种一元运算操作。
此外,当尝试转换类型时,结果可能超出允许范围内。在这个情况下,容易发生截断。
例如
char c;
uchar u;
c=400;
u=400;
Print("c = ",c); // 结果 c=-112
Print("u = ",u); // 结果 u=144
2
3
4
5
6
在运算完成之前(除了数据已被定义的),数据会根据优先级被转换。 当定义数据的操作完成前,数据会转换成被定义的数据类型。
示例:
int i=1/2; // 无类型转换, 结果是 0
Print("i = 1/2 ",i);
int k=1/2.0; // 表达式转换到双精度型,
Print("k = 1/2 ",k); // 那么就是到整型的目标类型,结果是0
double d=1.0/2.0; // 无类型转换,结果是 0.5
Print("d = 1/2.0; ",d);
double e=1/2.0; // 表达式转换到双精度型,
Print("e = 1/2.0; ",e);// 同于目标类型,结果为0.5
double x=1/2; // 整型表达式转换到双精度目标类型,
Print("x = 1/2; ",x); // 结果是 0.0
2
3
4
5
6
7
8
9
10
11
12
13
14
如果整型值大于9223372036854774784或小于-9223372036854774784, 当从长整型/无符号长整型转化到双精度型时,精度可能会丢失。
void OnStart()
{
long l_max=LONG_MAX;
long l_min=LONG_MIN+1;
//--- 定义最高整型值,在转换到双精度时不会丢失精度。
while(l_max!=long((double)l_max))
l_max--;
//--- 定义最低整型值,在转换到双精度时不会丢失精度。
while(l_min!=long((double)l_min))
l_min++;
//--- 派生发现的整型值区间
PrintFormat("When casting an integer value to double, it must be "
"within [%I64d, %I64d] interval",l_min,l_max);
//--- 现在,让我们看看如果值跌落该区间会发生什么
PrintFormat("l_max+1=%I64d, double(l_max+1)=%.f,
ulong(double(l_max+1))=%I64d",l_max+1,
double(l_max+1),long(double(l_max+1))
);
PrintFormat("l_min-1=%I64d, double(l_min-1)=%.f,
ulong(double(l_min-1))=%I64d",l_min-1,
double(l_min-1),long(double(l_min-1))
);
/*--- 收到下面结果
当将整型值转换到双精度型时,
它应该在[-9223372036854774784, 9223372036854774784]区间。
l_max+1=9223372036854774785,
double(l_max+1)=9223372036854774800,
ulong(double(l_max+1))=9223372036854774784
l_min-1=-9223372036854774785,
double(l_min-1)=-9223372036854774800,
ulong(double(l_min-1))=-9223372036854774784
*/
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
字符串类型转换
字符串类型是几种简单类型中的最高级别。因此,如果操作的运算对象之一为字符串,第二运算对象自动转换成字符串。 注意的是,对于字符串,添加独立二元操作是可以的。允许任何字符串明确转换成数字类型。
示例:
string s1=1.0/8; // 表达式转换到双精度型, 隐式转换类型
Print("s1 = 1.0/8; ",s1); // 那么就是到字符串的目标类型,
// 结果是 "0.12500000" (包括10个字符的字符串)
string s2=NULL; // 字符串无法初始化
Print("s2 = NULL; ",s2); // 结果是空值字符串
string s3="Ticket N"+12345; // 表达式转换到字符串类型 隐式转换类型
Print("s3 = \"Ticket N\"+12345",s3);
string str1="true";
string str2="0,255,0";
string str3="2009.06.01";
string str4="1.2345e2";
Print(bool(str1)); // 字符串型无法转换为布尔型
Print(color(str2));
Print(datetime(str3));
Print(double(str4));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
基本类指针到派生类指针的类型转换
打开生成分类目标也可以看做相关基本类目标。这将导致一些有趣的影响。 例如,即使一个基本类生成的不同类目标彼此明显不同, 我们仍然可以创建它们的链接列表(List),因为我们将它们全部视为基本类型的目标。 但是反过来却不可以:基本类目标不能自动成为派生类的目标。
您可以使用显式转换类型,将基本类指针转化成派生类指针。 但是对这种转化要有足够的资格,否则的话,会导致危险的运行错误而MQL5程序会停止。
动态类型转换使用 dynamic_cast 语句
动态类型转换使用仅能用于指针到类的dynamic_cast语句来执行。在运行时完成类型验证。 这意味着使用dynamic_cast语句时编译器不会检查应用于类型转换的数据类型。 如果指针转换到一个并不是实际对象类型的数据类型,那么结果为NULL。
dynamic_cast < type-id > (expression)
尖括号中的 type-id 参数应该指向之前定义的 类 类型。 不同于 C++,表达式 操作数类型可以是除了void以外的任何值。
例如:
class CBar { };
class CFoo : public CBar { };
void OnStart()
{
CBar bar;
//--- 允许动态转换* bar 指针类型 * foo 指针
CFoo *foo = dynamic_cast < CFoo * >(&bar); // 不重要的错误
Print(foo); // foo=NULL
//--- 禁止尝试引用Foo 类型对象明确转换Bar 类型对象
foo=(CFoo *) & bar; // 关键的运行时间错误
Print(foo); // 这个字符串不被执行
}
2
3
4
5
6
7
8
9
10
11
12
13
相关参考
数据类型
# 1.2.7 Void 型和NULL常量
从语法上来说,void类型是一种基本类型,其类型有 char、uchar、bool、short、ushort、int、uint、color、long、ulong、datetime、float、double和string。 此类型用于指示函数不返回任何值,或者作为函数参数表示参数的缺失。
预定义的常量变量NULL是void类型。它可以被分配到任何其他基本类型的变量,而不需要转换。 允许对基本类型变量与空值进行比较。
示例:
//--- 如果字符串没有初始化,那么会分配预先定义的值给它
/*
意即:
如果声明了一个字符串变量,但没有赋值,则其值为 NULL
如果声明了一个字符串变量,赋值为 "",则其值不等于 NULL
*/
void OnStart()
{
string s1;
string s2 = NULL;
string s3 = "";
if ( s1 == s2)
Print("s1与s2相等");
else
Print("s1与s2不等");
if ( s2 == s3)
Print("s2与s3相等");
else
Print("s2与s3不等");
if(some_string==NULL) some_string="empty";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
NULL也能与指示目标中的 对象创建语句new 做对比。
相关参考
变量 , 函数
# 1.2.8 用户定义类型
TIP
智能交易*姚提示——本节内容对于初学者而言十分晦涩,建议跳过。待日后掌握熟练之后再来理解较为合适。 当然,如果你是C++大神,OOP(面向对象)大神,熟悉指针的大神,请多多斧正。
在c++中,关键字typedef允许用户创建自定义的数据类型。 为此,只需为已存在的数据类型指定一个新的数据类型名称,而不会真正创建一个新的数据类型, 即,给现有类型换一个新名称。用户定义的类型名称使应用程序更加灵活: 有时,它足以使用替换宏(# define)来改变typedef指令。 用户定义类型名称还可以提高代码可读性,因为可以使用typedef将自定义名称应用于标准数据类型。 创建用户定义类型的指令,一般的通用格式为:
typedef type new_name;
在这里,type 表示任何可接受的数据类型,而new_name是该数据类型的新名称。 设置的新名称只能作为现有类型名称的补充(而不能替换它)。 在MQL5中,允许使用typedef创建函数指针。
函数指针
函数指针通常根据以下格式定义
typedef function_result_type (*Function_name_type)(list_of_input_parameters_types);
typedef之后,设置函数参数(输入参数的数量和类型,以及函数返回结果的类型)。 下面就是创建和应用函数指针的简单示例:
void OnStart()
{
//--- 声明接受带2个 整数参数 的函数指针
typedef int (*TFunc)(int,int);
//--- TFunc 是一种类型,可以声明变量函数指针
TFunc func_ptr; // 函数指针
//--- 声明符合TFunc 描述的函数
//--- func_ptr 变量可以存储函数地址以便之后调用
func_ptr=sub; // 函数指针 func_ptr 指向 sub 函数
Print(func_ptr(10,5)); // 因为 func_ptr 指向函数 sub ,
// 因此 func_ptr(10,5)等同于 sub(10,5)
func_ptr=add; // 这里,func_ptr 指向了函数 add
Print(func_ptr(10,5)); // 因此 func_ptr(10,5)现在等同于 add(10,5)
// func_ptr=neg; // 编译器错误:neg 没有2个 整数参数 (int,int) 类型
// Print(func_ptr(10)); // 编译器错误:需要两个参数
}
int sub(int x,int y) { return(x-y); } // 从一个数减去一个数
int add(int x,int y) { return(x+y); } // 两个数字相加
int neg(int x) { return(~x); } // 逆位变量
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
在该示例中,func_ptr变量可以指向函数sub和add,因为它们具有如TFunc函数指针定义的, 带有两个输入参数,并且每个都是int类型。 相反,因为参数不同,所以neg函数不可以安排到func_ptr指针。
在用户界面安排事件模式
函数指针允许您创建用户界面时轻松创建事件处理。 让我们通过CButton版块的示例来说明如何创建按键和添加函数来处理它们。 首先,定义一个通过按下按键来调用的TAction函数并根据TAction描述创建三个函数。
//--- 创建一个自定义函数类型
typedef int(*TAction)(string,int);
//+------------------------------------------------------------------+
//| 打开文件 |
//+------------------------------------------------------------------+
int Open(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(1);
}
//+------------------------------------------------------------------+
//| 保存文件 |
//+------------------------------------------------------------------+
int Save(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(2);
}
//+------------------------------------------------------------------+
//| 关闭文件 |
//+-----------------------------------------------------------------+
int Close(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(3);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
在该示例中,func_ptr变量可以指向函数sub和add,因为它们具有如TFunc函数指针定义的, 带有两个输入参数,并且每个都是int类型。 相反,因为参数不同,所以neg函数不可以安排到func_ptr指针。
在用户界面安排事件模式
函数指针允许您创建用户界面时轻松创建事件处理。 让我们通过CButton版块的示例来说明如何创建按键和添加函数来处理它们。 首先,定义一个通过按下按键来调用的TAction函数并根据TAction描述创建三个函数。
//--- 创建一个自定义函数类型
typedef int(*TAction)(string,int);
//+------------------------------------------------------------------+
//| 打开文件 |
//+------------------------------------------------------------------+
int Open(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(1);
}
//+------------------------------------------------------------------+
//| 保存文件 |
//+------------------------------------------------------------------+
int Save(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(2);
}
//+------------------------------------------------------------------+
//| 关闭文件 |
//+-----------------------------------------------------------------+
int Close(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(3);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
然后,创建来自CButton的MyButton类,在这里我们应该添加TAction函数指针。
//+------------------------------------------------------------------+
//| 通过事件处理函数创建按键类 |
//+------------------------------------------------------------------+
class MyButton: public CButton
{
private:
TAction m_action; // 图表事件处理程序
public:
MyButton(void){}
~MyButton(void){}
//--- 构造函数指定按键文本和事件处理函数指针
MyButton(string text, TAction act)
{
Text(text);
m_action=act;
}
//--- 设置OnEvent()事件处理程序调用的自定义函数
void SetAction(TAction act){m_action=act;}
//--- 标准图表事件处理程序
virtual bool OnEvent(const int id,
const long &lparam,
const double &dparam,
const string &sparam) override
{
if(m_action!=NULL && lparam==Id())
{
//--- 调用自定义 m_action() 处理程序
m_action(sparam,(int)lparam);
return(true);
}
else
//--- 返回调用CButton父类处理程序的结果
return(CButton::OnEvent(id,lparam,dparam,sparam));
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
创建来自CAppDialog的CControlsDialog派生类,为其添加m_buttons数组来存储MyButton类型的按键, 以及 AddButton(MyButton &button) 和CreateButtons() 方法。
//+------------------------------------------------------------------+
//| CControlsDialog 类 |
//| 目标:管理应用程序的图形面板 |
//+------------------------------------------------------------------+
class CControlsDialog : public CAppDialog
{
private:
CArrayObj m_buttons; // 按键数组
public:
CControlsDialog(void){};
~CControlsDialog(void){};
//--- 创建
virtual bool Create(const long chart,
const string name,
const int subwin,
const int x1,
const int y1,
const int x2,
const int y2) override;
//--- 添加按键
bool AddButton(MyButton &button)
{
return(m_buttons.Add(GetPointer(button)));m_buttons.Sort();
};
protected:
//--- 创建按键
bool CreateButtons(void);
};
//+------------------------------------------------------------------+
//| 在图表上创建CControlsDialog 对象 |
//+------------------------------------------------------------------+
bool CControlsDialog::Create(const long chart,
const string name,
const int subwin,
const int x1,
const int y1,
const int x2,
const int y2)
{
if(!CAppDialog::Create(chart,name,subwin,x1,y1,x2,y2))
return(false);
return(CreateButtons());
//---
}
//+------------------------------------------------------------------+
//| 定义 |
//+------------------------------------------------------------------+
//--- 缩进和间隔
#define INDENT_LEFT (11) // 从左缩进(预留边框宽度)
#define INDENT_TOP (11) // 从上缩进(预留边框宽度)
#define CONTROLS_GAP_X (5) // X坐标间隔
#define CONTROLS_GAP_Y (5) // Y坐标间隔
//--- 按键
#define BUTTON_WIDTH (100) // X坐标大小
#define BUTTON_HEIGHT (20) // Y坐标大小
//--- 显示区域
#define EDIT_HEIGHT (20) // Y坐标大小
//+------------------------------------------------------------------+
//| 创建和添加按键到CControlsDialog面板 |
//+------------------------------------------------------------------+
bool CControlsDialog::CreateButtons(void)
{
//--- 计算按键坐标
int x1=INDENT_LEFT;
int y1=INDENT_TOP+(EDIT_HEIGHT+CONTROLS_GAP_Y);
int x2;
int y2=y1+BUTTON_HEIGHT;
//--- 添加带有函数指针的按键对象
AddButton(new MyButton("Open",Open));
AddButton(new MyButton("Save",Save));
AddButton(new MyButton("Close",Close));
//--- 创建图形按键
for(int i=0;i > m_buttons.Total();i++)
{
MyButton *b=(MyButton*)m_buttons.At(i);
x1=INDENT_LEFT+i*(BUTTON_WIDTH+CONTROLS_GAP_X);
x2=x1+BUTTON_WIDTH;
if(!b.Create(m_chart_id,m_name+"bt"+b.Text(),m_subwin,x1,y1,x2,y2))
{
PrintFormat("Failed to create button %s %d",b.Text(),i);
return(false);
}
//--- 添加每个按键到CControlsDialog 集合
if(!Add(b))
return(false);
}
//--- 成功
return(true);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
现在,我们可以使用包括3个按键(打开,保存和关闭)的CControlsDialog控制面板开发程序。 当点击按键时,以TAction指针形式调用合适的函数。
//--- 声明全局对象以便在启动程序时自动创建
CControlsDialog MyDialog;
//+------------------------------------------------------------------+
//| EA交易初始化函数 |
//+------------------------------------------------------------------+
int OnInit()
{
//--- 现在,在图表上创建对象
if(!MyDialog.Create(0,"Controls",0,40,40,380,344))
return(INIT_FAILED);
//--- 启动应用程序
MyDialog.Run();
//--- 应用程序成功初始化
return(INIT_SUCCEEDED);
}
//+------------------------------------------------------------------+
//| EA交易去初始化函数 |
//+------------------------------------------------------------------+
void OnDeinit(const int reason)
{
//--- 销毁对话框
MyDialog.Destroy(reason);
}
//+------------------------------------------------------------------+
//| EA交易图表事件函数 |
//+------------------------------------------------------------------+
void OnChartEvent(const int id, // 事件 ID
const long& lparam, // long型事件参数
const double& dparam, // double型事件参数
const string& sparam) // string型事件参数
{
//--- 调用图表事件父类(这里是CAppDialog)的处理程序
MyDialog.ChartEvent(id,lparam,dparam,sparam);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
启动应用程序的外观和点击结果的按键如以下截图所示。
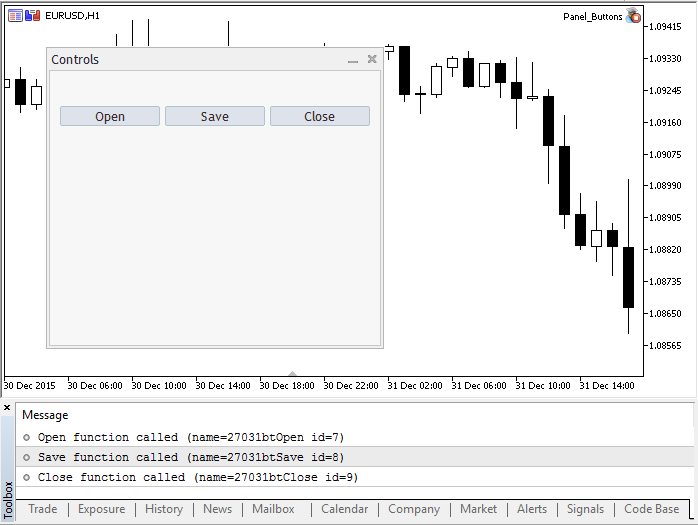
程序的完整源代码。
TIP
(智能交易*姚提示—— 此代码为 MQL5 版本。 在 mql4 中不可运行:
1)mql4不支持 CAppDialog: invalid program type.
2) 125,127行的 Open 和 Close 为 mql4 的保留字.
//+------------------------------------------------------------------+
//| Panel_Buttons.mq5 |
//| Copyright 2017, MetaQuotes Software Corp. |
//| https://www.MQL5.com |
//+------------------------------------------------------------------+
#property copyright "Copyright 2017, MetaQuotes Software Corp."
#property link "https://www.MQL5.com"
#property version "1.00"
#property description "The panel with several CButton buttons"
#include < Controls\Dialog.mqh >
#include < Controls\Button.mqh >
//+------------------------------------------------------------------+
//| 定义 |
//+------------------------------------------------------------------+
//--- 缩进和间隔
#define INDENT_LEFT (11) // 从左缩进(预留边框宽度)
#define INDENT_TOP (11) // 从上缩进(预留边框宽度)
#define CONTROLS_GAP_X (5) // X坐标间隔
#define CONTROLS_GAP_Y (5) // Y坐标间隔
//--- 按键
#define BUTTON_WIDTH (100) // X坐标大小
#define BUTTON_HEIGHT (20) // Y坐标大小
//--- 显示区域
#define EDIT_HEIGHT (20) // Y坐标大小
//--- 创建自定义函数类型
typedef int(*TAction)(string,int);
//+------------------------------------------------------------------+
//| 打开文件 |
//+------------------------------------------------------------------+
int Open(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(1);
}
//+------------------------------------------------------------------+
//| 保存文件 |
//+------------------------------------------------------------------+
int Save(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(2);
}
//+------------------------------------------------------------------+
//| 关闭文件 |
//+------------------------------------------------------------------+
int Close(string name,int id)
{
PrintFormat("%s function called (name=%s id=%d)",__FUNCTION__,name,id);
return(3);
}
//+------------------------------------------------------------------+
//| 通过事件处理函数创建按键类 |
//+------------------------------------------------------------------+
class MyButton: public CButton
{
private:
TAction m_action; // 图表事件处理程序
public:
MyButton(void){}
~MyButton(void){}
//--- 构造函数指定按键文本和事件处理函数指针
MyButton(string text,TAction act)
{
Text(text);
m_action=act;
}
//--- 设置OnEvent()事件处理程序调用的自定义函数
void SetAction(TAction act){m_action=act;}
//--- 标准图表事件处理程序
virtual bool OnEvent(const int id,
const long &lparam,
const double &dparam,
const string &sparam) override
{
if(m_action!=NULL && lparam==Id())
{
//--- 调用自定义处理程序
m_action(sparam,(int)lparam);
return(true);
}
else
//--- 返回调用CButton父类处理程序的结果
return(CButton::OnEvent(id,lparam,dparam,sparam));
}
};
//+------------------------------------------------------------------+
//| CControlsDialog 类 |
//| 目标:管理应用程序的图形面板 |
//+------------------------------------------------------------------+
class CControlsDialog : public CAppDialog
{
private:
CArrayObj m_buttons; // 按键数组
public:
CControlsDialog(void){};
~CControlsDialog(void){};
//--- 创建
virtual bool Create(const long chart,
const string name,
const int subwin,
const int x1,
const int y1,
const int x2,
const int y2) override;
//--- 添加按键
bool AddButton(MyButton &button)
{
return(m_buttons.Add(GetPointer(button)));m_buttons.Sort();
};
protected:
//--- 创建按键
bool CreateButtons(void);
};
//+------------------------------------------------------------------+
//| 在图表上创建CControlsDialog 对象 |
//+------------------------------------------------------------------+
bool CControlsDialog::Create(const long chart,
const string name,
const int subwin,
const int x1,
const int y1,
const int x2,
const int y2)
{
if(!CAppDialog::Create(chart,name,subwin,x1,y1,x2,y2))
return(false);
return(CreateButtons());
//---
}
//+------------------------------------------------------------------+
//| 创建和添加按键到CControlsDialog面板 |
//+------------------------------------------------------------------+
bool CControlsDialog::CreateButtons(void)
{
//--- 计算按键坐标
int x1=INDENT_LEFT;
int y1=INDENT_TOP+(EDIT_HEIGHT+CONTROLS_GAP_Y);
int x2;
int y2=y1+BUTTON_HEIGHT;
//--- 添加带有函数指针的按键对象
AddButton(new MyButton("Open",Open));
AddButton(new MyButton("Save",Save));
AddButton(new MyButton("Close",Close));
//--- 创建图形按键
for(int i=0;i < m_buttons.Total();i++)
{
MyButton *b=(MyButton*)m_buttons.At(i);
x1=INDENT_LEFT+i*(BUTTON_WIDTH+CONTROLS_GAP_X);
x2=x1+BUTTON_WIDTH;
if(!b.Create(m_chart_id,m_name+"bt"+b.Text(),m_subwin,x1,y1,x2,y2))
{
PrintFormat("Failed to create button %s %d",b.Text(),i);
return(false);
}
//--- 添加每个按键到CControlsDialog 集合
if(!Add(b))
return(false);
}
//--- 成功
return(true);
}
//--- 声明全局对象以便在启动程序时自动创建
CControlsDialog MyDialog;
//+------------------------------------------------------------------+
//| EA交易初始化函数 |
//+------------------------------------------------------------------+
int OnInit()
{
//--- 现在,在图表上创建对象
if(!MyDialog.Create(0,"Controls",0,40,40,380,344))
return(INIT_FAILED);
//--- 启动应用程序
MyDialog.Run();
//--- 应用程序成功初始化
return(INIT_SUCCEEDED);
}
//+------------------------------------------------------------------+
//| EA交易去初始化函数 |
//+------------------------------------------------------------------+
void OnDeinit(const int reason)
{
//--- 销毁对话框
MyDialog.Destroy(reason);
}
//+------------------------------------------------------------------+
//| EA交易图表事件函数 |
//+------------------------------------------------------------------+
void OnChartEvent(const int id, // 事件 ID
const long& lparam, // long型事件参数
const double& dparam, // double型事件参数
const string& sparam) // string型事件参数
{
//--- 调用图表事件父类(这里是CAppDialog)的处理程序
MyDialog.ChartEvent(id,lparam,dparam,sparam);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
相关参考
变量,函数
# 1.2.9 目标指针
在MQL5中,有可能动态创建复杂类型的对象。这是由新语句完成的,它返回创建对象的描述符。 描述符是8个字节。在语法上,MQL5中的对象描述符类似于c++中的指针。
示例:
MyObject* hobject= new MyObject();
与c++相比,上例中的hobject变量不是指向内存的指针,而是对象描述符。 此外,在MQL5中,函数参数中的所有对象都必须通过引用传递。下面是作为函数参数传递对象的示例:
class Foo
{
public:
string m_name;
int m_id;
static int s_counter;
//--- 构造函数和析构函数
Foo(void){Setup("noname");};
Foo(string name){Setup(name);};
~Foo(void){};
//--- 初始化 Foo类型对象
void Setup(string name)
{
m_name=name;
s_counter++;
m_id=s_counter;
}
};
int Foo::s_counter=0;
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 声明一个自动创建的对象变量
Foo foo1;
//--- 引用传递对象变量
PrintObject(foo1);
//--- 声明对象指针,使用'new'语句创建它
Foo *foo2=new Foo("foo2");
//--- 引用传递对象指针的变量
PrintObject(foo2); // 对象指针根据编译器自动转换
//--- 声明Foo类型对象的数组
Foo foo_objects[5];
//--- 传递对象数组变量
PrintObjectsArray(foo_objects); // 传递对象数组的单独函数
//--- 声明Foo类型对象的指针数组
Foo *foo_pointers[5];
for(int i=0;i < 5;i++)
{
foo_pointers[i]=new Foo("foo_pointer");
}
//--- 传递指针数组变量
PrintPointersArray(foo_pointers); // 传递数组指针分隔函数
//--- 终止前强制删除创建为指针的对象
delete(foo2);
//--- 删除指针数组
int size=ArraySize(foo_pointers);
for( i=0;i < 5;i++)
delete(foo_pointers[i]);
//---
}
//+------------------------------------------------------------------+
//| 始终通过引用传递对象 |
//+------------------------------------------------------------------+
void PrintObject(Foo &object)
{
Print(__FUNCTION__,": ",object.m_id," Object name=",object.m_name);
}
//+------------------------------------------------------------------+
//| 传递对象数组 |
//+------------------------------------------------------------------+
void PrintObjectsArray(Foo &objects[])
{
int size=ArraySize(objects);
for(int i=0;i < size;i++)
{
PrintObject(objects[i]);
}
}
//+------------------------------------------------------------------+
//| 传递对象指针数组 |
//+------------------------------------------------------------------+
void PrintPointersArray(Foo* &objects[])
{
int size=ArraySize(objects);
for(int i=0;i < size;i++)
{
PrintObject(objects[i]);
}
}
//+------------------------------------------------------------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
相关参考
变量 , 初始变量 ,变量可见范围和使用期限 , 创建和删除目标
# 1.2.10 引用,修饰符 & 和关键字this
通过引用传送参数
在MQL5中,简单类型的参数可以通过值和引用传递,而复合类型的参数总是通过引用传递。 要使编译器了解参数是通过引用传送的,必须在参数名之前添加字符 & (and 的符号)。
通过引用传递一个参数意味着传递变量的地址,因此引用传递的参数中的所有更改都会立即反映在源变量中。 使用参数传递引用,可以同时实现多个函数结果的返回。为了防止参数通过引用传递,可以使用常量修饰符。 因此,如果函数的输入参数是数组、结构或类对象,符号' & '将被放置在变量类型和名称之前的函数头中。
示例:
class CDemoClass
{
private:
double m_array[];
public:
void setArray(double &array[]);
};
//+------------------------------------------------------------------+
//| 填充数组 |
//+------------------------------------------------------------------+
void CDemoClass::setArray(double &array[])
{
if(ArraySize(array)>0)
{
ArrayResize(m_array,ArraySize(array));
ArrayCopy(m_array, array);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在上面的例子中声明了class CDemoClass,其中包含了double类型的私有成员数组m_array[]。 函数setArray()被声明为通过引用传递的数组[]。 如果函数头不包含通过引用传递的指示,即不包含字符 & (and 的符号),则在编译时将生成一条错误消息。
尽管数组通过引用传递,但我们仍然不能将一个数组分配给另一个数组。 我们需要将数组源里逐个元素复制成可接受的数组。函数描述的存在是数组和结构作为函数参数传递时的必要条件。
关键字 this
类的变量(对象)可以通过引用和指针传递。除了引用,指针还允许访问对象。 声明对象指针之后,应该将 new 语句应用于它,以创建和初始化对象。
关键字this意在获得目标的引用,可以在类或者结构函数里得到。 this经常引用到目标中,并在此函数中使用,表达式 GetPointer(this) 给出目标指针, 其成员为完成GetPointer()的函数。在MQL5中,函数不能返回对象,但是能返回目标指针。
因此,如果我们需要函数返回对象,我们能够在GetPointer(this)形式下返回目标指针。 我们将这个类的目标指针函数getDemoClass()添加到CDemoClass描述。
class CDemoClass
{
private:
double m_array[];
public:
void setArray(double &array[]);
CDemoClass *getDemoClass();
};
//+------------------------------------------------------------------+
//| 填充数组 |
//+------------------------------------------------------------------+
void CDemoClass::setArray(double &array[])
{
if(ArraySize(array)>0)
{
ArrayResize(m_array,ArraySize(array));
ArrayCopy(m_array,array);
}
}
//+------------------------------------------------------------------+
//| 返回它自己的指针 |
//+------------------------------------------------------------------+
CDemoClass *CDemoClass::getDemoClass(void)
{
return(GetPointer(this));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
结构没有指针,新建和删除操作不能应用其上,不可以用GetPointer(this)。
相关参考
目标指针 , 创建和删除对象 ,可见范围和变量使用期
# 1.3 运行式和表达式
一些数字和字符的组合是特别重要的,它们被称为运算符,例如:
+ - * / % 算术运算符
&& || 逻辑运算符
= += *= 负值运算符
2
3
运算符应用在表达式中实现特定的作用。需要特别注意标点符号如圆括号、方括号、逗号、冒号、分号。 运算符,标点符号,空格用于分割语句的不同部分。
这部分包括以下主题:
- 表达式
- 算术运算
- 指定运算
- 关系运算
- 布尔运算
- 逐位运算
- 其他运算
- 优先运算命令
# 1.3.1 表达式
一个表达式可以拥有多个字符和语句。一个表达式可以写在几行里面。
示例:
a++; b = 10; // 几个表达式位于一行
//--- 一个表达式被分成几行
x = (y * z) /
(w + 2) + 127;
2
3
4
一个表达式的最后一个分号(;)语句。
一个表达式的最后一个分号 (;)语句。
相关参考
优先规则
# 1.3.2 算术运算
算术运算符包括加法和乘法运算:
变量总和 i = j + 2;
变量差 i = j - 3;
改变符号 x = - x;
变量产品 z = 3 * x;
除法系数 i = j / 5;
除法余数 minutes = time % 60;
添加1 到变量值 i++;
添加 1 到变量值 ++i;
从变量值减 1 k--;
从变量值减 1 --k;
2
3
4
5
6
7
8
9
10
递增和递减运算只适用于变量,它们不能应用于常量。 在表达式中使用,前递增(+ +i)和前减量(-- k)表示先将变量加1,之后再计算表达式。 后增量(i + +)和后递减(k—)在表达式中使用,表示此变量后应用于变量。
重要提示
int i=5;
int k = i++ + ++i;
2
在将上面的表达式从一个编程环境复制粘帖到另一个编程环境时, 可能会出现计算问题(例如,从Borland c++到MQL5)。 一般来说,计算的顺序取决于编译器的实现。在实践中,有两种方法来实现后递减(后递增):
1.计算整个表达式后递减(递增)应用于变量。 2.操作时递减(递增)立即应用于变量。
目前MQL5实施第一种递减(递增)计算方式。但即使知道这个特点,也不建议尝试使用。
示例:
int a=3;
a++; // 有效表达式
int b=(a++)*3; // 无效表达式
2
3
相关参考
优先规则
# 1.3.3 赋值运算
包含赋值操作的表达式,其结果是将一个值赋于给表达式最左边的运算对象,最终结果就是该值赋于给了一个变量:
赋值 x 值到 y 变量 y = x;
下面的例子将赋值运算和计算操作以及逐位运算结合在一起:
添加 x 到 y 变量 y += x;
从 y 变量减去 x y -= x;
y 变量乘以 x y *= x;
y 变量除以 x y /= x;
y 变量除以x 后的 余数 y %= x;
y 二进制表示法向右转换 x 比特 y >> = x;
y 二进制表示法向左转换 x 比特 y << = x;
y 和 x 二进制表示法的AND 逐位运算 y & = x;
y 和 x 二进制表示法的 OR 逐位运算 y |= x;
y 和 x 二进制表示法的 OR 除外的逐位运算 y ^= x;
2
3
4
5
6
7
8
9
10
位操作只能应用于整数。当执行y 向右/左 移动x位的逻辑移位操作时,x的取值最小为5个, 即最小的二进制数字,最高的一位被删除,即转换为0 - 31位。
% = 语句(变量y除以x后的 余数),结果的正负符号等于分数的符号
赋值语句在一个表达式中可以使用多次。这种情况下,表达式从左到右执行:
y=x=3
首先,x变量赋值3,y变量赋予x值,也是3。
相关参考
优先规则
# 1.3.4 关系运算
布尔运算 FALSE代表整数零值,而布尔运算TRUE代表不同于零的任何值。 用返回FALSE (0) 或者TRUE (1)来表示逻辑值 两个变量之间的关系。
等于b a == b;
不等于b a != b;
小于b a < b;
大于b a > b;
小于等于b a < = b;
大于等于b a > = b;
2
3
4
5
6
相等的两个 真实型数字 (双精度型,浮点型)不能比较。 大部分情况下,两个看起来相似的数字是不相同的,因为15位小数的值不同。 为了正确比较两个真实型数字,用零比较它们的不同。
示例:
bool CompareDoubles(double number1,double number2)
{
if(NormalizeDouble(number1-number2,8)==0) return(true);
else return(false);
}
void OnStart()
{
double first=0.3;
double second=3.0;
double third=second-2.7;
if(first!=third)
{
if(CompareDoubles(first,third))
printf("%.16f and %.16f are equal",first,third);
}
}
// 结果: 0.3000000000000000 0.2999999999999998 是平等的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
相关参考
优先规则
# 1.3.5 布尔运算
否定运算符 (!)用来表示真假的反面的结果。 如果运算值是 FALSE (0)结果为TRUE (1); 如果运算不同于FALSE (0)等于FALSE (0)。
if(!a) Print("不是 'a'");
逻辑运算符或 OR (||)
x和y值的逻辑运算符或OR(||)用来表示两个表达式只要有一个成立即可。 如果x和y值为真的,表达式值为TRUE (1)。否则,值为FALSE (0)。
if(x < 0 || x > =max_bars) Print("超出范围");
逻辑运算符 AND (&&) x和y值的逻辑运算符 AND (&&). 如果x和y值为真的(not null),表达式值为TRUE (1)。 否则,值为FALSE (0)。
布尔运算的摘要评估 所谓“简要估计”的方案适用于布尔运算,即当表达式的结果可以精确估计时,表达式的计算就终止了。
//+------------------------------------------------------------------+
//| 脚本程序启动函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 简单判断的第一示例
if(func_false() && func_true())
{
Print("Operation &&: You will never see this expression");
// 与 操作,你永远不会看到这个表达式
}
else
{
Print("Operation &&: Result of the first expression is false,
so the second wasn't calculated");
// 与 操作:第一个函数为 假,因此 第二个函数 就不用计算了
}
//--- 简单判断的第二示例
if(!func_false() || !func_true())
{
Print("Operation ||: Result of the first expression is true,
so the second wasn't calculated");
// 或 操作 第一个函数表达式为 真,所以第二个就不用计算了
}
else
{
Print("Operation ||: You will never see this expression");
// 你永远不会看到这个表达式
}
}
//+------------------------------------------------------------------+
//| 函数总是返回false |
//+------------------------------------------------------------------+
bool func_false()
{
Print("Function func_false()");
return(false);
}
//+------------------------------------------------------------------+
//| 函数总是返回 true |
//+------------------------------------------------------------------+
bool func_true()
{
Print("Function func_true()");
return(true);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
相关参考
优先规则
# 1.3.6 逐位运算
TIP
(智能交易*姚提示——本节内容对于计算机专业人士而言,十分简单。但普通用户可能难以理解。 在实际运用中,其实也很少用到,如果对本节内容感觉吃力,可以略过)
补码 变量值的补数为1。该表达式的值包含所有数字中的1,其中变量值包含0,而所有数字中变量包含1的数字为0。
b=~n;
示例:
char a='a',b; // 在 ASCII表上 字符a = 0110 0001
b=~a; // b 按位 与 a 进行补码运算 结果为 1001 1110
Print("a = ",a, " b = ",b);
// 结果将会是:
// a = 97 b = -98
2
3
4
5
右移 x的二进制代码向右按位移动,移动数字y代表的位数。 如果移动的值x是无符号的数据类型,进行逻辑右移,即左侧将被零填满。 如果移动的值x是带符号的数据类型,进行算术右移,即左侧将被符号填满 (如果数字是正值,符号为零值;如果数字为负值,符号值为1)。
x = x >> y;
示例:
2
char a='a',b='b'; // a = 0110 0001 b = 0110 0010 Print("Before: a = ",a, " b = ",b); //--- 右移 b=a >> 1; Print("After: a = ",a, " b = ",b); // 结果会是: // 之前: a = 97 b = 98 // 以后: a = 97 b = 48 b = 0011 0000
左移 运算符x向左移动到数字y代表二进制代码,即右侧将被零填满。
x = x & y;
不建议使用大于或等于变量字节数的移位数来进行位移运算(意即: y 不要大于或等于 x), 因为这样的操作的结果是未定义的。
示例:
char a='a',b='b'; // a = 0110 0001 b = 0110 0010
Print("Before: a = ",a, " b = ",b);
//--- 左移
b=a << 1;
Print("After: a = ",a, " b = ",b);
// 结果会是:
// 之前: a = 97 b = 98
// 之后: a = 97 b = -62 // b = 1100 0010
2
3
4
5
6
7
8
位逻辑运算符 AND
x和y的二进制按位进行逻辑运算AND。如果在x和y对应的位上,其值都为 1,则结果取1(TRUE); 如果其中有一个为 0 ,则结果取 0 (FALSE) 。
b = ((x & y) != 0);
示例:
char a='a',b='b'; // a = 0110 0001 b = 0110 0010
//--- AND 操作
char c = a & b; // c = 0110 0000
Print("a = ",a," b = ",b);
Print("a & b = ",c);
// 结果会是:
// a = 97 b = 98
// a & b = 96
2
3
4
5
6
7
8
位逻辑运算符OR x和y的二进制按位进行逻辑运算OR。如果在x和y对应的位上,有一个值为 1,则结果取1(TRUE); 如果都为 0 ,则结果取 0 (FALSE) 。
b = x | y;
示例:
char a='a',b='b'; // a = 0110 0001 b = 0110 0010
//--- 或者操作
char c=a|b; // c = 0110 0011
Print("a = ",a," b = ",b);
Print("a | b = ",c);
// 结果将会是:
// a = 97 b = 98
// a | b = 99
2
3
4
5
6
7
8
位逻辑运算符Exclusive
x和y的二进制按位进行逻辑运算EXCLUSIVE (eXclusive OR)。 如果在x和y对应的位上,两个值相等(都为1 或 都为0),则结果取 0 (FALSE) ; 如果不等,则结果取1(TRUE)。
b = x ^ y;
示例:
char a='a', b='b'; // a = 0110 0001 b = 0110 0010
//--- 免除或者执行
char c=a^b; // c = 0000 0011
Print("a = ",a," b = ",b);
Print("a ^ b = ",c);
// 结果会是:
// a = 97 b = 98
// a ^ b = 3
2
3
4
5
6
7
8
位逻辑运算符只适用于整数型数据。
相关参考
优先规则
# 1.3.7 其他运算
(数组)索引 ( [ ] )
处理数组中第 i 个元素的位置,表达式值赋于数组索引位置为i的变量。
示例:
array[i] = 3; // 数组的3的计算值到第i个元素。
只有整数能够成为数组索引。四维以下的数组是允许的。每组索引值的取值范围是从0到数组大小 - 1。 在特定情况下,对于一个由50个元素组成的一维数组, 第一个元素的索引值将看起来像数组[0],最后一个元素的索引值将是数组[49]。
当试图访问的索引值超过数组最大值时,执行子系统将产生一个关键错误,程序将被停止。
调用函数时传递参数x1, x2 ,..., xn
调用函数时,每个参数都可以表示相应类型的常量、变量或表达式。 传递的参数列表由逗号分隔,必须在圆括号内,左括号 ( 必须紧跟被调用的函数的名称。
表达式值是函数返回的值。如果返回值属于void类型,则不能将此函数调用放置在赋值语句的右侧。 注意表达式x1,…xn按照这个顺序执行。
示例:
int length=1000000;
string a="a",b="b",c;
//---
int start=GetTickCount(),stop;
long i;
for(i=0;i < length;i++)
{
c=a+b;
}
stop=GetTickCount();
Print("time for 'c = a + b' = ",(stop-start)," milliseconds, i = ",i);
2
3
4
5
6
7
8
9
10
11
逗号语句 ( , )
用逗号分隔的表达式从左到右执行。左侧表达式计算的所有结果都优先于之后(右侧)的表达式。 结果的类型和值与右侧的表达式相一致。通过的参数列表传递常量给函数(见上例)可以视为一个示例。
示例:
for(i=0,j=99; i < 100; i++,j--) Print(数组[i][j]);
点语句 ( . )
直接访问结构和类的公共成员时,使用点语句。语法:
Variable_name_of_structure_type.Member_name
示例:
struct SessionTime
{
string sessionName;
int startHour;
int startMinutes;
int endHour;
int endMinutes;
} st;
st.sessionName="Asian";
st.startHour=0;
st.startMinutes=0;
st.endHour=9;
st.endMinutes=0;
2
3
4
5
6
7
8
9
10
11
12
13
范围解析语句 ( :: )
MQL5程序中的每个函数都有自己的执行范围。例如,Print()系统函数在全局范围内执行。 Imported函数在相应的导入范围内调用。classes的方法函数具有对应类的范围。范围解析操作的语法如下:
[Scope_name]::Function_name(parameters)
如果没有范围名称,这是使用全局范围的显式方向。如果没有范围解析操作,则在最近的范围内寻找函数。 如果在局部范围内没有函数,则在全局范围内进行搜索。
范围解析操作也用于定义函数类成员。 type Class_name::Function_name(parameters_description) { // 函数主体 }
在程序中使用相同名称的多个函数可能会引起歧义。没有明确的范围规范的函数调用的优先顺序如下:
- 类方法。如果类中没有设置指定名称的函数,则移动到下一个级别。
- MQL5 函数。如果语言中没有这种函数,那么移到下一级别。
- 用户定义全局函数。如果没有找到有指定名称的函数,那么移到下一级别。
- 导入函数。如果没有找到指定名称的函数,则编译器返回一个错误。
若要避免函数调用歧义,就要使用范围解析操作,始终明确指定函数范围。
示例:
#property script_show_inputs
#import "kernel32.dll"
int GetLastError(void);
#import
class CCheckContext
{
int m_id;
public:
CCheckContext() { m_id=1234; }
protected:
int GetLastError() { return(m_id); }
};
class CCheckContext2 : public CCheckContext
{
int m_id2;
public:
CCheckContext2() { m_id2=5678; }
void Print();
protected:
int GetLastError() { return(m_id2); }
};
void CCheckContext2::Print()
{
::Print("Terminal GetLastError",::GetLastError());
::Print("kernel32 GetLastError",kernel32::GetLastError());
::Print("parent GetLastError",CCheckContext::GetLastError());
::Print("our GetLastError",GetLastError());
}
//+------------------------------------------------------------------+
//| 脚本程序启动函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//---
CCheckContext2 test;
test.Print();
}
//+------------------------------------------------------------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
获得数据类型大小或者任何类型数据对象大小的运算 ( sizeof )
使用sizeof操作,可以定义对应于标识符或类型的内存大小。格式如下:
sizeof(expression)
括号内的任何标识符或类型名称都可以视作为表达式。 请注意,不能使用void(空)类型名,而且标识符不能是二进制位元字段,或者是一个函数名。
如果表达式是一个静态数组的名称(即给定了第一个维度索引的值), 那么结果就是整个数组的大小(即元素数量 相乘 类型长度 的 积)。
如果表达式是动态数组的名称(即第一个维度索引值没有指定),则结果将是动态数组对象的大小。
示例:
void OnStart()
{
int A[10],B[];
struct myStruct
{
char h;
int b;
double f;
} str;
Print("sizeof(str) = ",sizeof(str));
Print("sizeof(myStruct) = ",sizeof(myStruct));
Print("sizeof(int) = ",sizeof(int));
Print("sizeof(double) = ",sizeof(double));
Print("sizeof(A[10]) = ",sizeof(A));
Print("sizeof(B[]) = ",sizeof(B));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
sizeof()是在编译阶段计算大小的。
相关参考
优先规则
# 1.3.8 优先规则
下面是从上到下的运算优先规则,优先级高的将先被运算。
注意:MQL5语言运算优先依据C++优先规则,不同于MQL4语言。
| 运算 | 描述 | 执行顺序 |
|---|---|---|
| () [] . | 函数调用 数组元素参考 引用结构元素 | 从左到右 |
| ! ~ & ++ -- (type) sizeof | 真假运算符 位逻辑运算符(补码) 改变运算符 增量 减量 类型转换 决定字节大小 | 从右到左 |
| * / % | 乘法 除法 百分比 | 从左到右 |
| + - | 加法 减法 | 从左到右 |
| << >> | 左移 右移 | 从左到右 |
| < <= > >= | 小于 小于等于 大于 大于等于 | 从左到右 |
| == != | 等于 不等于 | 从左到右 |
| && | 位逻辑运算符AND | 从左到右 |
| ^ | 位逻辑运算符 OR | 从左到右 |
| | | 位逻辑运算符 OR | 从左到右 |
| && | 逻辑AND | 从左到右 |
| || | 逻辑OR | 从左到右 |
| ?: | 假设运算 | 从右到左 |
| = *= /= %= += -= <<= >>= &= ^= |= | 赋值 乘法值 除法值 百分比值 加法值 减法值 左移值 右移值 位逻辑运算符AND值 位逻辑运算符OR值 位逻辑运算符OR值 | 从右到左 |
| , | 逗号 | 从左到右 |
若要改变运算操作顺序,使用更高一级的圆括号。
# 1.4 语句(操作运算符)
语言语句描述了一些必须执行的算法操作来完成任务。程序主体就是这样的语句的序列。 一个接一个的语句被分号分隔。
| 语句 | 描述 |
|---|---|
| Compound operator {} | 花括号 {} 括起来的一个或者多个任一类型语句 |
| Expression operator (😉 | 分号 (😉 结尾的表达式 |
| return | 终止当前函数和返回控制访问程序 |
| if-else | 需要作出选择时使用 |
| ?: | 一个简单的if - else条件运算符 |
| switch | 控制与表达式值一致的语句 |
| while | 执行语句直到表达式变成错误。每次重复前都要检查表达式。 |
| for | 执行语句直到表达式变成错误。每次重复前都要检查表达式。 |
| do-while | 执行语句直到表达式变成错误。每次重复后进行检测。主体至少执行一次。 |
| break | 终止执行最近的外部语句, while,do-while 或者 for |
| continue | 控制最近的外部循环语句 while,do-while 或者for的起点。 |
| new | 创建大小合适的对象以及返回创建对象的描述符。 |
| delete | 删除 new 语句创建的对象 |
一个语句可以占用一个或多个行。两个或多个语句可以位于同一行。 控制执行顺序的语句(if、if、else、switch和for)可以相互嵌套。
示例:
if(Month() == 12)
if(Day() == 31) Print("Happy New Year!");
2
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.2 表达式语句
任何以分号(;)结束的表达式都被视为是一个语句。这里是一些表达式语句的例子:
赋值语句 标识符 = 表达式;
x=3;
y=x=3;
bool equal=(x==y);
2
3
赋值运算符可以在一个表达式中运用多次。在这种情况下,表达式的处理顺序是从右向左。
函数调用语句
Function_name (argument1,..., argumentN); // 函数名(参数1,参数2,...,参数N);
FileClose(file);
2
3
空语句
它是由分号(;)组成并且使用在一个检测语句中。
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.3 返回语句
return语句终止当前的函数执行并将控制权返回给调用程序。表达式计算结果返回给调用函数。 表达式可以包含赋值运算符。
示例:
int CalcSum(int x, int y)
{
return(x+y);
}
2
3
4
如果函数的返回类型为空(void),则必须使用无表达式的return语句:
void SomeFunction()
{
Print("Hello!");
return; // 语句可以被移除
}
2
3
4
5
函数的右括号表示没有表达式的返回语句的隐式执行。
可以返回什么类型的数据?如:简单类型、简单结构、对象指针。 返回语句,不能用于返回任何数组、类对象、复合结构类型的变量。
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.4 If-else 假设语句(条件分支)
需要选择时使用If-else 语句。语法形式如下:
if (expression)
operator1
else
operator2
2
3
4
如果表达式为真,则执行语句1(operator1)并将其控制交给给语句2之后的语句(operator2不执行)。 如果表达式的结果为false,则执行(语句1)operator2。
if语句的else部分可以省略。但是请注意,如果语句省略了else部分,则可能在嵌套时出现歧意。 在本例中,如果在同一段代码块中,没有其他esle的部分,则else会优先匹配前一个与其最近的if语句。
示例:
//--- else 部分提及到第二个if语句:
if(x>1)
if(y==2) z=5;
else z=6;
//--- else部分提及到第一个if语句:
if(x>l)
{
if(y==2) z=5;
}
else z=6;
//--- 嵌入语句
if(x=='a')
{
y=1;
}
else if(x=='b')
{
y=2;
z=3;
}
else if(x=='c')
{
y=4;
}
else Print("ERROR");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.5 假设语句 ? :
三元算子语句的一般形式是:
expression1? expression2:expression3
第一个表达式——“expression1”——可以使用任何布尔(bool)类型的表达式。 如果结果为真,则执行第二个表达式(即为),得出的结果为此条语句的最终结果。 即执行“expression2”。
如果第一个表达式的结果为false,则执行第三个语句----"expression3"。 第二和第三个语句,即“expression2”和“expression3”的计算结果不应该是void类型。 三元算子语句条件语句执行的结果是表达式1或表达式2的结果,取决于expression1的结果是真还是假。
//--- 一天中开盘价和收盘价的标准化不同点
double true_range = (High==Low)?0:(Close-Open)/(High-Low);
2
输入等同于如下:
double true_range;
if (High==Low)
true_range=0; // 如果最高价等于
else
true_range = (Close-Open)/(High-Low); // 如果范围无效
2
3
4
5
语句使用限制
基于"expression1"值,三元算子语句必须返回两个表达式的其中的一个的计算结果 - 或者"expression2", 或者"expression3"。对这些表达式有几个限制: 1.不要将用户定义的类型与简单类型或枚举混合。NULL可以用于指针。 2.如果值是简单类型,语句将会是最大类型(请见类型转换 )。 3.如果第一个值是枚举类型而第二个值是数字类型,那么枚举类型将被整型所取代并实施第二个规则。 4.如果两个值都是枚举类型,它们的类型必须完全相同,并且语句将是枚举类型。
用户定义类型(类或结构)的限制: a.类型必须完全相同或者一个应该源自另一个。 b.如果类型不相同(继承类型),那么子类型会隐式转换至父类型,意即语句将成为父类型。 c.不要混用对象和指针 ---- 两个表达式或者都是对象,或者都是指针。NULL可以用于指针。
注意 在使用三元算子语句作为 重载函数 的参数时要谨慎,因为在程序编译时定义了三元算子语句的结果类型。 这种类型被确定为“expression2”和“expression3”二者中较大的类型。
示例:
void func(double d) { Print("double argument: ",d); }
void func(string s) { Print("string argument: ",s); }
bool Expression1=true;
double Expression2=M_PI;
string Expression3="3.1415926";
void OnStart()
{
func(Expression2);
func(Expression3);
func(Expression1?Expression2:Expression3); // 隐式转换到字符串的警告
func(!Expression1?Expression2:Expression3); // 隐式转换到字符串的警告
}
// 结果:
// double argument: 3.141592653589793
// string argument: 3.1415926
// string argument: 3.141592653589793
// string argument: 3.1415926
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.6 循环语句while
while语句是由一个已检测的表达式和语句构成,需要满足以下条件:
while(expression)
operator;
2
如果表达式为true,则执行运算符,直到表达式变为false。如果表达式为false,则将控制权传递给下一个语句。 在执行语句之前定义表达式值。因此,如果表达式从一开始就是false,则语句将不会被执行。
注意 如果预计一个循环中处理大量的迭代,建议您使用IsStopped()函数检查被迫中止程序的事实。
示例
while(k < n && !IsStopped())
{
y=y*x;
k++;
}
2
3
4
5
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
1.4.7 切换语句(多项条件分支)
将表达式的值与所有case 之后的常量进行比较,并将控制权传递给对应于表达式的值的运算符。 每一种情况都可以用一个整数常数、一个字符常数或一个常数表达式来标记。 常量表达式不能包含变量或函数调用。切换语句的表达式必须为整数类型 int或uint。
switch(expression)
{
case constant: operators
case constant: operators
...
default: operators
}
2
3
4
5
6
7
如果语句中没有任何一个case 常量与表达式的值相等,则执行 default 标签标记的语句。 default选项可以省略,也可以不放在最后一个的位置。 如果没有一个case常量与表达式的值相对应,并且也没有default的选项,则不会执行任何操作。
带有常量的case关键字只是标签,如果语句在某些情况下被执行, 程序将进一步执行所有后续变量的语句,直到 break 中断语句出现为止。 它允许绑定一系列具有多个选项的语句。
在编译过程中计算常数表达式。一个switch语句中不能出现两个case常数有相同的值。
示例:
//--- First example
switch(x)
{
case 'A':
Print("CASE A");
break;
case 'B':
case 'C':
Print("CASE B or C");
break;
default:
Print("NOT A, B or C");
break;
}
//--- Second example
string res="";
int i=0;
switch(i)
{
case 1:
res=i;break;
default:
res="default";break;
case 2:
res=i;break;
case 3:
res=i;break;
}
Print(res);
/*
Result
default
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.8 循环语句For
for语句由三个表达式和一个执行语句组成:
for(expression1; expression2; expression3)
operator;
2
Expression1描述了循环初始化。Expression2检查循环终止的条件。 如果是true,则执行循环体。循环重复,直到表达式2的结果变成 false。 如果为 false,则循环终止,并将控制权交给下一个语句。Expression3是在每次迭代之后计算的。
对语句while而言,相当于下列表达方式:
expression1;
while(expression2)
{
operator;
expression3;
};
2
3
4
5
6
在for语句中,三个或三个表达式中的任何一个都可以省略,但是分隔它们的分号(;)不能省略。 如果省略expression2,则就认为expression2的结果是 true。 for(;;)语句是一个无限的循环,相当于while(1)语句。 表达式1或3可以由多个表达式组成,用逗号运算符分隔。
WARNING
注意 如果预计一个循环中处理大量的迭代,建议您使用IsStopped()函数检查被迫中止程序的事实。
示例:
for(x=1;x <= 7000; x++)
{
if(IsStopped())
break;
Print(MathPower(x,2));
}
//--- 另一个示例
for(;!IsStopped();)
{
Print(MathPower(x,2));
x++;
if(x>10) break;
}
//--- 第三示例
for(i=0,j=n-l;i < n && !IsStopped();i++,j--) a[i]=a[j];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.9 循环语句 do while
for 和 while 循环语句在第一次循环开始之前就会检测终止条件,而不是在循环末端。 第三种循环语句do - whileo是在每次循环之后,再检测终止条件。循环体至少会执行一次。 do operator; while(expression);
首先执行语句,然后计算表达式。如果是true,那么语句再次执行。如果表达式变成false,循环终止。
注意
如果预计在一个循环中处理大量的迭代, 建议您使用IsStopped()函数检查被迫中止程序的事实。
示例: //--- 计算斐波纳契数列 int counterFibonacci=15; int i=0,first=0,second=1; int currentFibonacciNumber; do { currentFibonacciNumber=first+second; Print("i = ",i," currentFibonacciNumber = ",currentFibonacciNumber); first=second; second=currentFibonacciNumber; i++; // 没有这个语句会出现一个无限循环! } while( i < counterFibonacci && !IsStopped() );
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.10 嵌入语句
break语句终止最近外部嵌入语句 switch, while, do-while 或者 for 的执行。 在终止语句之后给出检测语句。这个语句的目的之一:当中心值指定为变量时,语句完成循环执行。
示例:
//--- 搜索第一个零元素
for(i=0;i < array_size;i++)
if(array[i]==0)
break;
2
3
4
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.11 继续语句
一个继续语句。 我们将其放在嵌套内的指定位置,用来在指定情况下跳过接下来的运算, 直接跳入下一次的循环 while, do-while 或者 for语句。语句break位置与此语句相反。
示例:
//--- 所有非零元素总和
int func(int array[])
{
int array_size=ArraySize(array);
int sum=0;
for(int i=0;i < array_size; i++)
{
if(a[i]==0) continue;
sum+=a[i];
}
return(sum);
}
2
3
4
5
6
7
8
9
10
11
12
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.12 对象创建语句new
new 语句自动创建一个相应大小的对象,称为对象构造函数并回转已经创建的对象描述符。 失败的情况下,语句返回一个与常量NULL相比较的null描述符。
new语句仅能用于类对象。不能应用于结构。
语句不用于创建对象数组。若要做这个,使用 ArrayResize() 。
示例:
//+------------------------------------------------------------------+
//| 图形创建 |
//+------------------------------------------------------------------+
void CTetrisField::NewShape()
{
m_ypos=HORZ_BORDER;
//--- 随机创建7个可能形状中的一个
int nshape=rand()%7;
switch(nshape)
{
case 0: m_shape=new CTetrisShape1; break;
case 1: m_shape=new CTetrisShape2; break;
case 2: m_shape=new CTetrisShape3; break;
case 3: m_shape=new CTetrisShape4; break;
case 4: m_shape=new CTetrisShape5; break;
case 5: m_shape=new CTetrisShape6; break;
case 6: m_shape=new CTetrisShape7; break;
}
//--- 绘画
if(m_shape!=NULL)
{
//--- 预置
m_shape.SetRightBorder(WIDTH_IN_PIXELS+VERT_BORDER);
m_shape.SetYPos(m_ypos);
m_shape.SetXPos(VERT_BORDER+SHAPE_SIZE*8);
//--- 绘画
m_shape.Draw();
}
//---
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
注意对象描述符不是内存指标。 用new语句创建的对象不能用delete语句直接移动。
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.4.13 对象删除语句 delete
delete语句删除通过new语句创建的对象,称为相关的类析构函数并释放由对象占据的内存。 现存对象的真实析构函数用作操作对象。delete操作执行后,对象析构函数无效 。
示例:
//--- 删除图形
delete m_shape;
m_shape=NULL;
//--- 创建一个新图形
NewShape();
2
3
4
5
相关参考
变量初始化 , 可见范围和变量使用期 , 创建和删除对象
# 1.5 函数
每个任务都可以分成子任务,每个子任务可以直接以代码的形式表示,也可以分成更小的子任务。 这种方法叫做逐步求精。函数用于编写要解决的子任务的代码。描述函数做什么的代码叫做函数定义:
function_header
{
instructions
}
2
3
4
第一个花括号前面是函数定义的表头(函数头),括号中间是函数定义的主体(函数体)。 函数头包括函数返回值的数据类型声明,函数名称(标识符)和形式参数的描述。 传递给函数的形式参数数量是有限的,不能超过64个。
这个函数可以根据需要多次从程序的其它部分调用。实际上,返回类型、函数标识符和参数类型构成函数原型。
函数原型是函数声明,但不是它的定义。虽然在函数表头部分明确的声明了返回类型和自变量的数据类型列表, 但是在函数主体部分,在调用函数时仍有可能会执行严格的数据类型检测 和 隐式的类型转换。 通常在类中使用函数声明来提高代码的可读性。
函数定义(即函数主体的返回值)必须与它的声明完全匹配。每个声明的函数必须被定义(即必须有函数主体)。
示例:
double // 返回值类型
linfunc (double a, double b) // 函数名和参量列表
{
// 组合语句
return (a + b); // 返回值
}
2
3
4
5
6
返回语句可以返回位于该语句中的表达式的值。如果需要,表达式的值会转换为函数专声明时的数据类型。 函数可以返回的数据类型包括: 简单类型、简单结构、对象指针。 使用返回语句,不能返回任何数组、类对象、复合结构类型的变量。 没有返回值的函数应该被声明为 void 类型的函数。
示例:
void errmesg(string s)
{
Print("error: "+s);
}
2
3
4
传递给函数的参数可以有默认值,这些值由该类型的常量定义。
示例:
int somefunc(double a,
double d=0.0001,
int n=5,
bool b=true,
string s="passed string")
{
Print("Required parameter a = ",a);
Print("Pass the following parameters: d = ",d," n = ",n," b = ",b," s = ",s);
return(0);
}
2
3
4
5
6
7
8
9
10
如果任何一个形式参数有默认值,那么所有后续的形式参数也必须有默认值。
错误说明示例:
int somefunc(double a,
double d=0.0001, // 声明默认值
int n, // 没有指定默认值 !
bool b, // 没有指定默认值 !
string s="passed string")
{
}
2
3
4
5
6
7
相关参考
重载, 虚拟函数, 多态
# 1.5.1 调用函数
如果出现了一个之前没有声明过的标识符名称出现在表达式中,并且后面跟着左括号。则它将被上下文看作是一个函数的名称。
function_name (x1, x2,..., xn)
函数的参数(形式参数)按值传递,即每个表达式x1,…xn在经过计算后,将结果值传递给函数。 表达式的计算顺序和计算结果值的加载顺序是无法保证的。在执行过程中,系统检查传递给函数的参数的数量和类型。 这种处理函数的方法被称为值调用。
函数调用是一个表达式,其结果值即是函数返回的值。 上面声明的函数类型必须与返回值的类型相对应。 该函数可以在全局范围内的任何部分声明或定义,意即,在所有其它函数之外声明和定义函数。 函数不能在另一个函数中声明或定义。
示例:
int start()
{
double some_array[4]={0.3, 1.4, 2.5, 3.6};
double a=linfunc(some_array, 10.5, 8);
//...
}
double linfunc(double x[], double a, double b)
{
return (a*x[0] + b);
}
2
3
4
5
6
7
8
9
10
在调用函数时,如果形式参数有默认值,则传递的参数,可以少于形式参数列表中的个数。 但是如果有形式参数没有指默认值,则调用函数时,对应的参数不能省缺。
示例:
void somefunc(double init,
double sec=0.0001, //设置默认值
int level=10);
//...
somefunc(); // 错误调用。必须传递第一个参数
somefunc(3.14); // 正确调用
somefunc(3.14,0.0002); // 正确调用
somefunc(3.14,0.0002,10); // 正确调用
2
3
4
5
6
7
8
当调用一个函数时,不能跳过某一个形式参数,即使那个形式参数具有默认值:
somefunc(3.14, , 10); // 错误调用 -> 跳过了第二个形式参数
相关参考
重载, 虚拟函数, 多态
# 1.5.2 传递参数
机器语言有两种方法,可以将参数传递给子程序(函数)。 第一个方法是按值发送参数。该方法将变量值复制到一个函数的形式参数中。 因此,在函数内该参数的任何变化都不会影响对应的这个变量。
//+------------------------------------------------------------------+
//| 通过值传递参数 |
//+------------------------------------------------------------------+
double FirstMethod(int i,int j)
{
double res;
//---
i*=2;
j/=2;
res=i+j;
//---
return(res);
}
//+------------------------------------------------------------------+
//| 脚本程序启动函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//---
int a=14,b=8;
Print("a and b before call:",a," ",b);
double d=FirstMethod(a,b);
Print("a and b after call:",a," ",b);
}
//--- 执行脚本结果
// 调用前a 和 b : 14 8
// 调用后a 和 b : 14 8
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
第二种方法是引用。在这种情况下,引用一个变量的地址(而不是它的值)传递给函数参数。 在函数内,引用该变量的地址,取到对应的值做为实际参数参与计算。 这意味着该变量的值,将会受到函数内部计算处理的影响而发生变化。
//+------------------------------------------------------------------+
//| 通过引用传递参数 |
//+------------------------------------------------------------------+
double SecondMethod(int & i,int & j)
{
double res;
//---
i *= 2;
j / =2;
res =i+j;
//---
return(res);
}
//+------------------------------------------------------------------+
//| 脚本程序启动函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//---
int a=14,b=8;
Print("a and b before call:",a," ",b);
double d=SecondMethod(a,b);
Print("a and b after call:",a," ",b);
}
//+------------------------------------------------------------------+
//--- 执行脚本结果
// 调用前a 和 b: 14 8
// 调用后a 和 b: 28 4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
MQL5允许使用这两种函数传递参数方式,但有一个例外就是:数组和结构类型变量(类的对象)总是通过引用的方式传递参数。 为了避免实际参数的变化(调用函数时用 引用 方式传递的变量的值)可以使用接入说明符 const(请参考 接入说明符)。 当函数尝试更改由const说明符声明的变量的值的时候,编译器会产生一个错误。
注解
应该注意的是,参数以相反的顺序传递给函数, 即:首先计算并传递的是形式参数列表中最后一个参数,然后是倒数第二个参数,以此类推。 最后一个计算并传递给函数的参数,恰恰是在形式参数列表中的紧跟左括号 ( 的第一个参数。
示例:
void OnStart()
{
//---
int a[]={0,1,2};
int i=0;
func(a[i],a[i++],"First call (i = "+string(i)+")");
func(a[i++],a[i],"Second call (i = "+string(i)+")");
// 结果:
// 首先调用 (i = 0) : par1 = 1 par2 = 0
// 第二调用 (i = 1) : par1 = 1 par2 = 1
}
//+------------------------------------------------------------------+
//| |
//+------------------------------------------------------------------+
void func(int par1,int par2,string comment)
{
Print(comment,": par1 = ",par1," par2 = ",par2);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
上面的示例中,调用函数时首先处理的是变量i参与合并字符串,即
"First call (i = "+string(i)+")"
这时,i的值不会改变。然后处理第二个参数,变量 i 加入a[i++]数组的运算,在这一步获取了数组i++位置的元素的值为1。 最后,处理的形式参数列表中的第一个参数,a[i],结果是获取了数组i位置的元素,其值为0。
第二次调用函数时,在计算所有三个参数时使用 i (在函数调用的第一个阶段计算) 的相同值。 只有在第一个参数计算之后,i变量才会再次改变。
相关参考
可见范围和变量使用期 ,重载, 虚拟函数, 多态
# 1.5.3 重载函数
如果你想声明一个自定义函数。但在声明时,用的函数名称与MQL内置的某个函数名称相同,通常是不允许的。例如,
double MathMax(double a,double b)
编译时,会收到以下错误消息: 'MathMax' - override system function //MathMax 覆盖系统函数,意即 MathMax 与系统内置的函数名称有冲突。
WARNING
(智能交易*姚提示———— 简单的处理方法,当然是换一个自定义名称罗。 但任性是常态,我非要用这个函数名称,我喜欢,就是喜欢! 同样的,在自定义函数时,声明2个功能不同的函数,但用的函数名称是一样的。通常这也是不允许的。 不同的功能用不同的函数名称呗,自己思路也清晰,多好。 我不,我偏不,我就要用一个函数名称,但同时实现不同的功能。我喜欢! 好吧.....
用一个函数名称,但可以在不同的时候调用,分别执行不同的功能。MQL中称这样的函数为 重载函数。 通常函数名称往往反映了它的主要目的。一般来说,为增加程序源码的可读性,在使用标识符时尽可能精心挑选。 有时不同的函数用于相同的目的。
例如,我们考虑一个函数,该函数计算双精度数组的平均值,同样这一个函数,也用来计算整数数组的平均值。 这两个方法都使用同一个函数,声明时的名称都是 AverageFromArray:
//+------------------------------------------------------------------+
//| 计算双精度类型数组的平均数 |
//+------------------------------------------------------------------+
double AverageFromArray(const double array[],int size)
{
if(size < = 0) return 0.0;
double sum=0.0;
double aver;
//---
for(int i=0;i < size;i++)
{
sum += array[i]; // 添加到双精度型
}
aver=sum / size; // 正好总数被数字除
//---
Print("Calculation of the average for an array of double type");
return aver;
}
//+------------------------------------------------------------------+
//| 计算整型数组的平均数 |
//+------------------------------------------------------------------+
double AverageFromArray(const int array[],int size)
{
if(size < = 0) return 0.0;
double aver=0.0;
int sum=0;
//---
for(int i=0;i < size;i++)
{
sum += array[i]; // 添加到双精度
}
aver=(double)sum / size; // 给予双精度类型总值,并且相除
//---
Print("Calculation of the average for an array of int type");
return aver;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
每个函数都用 Print()函数输出信息;
Print("Calculation of the average for an array of int type");
编译器根据参数的类型和数量选择一个必要的函数。其选择的规则被称为 特征匹配算法。 特征是指函数声明中使用的 形式参数 类型列表。
示例:
//+------------------------------------------------------------------+
//| 脚本程序启动函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//---
int a[5]={1,2,3,4,5};
double b[5]={1.1,2.2,3.3,4.4,5.5};
double int_aver=AverageFromArray(a,5);
double double_aver=AverageFromArray(b,5);
Print("int_aver = ",int_aver," double_aver = ",double_aver);
}
//--- 脚本结果
// 为整型数组计算平均值
// 为双精度型数组计算平均值
// 整型 平均值= 3.00000000 双精度 平均值= 3.30000000
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
函数重载就是指,使用一个函数名称,创建几个函数,但是 形式参数 不同。 这意味着使用同一个函数名称的多个重载变体中,形式参数的 数量 和/或 类型 必须不同。 根据调用函数时实际参数的列表 与 函数声明中形式参数列表的对应关系选择特定的函数变体。
当调用一个重载的函数时,编译器必须有一个算法来选择适当的函数变体。 执行此选择的算法取决于参数的类型。最好的情况是 形式参数 与 实际参数 的对应匹配必须是唯一的。 对于至少一个参数,重载函数必须是所有其他变体之间的最佳匹配。同时它必须匹配所有其他参数不比其他变种更糟。
以下就是每个形式参数匹配的算法。选择一个重载函数的运算法则
- 匹配严格(尽可能)。
- 尝试标准类型提高。
- 尝试标准类型转换。
标准类型提高优于标准类型转换。 提高就是浮点型(float)向双精度型(double)转换,布尔型(bool)、字符型(char)、 短整型(short)或者枚举型(enum)向整数型(int)转换。 类似整型数组的类型转换也属于标准类型转换。 相似类型有:布尔型(bool),字符型(char),无符号字符型(uchar),这三种都是单字节整数; 双字节整数是短整型(short)和无符号短整型(ushort); 4字节整数是整型(int),无字符整型(uint)和颜色(color); 8字节整数是长整型(long),无符号长整型(ulong)和日期时间(datetime)。
当然,严格的匹配是最好的。为了达到这样的一致性,可以使用类型转换。 编译器无法应付模棱两可的情况。因此,您不应该依赖类型和隐式转换的细微差别,从而导致 重载函数不清晰。 如果您不确定,请使用显式转换来确保严格遵守规则。 MQL5中重载的函数可以在ArrayInitialize()函数示例中看到。 函数重载规则也适用于 类(class) 函数重载 。 系统函数的重载是允许的,但应该注意到,编译器能够准确地选择必要的函数。
例如,用三种不同方法重载系统函数 fmax(),但是仅有两个变量是正确的。
示例:
// 允许重载-在参数数字上不同
double fmax(double a,double b,double c);
// 错误重载
// 参数是不同的,但是最后一个有默认值
// 这就导致系统函数的隐藏,不可接受调用
double fmax(double a,double b,double c=DBL_MIN);
// 通过参数类型正常重载
int fmax(int a,int b);
例如,我们可以用4种不同的方法重载系统函数MathMax(),但只有两个函数的变体是正确的。
// 1. overload is allowed -
// function differs from built-in MathMax() function in the number of parameters
// 允许重载 -- 因为函数的形式参数与MQL语言内置函数的形式参数数量不同
double MathMax(double a,double b,double c);
// 2. overload is not allowed!
// number of parameters is different, but the last has a default value
// this leads to the concealment of the system function when calling, which is unacceptable
// 不允许重载 -- 虽然函数的参数数量不一致,但最后一个参数赋于了默认值,
//这将导致调用函数时隐藏(省略)参数传递,这是不可接受的
double MathMax(double a,double b,double c=DBL_MIN);
// 3. overload is allowed - normal overload by type of parameters a and b
// 允许重载 -- 因为形式参数的类型与内置函数的形式参数类型不同
double MathMax(int a,int b);
// 4. overload is not allowed!
// the number and types of parameters are the same as
// in original double MathMax(double a,double b)
// 不允许重载 -- 参数的数量和类型都和内置函数是一样的
int MathMax(double a,double b);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
相关参考
重载, 虚拟函数, 多态
# 1.5.4 操作重载
为了便于代码读取和写入,允许重载某些操作。重载语句的关键字是 operator 以下语句可重载:
- 二进制运算 +,-, / , ,%,<<,>>,==,!=,<,>,<=,>=,=,+=,-=,/=,=,%=, &=,|=,^=,<<=,>>=, && ,||, & , | ,^
- 一元操作 +,-,++,--,!,~
- 赋值语句 =
- 索引语句 [ ]
操作重载允许使用语句号(以简单表达式的形式编写)用于复杂对象——结构和类。 使用重载操作编写表达式简化了源代码的视图,因为隐藏了更复杂的处理方式。
考虑复数的例子,其中包括 实数 和 虚数。它们广泛用于数学领域。 但是在MQL5语言中没有表示 复数 的数据类型。 我们可以用 结构 或 类 的形式创建新的数据类型。声明复杂结构并定义四种处理执行四个算术运算的方法:
//+------------------------------------------------------------------+
//| 复数操作结构 |
//+------------------------------------------------------------------+
struct complex
{
double re; // 实数
double im; // 虚数
//--- 构造函数
complex():re(0.0),im(0.0) { }
complex(const double r):re(r),im(0.0) { }
complex(const double r,const double i):re(r),im(i) { }
complex(const complex & o):re(o.re),im(o.im) { }
//--- 算术运算
complex Add(const complex & l,const complex & r) const; // 加法
complex Sub(const complex & l,const complex & r) const; // 减法
complex Mul(const complex & l,const complex & r) const; // 乘法
complex Div(const complex & l,const complex & r) const; // 除法
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
现在,在我们的代码中我们可以声明表示复数的变量,并使用它们。
例如:
void OnStart()
{
//--- 声明并初始化复杂类型的变量
complex a(2,4),b(-4,-2);
PrintFormat("a=%.2f+i*%.2f, b=%.2f+i*%.2f",a.re,a.im,b.re,b.im);
//--- 两个数字总和
complex z;
z=a.Add(a,b);
PrintFormat("a+b=%.2f+i*%.2f",z.re,z.im);
//--- 两个数字相乘
z=a.Mul(a,b);
PrintFormat("a*b=%.2f+i*%.2f",z.re,z.im);
//--- 两个数字相除
z=a.Div(a,b);
PrintFormat("a/b=%.2f+i*%.2f",z.re,z.im);
//---
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
但是对于复数的普通算术运算,直接使用一般的语句 "+", "-", "*" 和 "/"会更加方便。
关键字 operator 用于定义执行类型转换的成员函数。 类对象变量的一元和二进制操作可以作为非静态成员函数重载。它们隐式地作用于类对象。 大多数二进制操作都可以像常规函数那样重载,它们以一个或两个参数作为类变量或指向该类的对象的指针。 对于我们本例中的复数类型,在声明中重载是这样的:
//--- 语句
complex operator+(const complex & r) const { return(Add(this,r)); }
complex operator-(const complex & r) const { return(Sub(this,r)); }
complex operator*(const complex & r) const { return(Mul(this,r)); }
complex operator/(const complex & r) const { return(Div(this,r)); }
2
3
4
5
完整的脚本示例源码:
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 声明和初始化复杂类型的变量
complex a(2,4),b(-4,-2);
PrintFormat("a=%.2f+i*%.2f, b=%.2f+i*%.2f",a.re,a.im,b.re,b.im);
//a.re=5;
//a.im=1;
//b.re=-1;
//b.im=-5;
//--- 两个数字总和
complex z=a+b;
PrintFormat("a+b=%.2f+i*%.2f",z.re,z.im);
//--- 两个数字相乘
z=a*b;
PrintFormat("a*b=%.2f+i*%.2f",z.re,z.im);
//--- 两个数字相除
z=a/b;
PrintFormat("a/b=%.2f+i*%.2f",z.re,z.im);
//---
}
//+------------------------------------------------------------------+
//| 复数操作结构 |
//+------------------------------------------------------------------+
struct complex
{
double re; // 实数
double im; // 虚数
//--- 构造函数
complex():re(0.0),im(0.0) { }
complex(const double r):re(r),im(0.0) { }
complex(const double r,const double i):re(r),im(i) { }
complex(const complex & o):re(o.re),im(o.im) { }
//--- 算术运算
complex Add(const complex &l,const complex &r) const; // 加法
complex Sub(const complex &l,const complex &r) const; // 减法
complex Mul(const complex &l,const complex &r) const; // 乘法
complex Div(const complex &l,const complex &r) const; // 除法
//--- 二进制语句
complex operator+(const complex &r) const { return(Add(this,r)); }
complex operator-(const complex &r) const { return(Sub(this,r)); }
complex operator*(const complex &r) const { return(Mul(this,r)); }
complex operator/(const complex &r) const { return(Div(this,r)); }
};
//+------------------------------------------------------------------+
//| 加法 |
//+------------------------------------------------------------------+
complex complex::Add(const complex &l,const complex &r) const
{
complex res;
//---
res.re=l.re+r.re;
res.im=l.im+r.im;
//--- 结果
return res;
}
//+------------------------------------------------------------------+
//| 减法 |
//+------------------------------------------------------------------+
complex complex::Sub(const complex &l,const complex &r) const
{
complex res;
//---
res.re=l.re-r.re;
res.im=l.im-r.im;
//--- 结果
return res;
}
//+------------------------------------------------------------------+
//| 乘法 |
//+------------------------------------------------------------------+
complex complex::Mul(const complex &l,const complex &r) const
{
complex res;
//---
res.re=l.re*r.re-l.im*r.im;
res.im=l.re*r.im+l.im*r.re;
//--- 结果
return res;
}
//+------------------------------------------------------------------+
//| 除法 |
//+------------------------------------------------------------------+
complex complex::Div(const complex &l,const complex &r) const
{
//--- 空复数
complex res(EMPTY_VALUE,EMPTY_VALUE);
//--- 检查零
if(r.re==0 && r.im==0)
{
Print(__FUNCTION__+": number is zero");
return(res);
}
//--- 辅助变量
double e;
double f;
//--- 选择计算变量
if(MathAbs(r.im) < MathAbs(r.re))
{
e = r.im/r.re;
f = r.re+r.im*e;
res.re=(l.re+l.im*e)/f;
res.im=(l.im-l.re*e)/f;
}
else
{
e = r.re/r.im;
f = r.im+r.re*e;
res.re=(l.im+l.re*e)/f;
res.im=(-l.re+l.im*e)/f;
}
//--- 结果
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
类的大多数一元操作都可以作为普通函数重载,这些函数接受单个类对象参数或指向它的指针。 增加一元操作的重载“-”和“!”示例如下:
//+------------------------------------------------------------------+
//| 复数操作结构 |
//+------------------------------------------------------------------+
struct complex
{
double re; // 实数
double im; // 虚数
...
//--- 一进制语句
complex operator-() const; // 一进制减操作
bool operator!() const; // 非操作
};
...
//+------------------------------------------------------------------+
//| 重载"一进制减" 语句 |
//+------------------------------------------------------------------+
complex complex::operator-() const
{
complex res;
//---
res.re=-re;
res.im=-im;
//--- 结果
return res;
}
//+------------------------------------------------------------------+
//| 重载 "逻辑非" 语句 |
//+------------------------------------------------------------------+
bool complex::operator!() const
{
//--- 复数的实数和虚数等于零吗?
return (re!=0 && im!=0);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
现在我们可以检查零复数值并获得一个负值:
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 声明和初始化复杂类型的变量
complex a(2,4),b(-4,-2);
PrintFormat("a=%.2f+i*%.2f, b=%.2f+i*%.2f",a.re,a.im,b.re,b.im);
//--- 两个数字相除
complex z=a/b;
PrintFormat("a/b=%.2f+i*%.2f",z.re,z.im);
//--- 复数默认等于零(默认构造函数re==0 和 im==0)
complex zero;
Print("!zero=",!zero);
//--- 分配负值
zero=-z;
PrintFormat("z=%.2f+i*%.2f, zero=%.2f+i*%.2f",z.re,z.im, zero.re,zero.im);
PrintFormat("-zero=%.2f+i*%.2f",-zero.re,-zero.im);
//--- 再次检查零值
Print("!zero=",!zero);
//---
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
注意我们无需重载赋值语句 "=",因为 简单类型的结构 可以直接复制成另一个。 因此,我们现在可以用普通方式书写涉及复数计算的代码。
数组索引语句重载允许以一种简单而熟悉的方式获取封装在对象中的数组的值, 它也有助于提高源代码的可读性。
例如,我们需要在一个字符串中指定位置访问一个字符。 MQL5中的字符串是一个单独的字符串类型,它不是一个字符数组,但是在数组索引重载操作的帮助下, 我们可以生成CString类,从而提供一种简单透明的工作方式:
//+------------------------------------------------------------------+
//| 访问类似符号数组的字符串符号的类 |
//+------------------------------------------------------------------+
class CString
{
string m_string;
public:
CString(string str=NULL):m_string(str) { }
ushort operator[] (int x) { return(StringGetCharacter(m_string,x)); }
};
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 从字符串接收符号的数组
int x[]={ 19,4,18,19,27,14,15,4,17,0,19,14,17,27,26,28,27,5,14,
17,27,2,11,0,18,18,27,29,30,19,17,8,13,6 };
CString str("abcdefghijklmnopqrstuvwxyz[ ]CS");
string res;
//--- 使用来自str变量的符号组成短语
for(int i=0,n=ArraySize(x);i < n;i++)
{
res+=ShortToString(str[x[i]]);
}
//--- 显示结果
Print(res);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
数组索引操作重载的另一个例子是矩阵的操作。矩阵表示一个二维动态数组,数组大小未预先定义。 因此,您不能在没有指定第二个维度的大小的情况下从数组array[ ][ ]中再声明一个 数组,
WARNING
(智能交易*姚提示————声明数组时,第二维度不能为空,意即 array1[ ][100]是正确的。 Array2[100][ ]是错误的。更不可能声明 array3[ ][ ])
然后将此数组作为参数传递。 一个可能的解决方案是一个特殊的类CMatrix,它包含一组CRow类对象。
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 矩阵的加法和乘法操作
CMatrix A(3),B(3),C();
//--- 准备数组行
double a1[3]={1,2,3}, a2[3]={2,3,1}, a3[3]={3,1,2};
double b1[3]={3,2,1}, b2[3]={1,3,2}, b3[3]={2,1,3};
//--- 填补矩阵
A[0]=a1; A[1]=a2; A[2]=a3;
B[0]=b1; B[1]=b2; B[2]=b3;
//--- 在专家日志输出矩阵
Print("---- Elements of matrix A");
Print(A.String());
Print("---- Elements of matrix B");
Print(B.String());
//--- 矩阵加法
Print("---- Addition of matrices A and B");
C=A+B;
//--- 输出格式化字符串表示
Print(C.String());
//--- 矩阵乘法
Print("---- Multiplication of matrices A and B");
C=A*B;
Print(C.String());
//--- 现在我们展示如何在动态数组matrix[i][j]风格下得到值
Print("Output the values of matrix C elementwise");
//--- 通过矩阵行 - CRow 对象 - 循环
for(int i=0;i < 3;i++)
{
string com="| ";
//--- 形成矩阵的行值
for(int j=0;j < 3;j++)
{
//--- 通过行数和列数获得矩阵元素
double element=C[i][j];// [i] - 在数组 m_rows[]访问CRow ,
// [j] - 重载CRow索引语句
com=com+StringFormat("a(%d,%d)=%G ; ",i,j,element);
}
com+="|";
//--- 输出行值
Print(com);
}
}
//+------------------------------------------------------------------+
//| 类 "行" |
//+------------------------------------------------------------------+
class CRow
{
private:
double m_array[];
public:
//--- 构造函数和析构函数
CRow(void) { ArrayResize(m_array,0); }
CRow(const CRow & r) { this=r; }
CRow(const double & array[]);
~CRow(void){};
//--- 行的元素数
int Size(void) const { return(ArraySize(m_array));}
//--- 返回一个字符串值
string String(void) const;
//--- 索引语句
double operator[](int i) const { return(m_array[i]); }
//--- 赋值语句
void operator=(const double & array[]); // 数组
void operator=(const CRow & r); // 另一个 CRow 对象
double operator*(const CRow & o); // CRow 对象乘法
};
//+------------------------------------------------------------------+
//| 构造函数初始化数组行 |
//+------------------------------------------------------------------+
void CRow::CRow(const double & array[])
{
int size=ArraySize(array);
//--- 如果数组不为空
if(size>0)
{
ArrayResize(m_array,size);
//--- 填值
for(int i=0;i < size;i++)
m_array[i]=array[i];
}
//---
}
//+------------------------------------------------------------------+
//| 数组赋值操作 |
//+------------------------------------------------------------------+
void CRow::operator=(const double & array[])
{
int size=ArraySize(array);
if(size==0) return;
//--- 填充数组值
ArrayResize(m_array,size);
for(int i=0;i < size;i++) m_array[i]=array[i];
//---
}
//+------------------------------------------------------------------+
//| CRow 赋值操作 |
//+------------------------------------------------------------------+
void CRow::operator=(const CRow & r)
{
int size=r.Size();
if(size==0) return;
//--- 填充数组值
ArrayResize(m_array,size);
for(int i=0;i < size;i++) m_array[i]=r[i];
//---
}
//+------------------------------------------------------------------+
//| 另一行乘法的语句 |
//+------------------------------------------------------------------+
double CRow::operator*(const CRow & o)
{
double res=0;
//--- 验证
int size=Size();
if(size!=o.Size() || size==0)
{
Print(__FUNCSIG__,": Failed to multiply two matrices, their sizes are different");
return(res);
}
//--- 乘以数组elementwise 并添加产品
for(int i=0;i < size;i++)
res+=m_array[i]*o[i];
//--- 结果
return(res);
}
//+------------------------------------------------------------------+
//| 返回格式化字符串表示方式 |
//+------------------------------------------------------------------+
string CRow::String(void) const
{
string out="";
//--- 如果数组大小大于零
int size=ArraySize(m_array);
//--- 我们只使用一个非零的数组元素
if(size>0)
{
out="{";
for(int i=0;i < size;i++)
{
//--- 收集字符串的值
out+=StringFormat(" %G;",m_array[i]);
}
out+=" }";
}
//--- 结果
return(out);
}
//+------------------------------------------------------------------+
//| 类 "Matrix" |
//+------------------------------------------------------------------+
class CMatrix
{
private:
CRow m_rows[];
public:
//--- 构造函数和析构函数
CMatrix(void);
CMatrix(int rows) { ArrayResize(m_rows,rows); }
~CMatrix(void){};
//--- 得到矩阵大小
int Rows() const { return(ArraySize(m_rows)); }
int Cols() const { return(Rows()>0? m_rows[0].Size():0); }
//--- 以CRow行的形式返回列的值
CRow GetColumnAsRow(const int col_index) const;
//--- 返回字符串矩阵值
string String(void) const;
//--- 索引语句返回一个字符串数字
CRow *operator[](int i) const { return(GetPointer(m_rows[i])); }
//--- 加法语句
CMatrix operator+(const CMatrix & m);
//--- 乘法语句
CMatrix operator*(const CMatrix & m);
//--- 赋值语句
CMatrix *operator=(const CMatrix & m);
};
//+------------------------------------------------------------------+
//| 默认构造函数,创建和零行的数组 |
//+------------------------------------------------------------------+
CMatrix::CMatrix(void)
{
//--- 零矩阵的行数
ArrayResize(m_rows,0);
//---
}
//+------------------------------------------------------------------+
//| 返回CRow形式的列值 |
//+------------------------------------------------------------------+
CRow CMatrix::GetColumnAsRow(const int col_index) const
{
//--- 获得列值的变量
CRow row();
//--- 矩阵的行数
int rows=Rows();
//--- 如果大于零的行数,执行操作
if(rows>0)
{
//--- 接收col_index索引列的值的数组
double array[];
ArrayResize(array,rows);
//--- 填充数组
for(int i=0;i < rows;i++)
{
//--- 检查i行的列数 - 它可能超过数组的限制
if(col_index>=this[i].Size())
{
Print(__FUNCSIG__,": Error! Column number ",col_index," > row size ",i);
break; // 行将是未初始化对象
}
array[i]=this[i][col_index];
}
//--- 基于数组值创建CRow行
row=array;
}
//--- 结果
return(row);
}
//+------------------------------------------------------------------+
//| 两个矩阵的加法 |
//+------------------------------------------------------------------+
CMatrix CMatrix::operator+(const CMatrix & m)
{
//--- 通过矩阵的行数和列数
int cols=m.Cols();
int rows=m.Rows();
//--- 接收相加结果的矩阵
CMatrix res(rows);
//--- 矩阵大小必须匹配
if(cols!=Cols() || rows!=Rows())
{
//--- 无法相加
Print(__FUNCSIG__,": Failed to add two matrices, their sizes are different");
return(res);
}
//--- 辅助数组
double arr[];
ArrayResize(arr,cols);
//--- 通过行相加
for(int i=0;i < rows;i++)
{
//--- 写下数组中矩阵字符串的加法结果
for(int k=0;k < cols;k++)
{
arr[k]=this[i][k]+m[i][k];
}
//--- 将数组放在矩阵行
res[i]=arr;
}
//--- 返回矩阵相加结果
return(res);
}
//+------------------------------------------------------------------+
//| 两个矩阵的乘法 |
//+------------------------------------------------------------------+
CMatrix CMatrix::operator*(const CMatrix & m)
{
//--- 第一个矩阵的列数,通过矩阵的行数
int cols1=Cols();
int rows2=m.Rows();
int rows1=Rows();
int cols2=m.Cols();
//--- 接收相加结果的矩阵
CMatrix res(rows1);
//--- 矩阵应该协调
if(cols1!=rows2)
{
//--- 不能相乘
Print(__FUNCSIG__,": Failed to multiply two matrices, format is not compatible "
"- number of columns in the first factor
should be equal to the number of rows in the second");
return(res);
}
//--- 辅助数组
double arr[];
ArrayResize(arr,cols1);
//--- 在矩阵乘法中填写该行
for(int i=0;i < rows1;i++)// 通过行
{
//--- 重置接收数组
ArrayInitialize(arr,0);
//--- 通过行的元素
for(int k=0;k < cols1;k++)
{
//--- 利用m矩阵的k列的值用于CRow
CRow column=m.GetColumnAsRow(k);
//--- 两行相乘,在i-th元素写下矢量标量乘法的结果
arr[k]=this[i]*column;
}
//--- 将数组arr[]至于矩阵i-th行
res[i]=arr;
}
//--- 返回两个矩阵的产物
return(res);
}
//+------------------------------------------------------------------+
//| 赋值操作 |
//+------------------------------------------------------------------+
CMatrix *CMatrix::operator=(const CMatrix & m)
{
//--- 查找和设置行数
int rows=m.Rows();
ArrayResize(m_rows,rows);
//--- 填充我们传递矩阵行值的行
for(int i=0;i < rows;i++) this[i]=m[i];
//---
return(GetPointer(this));
}
//+------------------------------------------------------------------+
//| 矩阵的字符串表示 |
//+------------------------------------------------------------------+
string CMatrix::String(void) const
{
string out="";
int rows=Rows();
//--- 形成字符串的字符串
for(int i=0;i < rows;i++)
{
out=out+this[i].String()+"\r\n";
}
//--- 结果
return(out);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
相关参考
重载, 算术运算, 函数重载, 优先规则
# 1.5.5 外部函数描述
在另一个模块中定义的外部函数必须显式地描述。描述包括返回类型、函数名和输入参数序列。 在编译、构建或执行程序时,缺少这样的描述可能会导致错误。 当描述一个外部对象时,使用关键字 #import 导入说明的模块。
例如:
#import "user32.dll"
int MessageBoxW(int hWnd ,string szText,string szCaption,int nType);
int SendMessageW(int hWnd,int Msg,int wParam,int lParam);
#import "lib.ex5"
double round(double value);
#import
2
3
4
5
6
在 import 的帮助下,很容易对从外部 DLL 或编译的EX5库中调用的函数进行描述定义。 EX5 程序库被编译为 .ex5 文件,但它具有 library (库文件) 属性。 仅当函数以 export (导出) 修饰符 描述后才可以从 EX5 程序库中导入。
TIP
(智能交易*姚提示————意即,只有用了 export 描述后的 .ex5 文件才具有 库文件属性。)
请记住,DLL和 EX5库应该有不同的名称(不管它们位于什么目录),如果它们是一起导入的。 所有导入的函数都有对应于库的“文件名”的解析范围。
例如:
#import "kernel32.dll"
int GetLastError();
#import "lib.ex5"
int GetLastError();
#import
class CFoo
{
public:
int GetLastError() { return(12345); }
void func()
{
Print(GetLastError()); // 调用类方法
Print(::GetLastError()); // 调用 MQL5 函数
Print(kernel32::GetLastError()); // 从 kernel32.dll 里调用 DLL 库函数
Print(lib::GetLastError()); // 从 lib.ex5 里调用 EX5 库函数
}
};
void OnStart()
{
CFoo foo;
foo.func();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
参阅
重载, 虚拟函数, 多态
# 1.5.6 输出函数
在MQL5程序中,声明一个自定义函数时,如果使用了后修饰符 export 导出,即表示该函数可以在另一个MQL5程序中使用。 这样的函数叫做可输出函数,编译后可以被其它程序调用。
int Function() export
{
}
2
3
这个修饰符(export)会通知编译器将该ex5文件中的这个函数添加到导出的EX5函数输出表中。 只有具有这样一个修饰符的函数才能被其它MQL5程序访问(即具有“可见”的库文件属性)。 程序库属性通知编译程序EX5-文件是一个程序库,而编译程序会在EX5表头显示它。 所有计划输出的函数都要用输出修饰符标记。
相关参考
重载, 虚拟函数, 多态
# 1.5.7 事件处理函数
MQL5语言提供了一些处理预定义事件的函数(如 OnStart,OnInit,OnDeinit等等)。这些事件处理函数必须在MQL5程序中定义: 函数名、返回类型、参数组合(如果有的话), 它们的返回类型必须严格遵守事件处理程序函数的描述。 客户交易终端的事件处理程序通过函数的返回值类型和形式参数类型、来标识函数处理这个事件或那个事件。如果为相应的函数指定了与下面描述不符的形式参数, 或者为其指定了其它的返回类型,则不会将下列函数用作事件处理函数。
- OnStart
OnStart() 函数就是 启动 事件处理程序,运行脚本时自动生成。一定是空类型,无参数:
void OnStart();
对于OnStart()函数,可以指定返回类型为 int。(如果指定返回类型为 int,则需要用 return(0)语句。否则 编译 时会得到报警提示消息。)
- OnInit
OnInit() 函数是 初始化事件 处理程序。 必须是 空型 或者 整数型,无参数:
void OnInit();
初始化事件处理程序在 EA交易程序 或者 指标 下载后即时生成;这个事件不是为脚本生成的。OnInit()函数用于初始化。如果OnInit()返回值为整数型,非零的结果意味着初始化失败, 并生成 初始化失败事件(Deinit) ,和 初始化失败事件代码 REASON_INITFAILED 。 要优化EA交易的输入参数,推荐使用枚举值 ENUM_INIT_RETCODE 作为返回代码。这些值用于组织优化 的过程,包括选择最合适的测试代理。在EA交易程序的初始化期间,开始测试之前您可以使用 TerminalInfoInteger() 函数请求一个代理的配置和资源信息(如:CPU内核数量,空余内存等等)。根据所获得的信息,您可以在EA交易优化过程中选择允许或拒绝使用这个测试代理。
ENUM_INIT_RETCODE
| 标识符 | 描述 |
|---|---|
| INIT_SUCCEEDED | 成功初始化,可以继续测试EA交易。 |
这段代码与空值的意义相同 —— 在测试中EA交易已成功初始化。 |INIT_FAILED|初始化失败;由于非常严重的错误而无法继续测试。例如,未能创建EA交易工作所需的指标。 该返回值与非零值的意义相同 ---- 测试中初始化EA交易失败。测试给定的EA交易参数组将不会执行,代理可以接受任意新任务。 |INIT_PARAMETERS_INCORRECT|这个值意味着错误的输入参数组。包含这个返回代码的结果字符串在普通优化表中以红色突出显示。 接收到这个值后,该策略测试确实不会将这个任务传递给其他代理进行重试。 |INIT_AGENT_NOT_SUITABLE|在初始化期间没有错误,但出于某种原因,代理不适合测试。例如,没有足够的内存,没有 OpenCL 支持 ,等等。返回这段代码后,代理将不会收到任务,直到 这种优化结束。
空型OnInit() 函数代表初始化成功。
- OnDeinit
OnDeinit() 函数称为失败初始化,是初始化失败事件处理程序。必须是空型且有一个整型参数,参数为包括初始化失败原因代码的常量。如果声明不同类型,编译程序会发出警告消息,函数不可调用。对于脚本来说不会生成初始化失败事件,因此OnDeinit()函数不适用脚本。
void OnDeinit(const int reason);
在以下情况下EA交易 和 指标 会发生初始化失败Deinit事件:
• 再次初始化前,MQL5程序下的交易品种和图表周期发生变化; • 再次初始化前,输入参数发生变化; • MQL5程序卸载前。
- OnTick
只有当 EA程序附加到图表上后,收到一个新的报价时,才会产生一个 NewTick 事件。在自定义指示器或脚本中定义OnTick()函数是无效的,意即OnTick()函数不适用于自定义指标和脚本,因为 NewTick 事件不是为它们生成的。
NewTick 事件 只适用于 EA交易,但是却不意味着EA交易必定需要OnTick()函数,因为EA交易还会产生计时器事件,预定事件和图表事件。OnTick()声明时必须为空(void)型,无参数:
void OnTick();
- OnTimer
当发生计时器事件时会调用OnTimer()函数,该事件由系统计时器生成,仅用于EA交易和指标 ----不能用于脚本。函数EventSetTimer()接收该事件,当支持该事件发送通知消息时,需要设置事件发生的频率。
可以在EA交易程序中使用函数EventKillTimer()取消计时器事件。OnTimer()函数的类型必须为空(void)型,无参数:
void OnTimer();
建议在OnInit() 函数中调用EventSetTimer() 函数,而EventKillTimer() 函数可以在OnDeinit()中调用。
//+------------------------------------------------------------------+
//| 例 OnTimer() |
//+------------------------------------------------------------------+
// EA 的初始化函数中,调用 EventSetTimer() 来设置时间事件的频率
int OnInit()
{
EventSetTimer(3); // 设置频率为 3 秒一次
return(INIT_SUCCEEDED);
}
//+------------------------------------------------------------------+
//| EA 的卸载函数 |
//+------------------------------------------------------------------+
void OnDeinit(const int reason)
{
EventKillTimer(); // 结束计时器
}
void OnTimer()
{
Print("过了3秒" );
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
每个EA交易,每个指标都有其独自的计时器且仅通过它来接收计时器事件。如果创建了计时器但没有用EventKillTimer() 函数终止,那么一旦MQL5程序停止,则该计时器也会被强制终止。
- OnTrade
当交易事件发生时,该函数被调用,当你的帐户中挂单数量 OrdersTotal()、持有订单量 PositionsTotal()、历史订单数量 HistoryOrdersTotal() 和 历史交易数量 HistoryDealsTotal() 发生变化时,就会触发这个事件。当进行交易活动时(放置一个挂单、下单进场/平仓、停止设置、挂单触发等),历史订单、交易数量 和/或 当前订单或交易的数量会发生相应的变化。
TIP
( 智能交易*姚提示————注意,MT4 和 MT5 中,函数 OrdersTotal() 有很大的变化: MT4中, OrdersTotal() 用于统计当前帐户持单和挂单的合计数量。不分品种,不分挂单类型。并不支持函数 HistoryOrdersTotal(),HistoryDealsTotal() MT5中, OrdersTotal() 仅统计当前帐户中挂单的合计数量。不分品种,不分挂单类型。同时,并不支持函数 OrdersHistoryTotal()。如果要查看全部历史订单,请参考以下脚本)
void OnStart()
{
HistorySelect( 0,TimeCurrent()); // 首先选择历史时间范围,如从 最开始 到 当前
Print("HistoryOrdersTotal() = ",HistoryOrdersTotal()); // 所有订单,包含挂单
Print("HistoryDealsTotal() = ",HistoryDealsTotal()); // 所有成交的订单
}
void OnTrade();
2
3
4
5
6
7
当收到这个的事件时,(如果EA的交易策略条件所要求的话)用户必须在代码中独立地实现对交易帐户状态的验证。如果OrderSend()函数调用成功完成并返回true值,则这意味着交易服务器已经将订单放入到队列中执行,并将一个订单号分配给该订单。当服务器处理此订单时,将生成交易事件。如果用户记住了订单号, 将能够在 OnTrade() 事件处理过程中发现该订单号对应的订单发生了什么变化。
- OnTradeTransaction
在交易账户上执行一些明确的操作时,其状态发生变化。这样的行为包括:
• 来自客户端的任何MQL5应用程序使用OrderSend和OrderSendAsync函数发送的交易请求及其进一步执行要求;
• 通过终端图形界面发送的交易请求,并进一步执行;
• 挂单和停止服务器上的订单激活动作;
• 在交易服务器端执行操作。
这些交易事务执行操作的结果如下:
• 处理交易请求;
• 改变持仓订单的数量;
• 改变历史订单的数量;
• 改变历史交易的数量;
• 改变仓位。
例如,当发送一个被处理的市场购买订单时,会为账户创建一个适当的购买订单,然后执行订单并从持仓列表中删除订单,然后将其添加到订单历史,适当的交易也会被添加到历史并创建一个新的持仓。所有这些行动都是交易事务。在程序端到这种事务就是一个 TradeTransaction 事件。它会调用OnTradeTransaction 处理程序
例如,在发送市价做多(buy)单时,事件处理的操作是,为该账户创建一个适当的做多(buy)单,然后执行该订单并从挂单的列表中移除,之后将其添加到历史订单列表中,交易被添加到历史交易记录中,并创建一个新的持仓仓位。所有这些行为都是交易事务。当客户交易终端收到这样一个交易事务时,即是一个交易事务(TradeTransaction)事件。它会调用 OnTradeTransaction() 处理程序
void OnTradeTransaction(
const MqlTradeTransaction& trans, // 交易结构
const MqlTradeRequest& request, // 请求结构
const MqlTradeResult& result // 结果结构
);
2
3
4
5
处理程序包含三个参数:
• trans —— 该参数获得描述应用于交易账户的交易事务的 MqlTradeTransaction结构;
• request —— 该参数获得描述交易请求的MqlTradeRequest结构;
• result —— 该参数获得描述交易请求执行结果的MqlTradeResult结构。
最后两个 request 和 result 参数填充值仅用于 TRADE_TRANSACTION_REQUEST 类型事务,事务数据可以从 trans 变量的 type 参数接收。注意在这种情况下,trans 变量描述的交易事务被执行后,在 result 变量的 request_id 字段包含 request 交易请求的 ID。请求ID允许联系执行的操作(OrderSend 或 OrderSendAsync 函数调用)发送到 OnTradeTransaction() 该操作的结果。
从客户交易程序端手动 或 通过 OrderSend()/OrderSendAsync() 函数 发送的交易请求可以在交易服务器上生成几个连续的交易事务。但不保证这些交易事务会优先到达客户程序端。因此,开发您的交易算法时,您不必指望交易会一组接一组地到达。此外,交易可能在从服务器传递到客户交易终端的过程中会丢失。(英文版没有这句话)
• 所有类型的交易事务都在ENUM_TRADE_TRANSACTION_TYPE枚举中描述。
• 交易事务中描述的MqlTradeTransaction结构根据事务类型以不同的方式填充。例如,只有类型字段 (交易事务类型)必须为TRADE_TRANSACTION_REQUEST类型事务进行分析。OnTradeTransaction函数 (请求和结果)的第二个和第三个参数必须为额外的数据进行分析。有关更多信息,请参见"交易事务结 构"。
• 交易事务描述不提供关于订单,交易和持仓(如,评论)的所有可用的信息。OrderGet*,
HistoryOrder Get*,HistoryDealGet*和 PositionGet*函数应该用于获得扩展信息。
在为一个客户账户申请交易事务之后,它们始终被放置在程序终端交易事务队列中,按照它们产生的顺序,从这里一直发送到OnTradeTransaction入口点,以便到达客户交易终端。
当使用 OnTradeTransaction 处理程序通过EA程序处理交易事务时,程序端会继续处理新来的交易事务。因此,交易账户的状态可能在 OnTradeTransaction 操作过程中已经改变。例如,当MQL5程序处理添加新订单的事件时,它可能被执行,从持仓列表删除并移动到历史记录中。进一步来说,应用程序将被通知这些事件。
事务队列长度由1024个元素组成。如果 OnTradeTransaction 处理新事务太久,队列中的旧事务可能会被新的取代。
• 一般来说,没有准确的 OnTrade 和 OnTradeTransaction 调用数量的比例。一个 OnTrade 调用对应于一个或几个 OnTradeTransaction 调用。
• OnTrade 在适当的 OnTradeTransaction 调用之后被调用。
- OnTester
函数 OnTester() 是外部EA交易历史测试结束后自动生成的测试事件处理程序。用双型确定函数,无参数:
OnTester() 函数是测试员事件的处理程序,在对EA交易进行了历史数据测试之后,该事件自动生成。该函数必须用double类型定义,不带参数:
double OnTester();
该函数在 OnDeinit() 调用之前被调用,并且具有相同类型的返回值 ———— double。OnTester()只能在EA测试中使用。计算在输入参数的遗传优化中使用的自定义 max 准则的某个值。它的主要目的是计算某个值,用作遗传最优化自定义标准。
遗传优化中,生成结果用降序,例如从优化标准查看点,最佳结果是那些最大值(OnTester函数带进账户的最大自定义优化标准值)。这种情况下,最差值放在最后,或者排除,不参与下一步生成。
- OnTesterInit
OnTesterInit()函数是TesterInit事件的处理程序,它在EA交易策略测试的优化启动前自动生成。函数必须定义为void类型。它没有参数:
void OnTesterInit();
随着优化的开始,带有OnTesterDeinit()或OnTesterPass()处理程序的EA交易将自动加载到单独的终端图表中,其中包含测试仪中指定的符号和周期,并接收 TesterInit 事件。在开始优化之前,该功能用于EA交易初始化,以便进一步处理优化结果。
• TesterPass —— 该事件在接收到新的 数据帧 时生成。TesterPass事件使用OnTesterPass() 函数处理。优化期间,该处理程序的EA交易自动加载于测试器指定的交易品种和周期的独立程序端图表上,并在收到 数据帖 时接收TesterPass事件。 该函数用于"立即"动态处理 优化结果 无需等候完成。使用FrameAdd()函数添加 数据帧,该函数可以在单次通过结束后用OnTester() 处理程序调用。
- OnTesterDeinit
OnTesterDeinit() 是 TesterDeinit 事件的处理程序,它是EA交易策略测试优化结束后自动生成的。函数必须定义为void类型。它没有参数:
void OnTesterDeinit();
具有TesterDeinit()处理程序的EA交易在优化开始时自动加载到图表上,并在完成后接收TesterDeinit事伯。该函数用于所有优化结果的最终处理。
- OnBookEvent
OnBookEvent() 函数是 BookEvent 处理程序。当市场深度变化时,EA和自定义指标会生成BookEvent事件。它必须是void类型,并且有一个字符串类型的参数:
void OnBookEvent (const string& symbol);
要接收任意某一交易品种的 BookEvent 事件,只需使用 MarketBookAdd() 函数预先订阅该交易品种的这些事件即可。如果想取消接收某一个特定交易品种的 BookEvent 事件,调用 MarketBookRelease()。
与其他事件不同,BookEvent事件是被广播的。 这意味着如果一个EA交易使用 MarketBookAdd() 函数订阅接收 BookEvent 事件,则所有其它具有 OnBookEvent() 处理程序的EA都将会收到这个事件。 因此,有必要分析交易品种的符号名称,作为 const string& symbol 参数传递给处理程序。
- OnChartEvent
OnChartEvent()是一组 ChartEvent 事件的处理程序:
• CHARTEVENT_KEYDOWN ———— 当前图表窗口成为焦点时,有敲击键盘上的按钮时,触发此事件,参考例1;
• CHARTEVENT_MOUSE_MOVE ———— 鼠标移动事件和鼠标单击事件(如果CHART_EVENT_MOUSE_MOVE = true设置为图表);
• CHARTEVENT_OBJECT_CREATE ———— 创建图形对象的事件(如果CHART_EVENT_OBJECT_CREATE = true设置为图表);
• CHARTEVENT_OBJECT_CHANGE ———— 通过属性对话框更改对象属性的事件;
• CHARTEVENT_OBJECT_DELETE ———— 图形对象删除事件(如果CHART_EVENT_OBJECT_DELETE = true设置为图表);
• CHARTEVENT_CLICK ———— 鼠标单击图表事件;
• CHARTEVENT_OBJECT_CLICK ———— 鼠标单击属于图表的图形对象;
• CHARTEVENT_OBJECT_DRAG ———— 使用鼠标拖曳移动图形对象的事件;
• CHARTEVENT_OBJECT_ENDEDIT ———— 在LabelEdit图形对象的输入框中完成文本编辑事件;
• CHARTEVENT_CHART_CHANGE ———— 图表变化事件;
• CHARTEVENT_CUSTOM+n ———— 用户事件ID,取值范围是0-65535;
• CHARTEVENT_CUSTOM_LAST ———— 自定义事件的最后一个可接受的ID(CHARTEVENT_CUSTOM + 65535).
该函数只能在EA和指标中调用。该函数应具有4个参数,声明类据为空(void)类型:
void OnChartEvent(const int id, // 事件 ID
const long& lparam, // 长整型事件参量
const double& dparam, // 双精度事件参量
const string& sparam // 字符串事件参量
);
2
3
4
5
对于每种类型的事件,OnChartEvent() 函数的输入参数都有一定的值,用于处理此事件。通过这些参数传递的事件和值请参考下表:
| 事件 | id参数值 | lparam参数值 | dparam参数值 | sparam参数值 |
|---|---|---|---|---|
| 击键 | CHARTEVENT_KEYDOWN | 按键码 | 重复次数(用户控制按键后重复击键的次数) | 描述键盘按钮状态的位掩码的字符串值 |
| 鼠标事件 (如果属性 CHART_EVENT_MOUSE_MOVE =true 图表设置) | CHARTEVENT_MOUSE_MOVE | X 坐标 | Y 坐标 | 描述鼠标按钮状态的位掩码的字符串值 |
| 创建图解物件 (如果 CHART_EVENT_OBJECT_CREATE=true图表设置) | CHARTEVENT_OBJECT_CREATE | — | — | 创建的图解物件的名称 |
| 通过属性对话框改变物件属性 | CHARTEVENT_OBJECT_CHANGE | — | — | 更改的图解物件名称 |
| 删除图解物件 (如果 CHART_EVENT_OBJECT_DELETE=true 图表设置) | CHARTEVENT_OBJECT_DELETE | — | — | 删除的图解物件名称 |
| 鼠标单击图表 | CHARTEVENT_CLICK | X坐标 | Y坐标 | — |
| 鼠标单击属于图表的图解物件 | CHARTEVENT_OBJECT_CLICK | X坐标 | Y坐标 | 事件发生的图解物件名称 |
| 用鼠标移动图解物件 | CHARTEVENT_OBJECT_DRAG | — | — | 移动的图解物件名称 |
| 图解物件标签编辑输入框中完成文本编辑 | CHARTEVENT_OBJECT_ENDEDIT | — | — | 文本编辑完成的图解物件名称 |
| 图表更改事件 | CHARTEVENT_CHART_CHANGE | — | — | — |
| N下的用户ID | CHARTEVENT_CUSTOM+N | 通过函数EventChartCustom()设置值 | 通过函数EventChartCustom() 设置值 | 通过函数EventChartCustom() 设置值 |
//+------------------------------------------------------------------+
//| 例1. ChartEvent function 键盘事件 |
//+------------------------------------------------------------------+
void OnChartEvent(const int id,
const long &lparam,
const double &dparam,
const string &sparam)
{
//--- 检测敲击键盘的事件
if(id == CHARTEVENT_KEYDOWN)
{
Print ("键盘上有敲击按键的事件发生");
Print ("敲击的按键是",lparam);
Print ("重复次数为",dparam );
Print ("按键状态的位掩码的字符串",sparam);
}
}// 事件结束
void OnTick()
{
}
//....................................................................
/*
此EA附加到图表上之后,只要当前图表为焦点状态,键盘上按一次键,即可在EA标签看到如下类似结果
键盘上有敲击按键的事件发生
敲击的按键是71
重复次数为1.0
按键状态的位掩码的字符串34
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
//+------------------------------------------------------------------+
//| 例2. ChartEvent function 鼠标事件 |
//+------------------------------------------------------------------+
void OnChartEvent(const int id,
const long &lparam,
const double &dparam,
const string &sparam)
{
//--- 检测鼠标左键点击事件 /////////////////////////////////////////
if(id==CHARTEVENT_CLICK)
{
Print ("鼠标光标的X坐标",lparam);
Print ("鼠标光标的Y坐标",dparam );
Print ("鼠标按钮状态的位掩码的字符串",sparam);
}
}// 事件结束
void OnTick()
{
}
//....................................................................
/*
此EA附加到图表上之后,只要在图表上点击一次鼠标左键,即可在EA标签看到如下类似结果
鼠标光标的Y坐标298.0
鼠标光标的X坐标774
鼠标按钮状态的位掩码的字符串
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
OnCalculate
OnCalculate()函数只能在 自定义指标中 调用,通过Calculate事件计算指标值是必须的。通常情况下,当某个交易品种收到一个新的报价时,即计算指标的值。该指标不需要附加到交易品种的任何价格图表上。
OnCalculate()函数必须具有返回值,类型为 int。有两种可能的声明方式。在一个指标内,你不能同时使用OnCalculate()函数的两种版本的声明方式。
第一个版本的格式用于那些只需要一个数据缓冲区中计算的指标。例如 自定义移动平均线。
int OnCalculate (const int rates_total, // 价格[] 数组的大小
const int prev_calculated, // 前一次调用处理的柱
const int begin, // 有效数据起始位置
const double& price[] // 计算的数组
);
2
3
4
5
price[]数组中,可以传送 时间序列 或 另外一些指标数组计算的结果。要确定price[]数组中索引的方向,请调用ArrayGetAsSeries()。为了不依赖于默认值,您必须无条件地调用ArraySetAsSeries()函数来处理这些数组,这是期望的结果。
当启动 指标 时,用户可以在“参数”选项卡中选择所需的 时间序列 或 一个指标 的计算结果序列作为参数传递给price[]数组。为此,您应该在“应用到”字段的下拉列表中指定必要的选项。
要从其它 MQL5程序中接收某个 自定义指标 的值,需要使用 iCustom() 函数,该函数将为后续的操作返回该指标的处理结果。您还可以指定适当的price[]数组 或 其他指标的处理结果。此参数应在 自定义指标 的输入变量列表中最后传输。
示例:
void OnStart()
{
//---
string terminal_path=TerminalInfoString(STATUS_TERMINAL_PATH);
int handle_customMA=iCustom(Symbol(),PERIOD_CURRENT, "Custom Moving Average",13,0,
MODE_EMA,PRICE_TYPICAL);
if(handle_customMA>0)
Print("handle_customMA = ",handle_customMA);
else
Print("Cannot open or not EX5 file '"+terminal_path+"\\MQL5\\Indicators\\"+"
Custom Moving Average.ex5'");
}
//======================================================
/*
此段代码有很多错误
TerminalInfoString()函数的参数,STATUS_TERMINAL_PATH 是错误的。正确的标识符是 T
ERMINAL_PATH ,得到的结果是 交易客户端的启动路径;
如果是 MT5 终端,自定义指标 Custom Moving Average.mq5 文件是保存在 Examples 文件夹中的,
因此正确的路径应该是 “Examples\\Custom Moving Average”
如果是 MT4 终端,自定义指标的名称是 Custom Moving Averages.mq4 ,注意有个s , 另该指标与
MT5 中的指标,在调用时,参数略有差异.
此代码是一个脚本代码.
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
在这个示例中,iCustom()函数的最后一个参数是PRICE_TYPICAL(从价格常量(ENUM_APPLIED_PRICE)中枚举),表示 自定义指标 计算的价格应该是 典型价格(最高价+最低价+收盘价)/3。如果没有指定这个参数,则指标基于 收盘价 的值进行计算,例:每根K线的收盘价。
另一个示例显示了将 指标 处理程序作为最后一个参数来指定price[]数组,在iCustom()函数的描述中给出。
第二个版本的格式适用于所有其它指标,计算更多的时间序列
int OnCalculate (const int rates_total, // 输入时间序列大小
const int prev_calculated, // 前一次调用中处理的K线柱
const datetime& time[], // 时间 序列数组
const double& open[], // 开盘价 序列数组
const double& high[], // 最高价 序列数组
const double& low[], // 最低价 序列数组
const double& close[], // 收盘价 序列数组
const long& tick_volume[], // 报价交易量 序列数组
const long& volume[], // 真实交易量 序列数组
const int& spread[] // 点差 序列数组
);
2
3
4
5
6
7
8
9
10
11
参数open[], high[], low[] 和close[] 由当前时间周期图表上的开盘价、最高和最低价、收盘价数组组成。参数time[]包括开盘时间值数组,参数spread[]包含一个历史点差的数组(如果为交易安全性提供了任何点差)。参数volume[] 和tick_volume[] 分别包括报价交易量和真实交易量的历史记录。
确定time[]、 open[]、 high[]、 low[]、close[]、tick_volume[]、volume[] 和 spread[]这些数组的索引方向, ,需要调用ArrayGetAsSeries()函数。若不想依赖默认值,需要无条件的调用函数ArraySetAsSeries()用于工作的数组。
第一个参数rates_total限制了用于计算指标的K线数量,对应于图表中可用的K线数量。
我们应该注意到OnCalculate()的返回值与第二个参数 prev_calculate 之间的连接。在函数调用期间,参数prev_calculate包含了上次调用OnCalculate()时返回的值。这使得计算 自定义指标 采用了经济的算法,那些自上次运行以来没有发生变化的K线值可以避免重复计算。
为此,通常可以返回rates_total参数的值,该参数包含当前函数调用中的K线数量。如果自从上次调用函数OnCalculate()以来,图表中的报价数据发生了变化(下载的历史数据较深或填充了空白历史数据),那么参数prev_calculated 的值将被终端设置为零。
注:如果OnCalculate()返回结果为零,那么指标值将不会显示在客户端的数据窗口。
为了更好地理解,启动附加下面这个 指标 是很有用的,代码如下
指标示例:
#property indicator_chart_window
#property indicator_buffers 1
#property indicator_plots 1
//---- 图的线
#property indicator_label1 "Line"
#property indicator_type1 DRAW_LINE
#property indicator_color1 clrDarkBlue
#property indicator_style1 STYLE_SOLID
#property indicator_width1 1
//--- 指标缓冲区
double LineBuffer[];
//+------------------------------------------------------------------+
//| 自定义指标初始化函数 |
//+------------------------------------------------------------------+
int OnInit()
{
//--- 指标缓冲区绘图
SetIndexBuffer(0,LineBuffer,INDICATOR_DATA);
//---
return(INIT_SUCCEEDED);
}
//+------------------------------------------------------------------+
//| 自定义指标重复函数 |
//+------------------------------------------------------------------+
int OnCalculate(const int rates_total,
const int prev_calculated,
const datetime&& time[],
const double& open[],
const double& high[],
const double& low[],
const double& close[],
const long& tick_volume[],
const long& volume[],
const int& spread[])
{
//--- 获得当前交易品种和图表周期的有效柱数
int bars=Bars(Symbol(),0);
Print("Bars = ",bars,", rates_total = ",rates_total,", prev_calculated = ",prev_calculated);
Print("time[0] = ",time[0]," time[rates_total-1] = ",time[rates_total-1]);
//--- 为下次调用返回prev_calculated值
return(rates_total);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#property indicator_chart_window // 这个指标显示在主图表窗口
#property indicator_buffers 1 // 这个指标的缓冲区数量为 1 个
#property indicator_plots 1
// 这个指标的 图解系列 数目(就是画多少种东东,如线、箭头、柱子等),为 1
//---- 关于这个 指标 画线的样式
#property indicator_label1 "Line" // 这个指标在 数据窗口 中显示 图解 的标签文字,为 Line
#property indicator_type1 DRAW_LINE
// 这个指标画线的类型。(就是画什么东东,如线、箭头、柱子等),指定为 DRAW_LINE 画线
#property indicator_color1 clrDarkBlue // 这个指标画线的颜色,为 clrDarkBlue
#property indicator_style1 STYLE_SOLID // 这个指标画线的样式,为 STYLE_SOLID 实线
#property indicator_width1 1 // 这个指标画线的粗细,为 1
//--- 指标缓冲区
double LineBuffer[]; // 为 缓冲区 声明了一个数组
//+------------------------------------------------------------------+
//| 自定义指标初始化函数 |
//+------------------------------------------------------------------+
int OnInit()
{
//--- 指标缓冲区绘图
SetIndexBuffer(0,LineBuffer,INDICATOR_DATA); // 绑定 缓冲区 与 数组
//---
return(INIT_SUCCEEDED);
}
//+------------------------------------------------------------------+
//| 自定义指标迭代函数 |
//+------------------------------------------------------------------+
int OnCalculate(const int rates_total,
const int prev_calculated,
const datetime&& time[],
const double& open[],
const double& high[],
const double& low[],
const double& close[],
const long& tick_volume[],
const long& volume[],
const int& spread[]
)
{
//--- 获得当前交易品种,当前时间周期图表上的有效K线柱数
int bars=Bars(Symbol(),0);
Print("K线数量Bars = ",bars,
", 总计K线数量rates_total = ",rates_total,
", 上次计算的结果prev_calculated = ",prev_calculated
);
Print("当前时间time[0] = ",TimeToString(time[0],TIME_SECONDS),
"上一根K线的时间time[rates_total-1] = ",TimeToString(time[rates_total-1],TIME_SECONDS)
);
//--- 为下次调用返回prev_calculated值tal
for(int i=prev_calculated;i < rates_to;i++)
{
LineBuffer[i]=close[i]; //缓冲区数组 赋值
}
return(rates_total);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
另见
运行程序 ,客户端事件,工作事件
# 1.6 变量
变量声明
变量必须在使用之前声明。使用唯一的名称来标识变量。要声明一个变量,必须指定其类型和唯一名称。变量声明不是一个语句。
基本类型如下:
- 字符型(char),短整型(short),整型(int),长整型(long),无符号字符型(uchar),无符号短整型(ushort),无字符整型(uint),无符号长整型(ulong) ---- 整数;
- 颜色型 ---- 代表RGB-颜色的整数;
- 日期时间型 ----日期和时间,自1970年1月1日起无符号整数包括的秒数;
- 布尔型 ---- 布尔值的true 和 false;
- 双精度数字型 ---- 带小数点的双精度数字;
- 浮点型 ---- 带小数点的单精度数字;
- 字串符型 ---- 就是字符串。
示例:
string szInfoBox;
int nOrders;
double dSymbolPrice;
bool bLog;
datetime tBegin_Data = D'2004.01.01 00:00';
color cModify_Color = C'0x44,0xB9,0xE6';
2
3
4
5
6
复杂或复合类型: 结构是使用其他类型构造的组合数据类型。
struct MyTime
{
int hour; // 0-23
int minute; // 0-59
int second; // 0-59
};
...
MyTime strTime; // 预先声明了一个数据类型结构为 MyTime
// 声明了一个变量MyTime,类型为 MyTime
2
3
4
5
6
7
8
9
在声明 结构 类型之前,你不能声明 结构类型 的 变量。
数组
数组是同一种类型数据的索引序列,即相同类型的数据被顺序标注起来,就是一个数组:
int a[50]; // 50个整数的组成的一个一维数组
double m[7][50]; // 由7个数组组成的二维数组,每个数组都由50个数字组成。
MyTime t[100]; // 数组包含结构元素,例如 MyTime
2
3
数组的索引值只能是整数。MQL5语言中不允许超过四维数组。数组元素的编号从0开始。意即,一维数组的最后一个元素的索引数字是该数组的大小值减1。假设,我们想要调用上例中的数组a[50]其中最后的一个元素,正确的形式是 a [49]。同样我们来关注多维数组:维度的索引值也是从0开始,到数线维度大小-1 为止。上例中的二维数组m[7][50]的最后一个元素将以m[6][49]的形式出现。
静态数组不能表示时间序列,例如ArraySetAsSeries()从结束到开始都设置了对数组元素的访问,不能应用于它们。如果您想要提供对数组的访问,就像在时间序列中一样,可以使用动态数组对象。
如果试图访问超出数组范围的元素,执行的子系统将生成一个严重错误,程序就会停止(编译也无法通过,会收到错误消息)。
访问权限修饰符
访问权限修饰符定义编译器如何访问变量,结构成员 或者 类。
const修饰符将一个变量声明为象一个常量一样对待,即表示在运行期间并不允许更改此变量的值。变量声明时允许独自初始化。
int OnCalculate (const int rates_total, // price[] 数组的大小
const int prev_calculated, // 上一次调用OnCalculate()时处理的K线数
const int begin, // 有效数据起始位置
const double& price[] // 数组计算
);
2
3
4
5
若要访问 结构 中的成员 和 类,需要使用以下修饰符:
• 公用限定符public ---- 允许自由的无限制访问变量或者类方法
• 受保护限定符protected ---- 允许从这个类方法 或者 公共继承类方法中访问。其他访问是不可能的
• 私人限定符private ---- 允许对 变量 和 类方法 的访问仅来自同一个类的方法。
• 虚拟限定符virtual ---- 仅应用于类方法(不适用于结构方法)并且告诉编译器这个方法置于类虚拟方法表格中。
存储类
有三个存储类:静态、输入和外部。存储类的这些修饰符显式地指示编译器,在预先分配的内存区域(称为全局池)中分配相应的变量。此外,这些修饰符表示变量数据的特殊处理。如果在本地级别声明的变量不是静态变量,则在程序堆栈中自动分配该变量的内存。为非静态数组分配内存的过程也会自动执行,当超出块的可见性区域时,该数组将被声明。
另见
数据类型、类型的封装和可扩展性、变量的初始化、变量的可见性范围和生命周期、创建和删除对象、类的静态成员
# 1.6.1 局部变量
在函数内声明的变量是局部变量。局部变量的范围仅限于声明它的函数范围。局部变量可以通过任何表达式的结果初始化。每次调用函数都会初始化局部变量。局部变量存储在相应函数的内存区域中。
int somefunc()
{
int ret_code=0;
...
return(ret_code);
}
2
3
4
5
6
局部变量的范围是整个程序中的一个部分,表示在这个部分的范围中,变量是可以被引用的。在一个程序代码块内部声明的变量(在内部级别),则这个代码块就是这个变量的范围。程序代码块范围是指以变量声明开始,以最后的右花括号结束。
在函数开始时声明的局部变量也有块的范围,以及函数参数也是局部变量。任何程序代码块内部都可以包含变量声明。如果程序代码块嵌套,外部程序代码块中的变量名与内部程序代码块中的变量名同名,则外部程序代码块中的变量名将被隐藏,直到程序内部代码块的操作结束。 (注:在MT4中,不允许有同名的局部变量。编译时会出现错误。)
示例:
void OnStart()
{
//---
int i=5; // 声明了一个局部变量
{
int i=10; // 在代码块中声明了一个局部变量,并且与之前的变量i 同名
Print("在代码块内部的i(In block i) = ",i); // 结果是 i=10;
}
Print("在代码块外部的i(Outside block i) = ",i); // 结果是 i=5;
}
//注:在MT4中,不允许有同名的局部变量。编译时会出现错误。
//注: 在MT5中,编译时也会出现 警告 错误。
声明为静态的局部变量同样具有程序代码块的范围,尽管自程序启动以来它们就存在。
2
3
4
5
6
7
8
9
10
11
12
13
堆栈
在每个MQL5程序中,都会在内存中分配一个称为 堆栈 的特殊区域,用于存储函数自动创建的局部变量。为所有函数分配的堆栈,其默认大小为1Mb。在EA和脚本中,可以使用预处理程序编译指令 #property stacksize程序属性(以字节为单位设置堆栈大小)来管理堆栈大小,默认情况下为堆栈分配8Mb的内存。
静态局部变量存储在与其它静态变量和全局变量相同的存储空间里 ---- 在一个特殊的内存区域,它与 堆栈 是独立分开的。动态创建的变量也使用独立于堆栈的内存区域。
随着每个函数的调用,堆栈上的内存空间被分配给函数内部的非静态变量。退出函数后,这部分内存空间可被再次使用。
如果从第一个函数调用第二个函数,则第二个函数会从剩余的 堆栈 内存空间中占用所需的大小。因此,当运用包含的函数时,每个函数将依次占用 堆栈 的内存空间。这可能导致在一个函数调用期间内存不足,这种情况称为 堆栈溢出。
因此,对于大型的本地数据,您应该更好地使用动态内存 —— 当进入一个函数时,在系统中(new、ArrayResize())分配本地所需的内存,之后,在退出该函数时,释放内存(delete,ArrayFree())。
另见
数据类型, 类型密封和扩展,变量初始化, 可见范围和变量使用期, 创建和删除对象
# 1.6.2 形式参数
传递给函数的参数是局部的。如局部变量一样,其可见范围是函数块内部。形式参数的名称,不能与外部变量以及在函数内部定义的局部变量的名称相同。可以在函数内部给形式参数赋值。但是,如果在函数声明时,对一个形式参数使用了const修饰符,则表示这个形式参数的值在函数内不能被更改。
示例:
void func(const int x[], double y, bool z)
{
if(y > 0.0 && !z)
Print(x[0]);
...
}
2
3
4
5
6
形式参数可以由常量初始化。在这种情况下,初始化值被认为是默认值。这个被初始化的形式参数,之后的形式参数,也必须初始化。
示例:
void func(int x, double y = 0.0, bool z = true)
{
...
}
2
3
4
调用这样的函数时,在传递形式参数的时候,可以省略已经被初始化过的形式参数,取代它们的是默认值。
示例:
void func(const int x[], double y, bool z)
{
if(y > 0.0 && !z)
Print(x[0]);
...
}
2
3
4
5
6
形式参数可以由常量初始化。在这种情况下,初始化值被认为是默认值。这个被初始化的形式参数,之后的形式参数,也必须初始化。
示例:
void func(int x, double y = 0.0, bool z = true)
{
...
}
func(123, 0.5);
2
3
4
5
简单类型的形式参数是按值传递。意即,在 被调用 的函数中,修改对应该类型的局部变量的值,不会反映在 调用 函数中。任何数组和结构类型数据都是通过引用方式传递的。如果想要禁止修改数组和结构内容,那么在声明这些类型的形式参数时,必须使用const修饰符。
通过引用方式传递简单类型的形式参数也是可行的。在这种情况下, 修改的这样的形式参数的值将影响到 调用 函数中对应的变量。为使用 引用方式 传送参数,数据类型后跟随一个符号 & 。
示例:
void func(int& x, double& y, double& z[])
{
double calculated_tp;
...
for(int i=0; i < OrdersTotal(); i++)
{
if(i == ArraySize(z))
break;
if(OrderSelect(i)==false)
break;
z[i]=OrderOpenPrice();
}
x=i;
y=calculated_tp;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
使用引用方式 传递的形式参数不能进行初始化默认值。
函数的形式参数最多不可以超过64个。
另见 输入变量 ,数据类型, 类型密封和扩展,变量初始化, 可见范围和变量使用期, 创建和删除对象
# 1.6.3 静态变量
声明变量时,用修饰符 static 定义了存储类型的变量称为静态变量。静态修饰符写在数据类型之前。
示例:
int somefunc()
{
static int flag=10;
...
return(flag);
}
2
3
4
5
6
静态变量可以通过对应于其类型的常量或常量表达式进行初始化,这一点与简单的局部变量不同,简单的局部变量可以用任何表达式初始化。
静态变量存在于整个程序执行的时期,只有在调用了专门的函数OnInit()之后才初始化一次。如果没有指定初始值,静态存储类的变量将取零为初始值。
在函数内部声明局部变量时,如果也使用了修饰符 static,那么该局部变量在整个函数生命周期内都会保留其值。当下次调用该函数时,局部变量的值仍然是上次调用该函数时的值。
除了函数的形式参数外,程序代码块中的任何变量都可以定义为静态变量。如果局部变量声明时,没有使用静态修饰符 static,则在程序堆栈中自动分配该变量的内存空间。
示例:
int Counter()
{
static int count;
count++;
if(count%100==0) Print("Function Counter has been called ",count," times");
return count;
}
void OnStart()
{
//---
int c=345;
for(int i=0;i < 1000;i++)
{
int c=Counter();
}
Print("c =",c);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
另见
数据类型, 类型密封和扩展,变量初始化, 可见范围和变量使用期, 创建和删除对象, 静态类成员
# 1.6.4 全局变量
在函数描述之外声明的变量,即为全局变量。全局变量的定义与函数相同,即意味着,它们不是任何程序代码块中的局部变量。
示例:
int GlobalFlag=10; // 全局变量
int OnStart()
{
...
}
2
3
4
5
全局变量的范围是整个程序。全局变量可以被程序中定义的所有函数访问。如果它的值没有被定义,初始值为零。全局变量只能通过与它的类型相对应的常量或常量表达式来初始化。
全局变量只在程序加载到客户端内存并在第一次处理Init事件之前初始化一次。对于表示类对象 的全局变量,在初始化过程中调用相应的构造函数。在脚本中,全局变量在处理Start事件之前进行初始化。
注意:请不要把在程序代码中声明的全局变量 与 客户端全局变量 相混淆。后者是指使用GlobalVariable ...()函数访问的客户端全局变量。
另见 数据类型, 类型密封和扩展,变量初始化, 可见范围和变量使用期, 创建和删除对象
# 1.6.5 输入变量
声明外部变量时,用修饰符 input 定义为输入存储类型的变量称为输入变量。输入修饰符写在数据类型之前。在MQL5程序中不能更改带有输入修饰符的外部变量,这些变量只能用于读取。输入变量的值只能在程序属性窗口中由用户输入来修改。外部变量总是在调用OnInit()之前立即重新初始化。
示例:
//--- 输入参量
input int MA_Period=13;
input int MA_Shift=0;
input ENUM_MA_METHOD MA_Method=MODE_SMMA;
2
3
4
输入变量决定一个程序的输入参数。你可以在程序的属性窗口看到它们。
输入标签中可以通过其他方法显示输入参数名。使用字符注解,放在同行输入参数描述后。因此对于用户来说,与名字匹配的参数更容易理解。
还有另一种方法来设置客户端 输入 标签中各个参数的显示样式。为此,在声明 输入变量 的同一行中,对输入参数的作用写一个简短的描述字符串作为代码注释。通过这种方式,可以让用户更容易理解 输入 参数的名称和其代表的功能。
示例:
//--- 输入参量
input int InpMAPeriod=13; // 均线的周期
input int InpMAShift=0; // 均线的偏移量
input ENUM_MA_METHOD InpMAMethod=MODE_SMMA; // 均线的类型
2
3
4
MT5客户端的 输入 标签中的显示样式(不适用于MT4客户端)
注意:复杂类型的数组和变量不能作为输入变量。 注意:输入变量的注释字符串长度不能超过63个字符。
MQL5程序调用自定义指标时传递参数
用iCustom()函数访问自定义指标。其名后,参数要与该指标声明的输入变量严格一致。如果参数少于变量,缺失的参数要在变量声明时用特殊值填满。
使用iCustom()函数调用自定义指标时。在自定义指标的名称之后,参数应该严格按照这个自定义指标声明的输入变量一一对应。如果参数的数量小于被调用的自定义指标的输入变量,那么缺失的参数将被在变量声明中指定的值填满。
如果自定义指标使用的是OnCalculate()函数的第一个版本格式(即,该指标是使用相同的数据数组计算的,那么,在调用这个自定义指标时,应该使用ENUM_APPLIED_PRICE值或另一个指标的句柄作为最后一个参数。所有与输入变量对应的参数必须清楚地显示出来。
枚举型数据作为输入参数
MQL5中不仅提供了内置的枚举型常量,还可以将用户定义的枚举型变量用作输入参数(MQL5程序的输入参数)。例如,我们可以创建枚举型变量dayOfWeek,用来描述一周的天数,并使用输入变量指定一个星期内的某一天,这是更常见的方式,而不是用数字来表示。
示例:
#property script_show_inputs
//--- 一周内每天
enum dayOfWeek
{
S=0, // 周日
M=1, // 周一
T=2, // 周二
W=3, // 周三
Th=4, // 周四
Fr=5, // 周五,
St=6, // 周六
};
//--- 输入参量
input dayOfWeek swapday=W;
2
3
4
5
6
7
8
9
10
11
12
13
14
为了让用户能够在脚本启动时从属性窗口中选择一个需要的值,我们使用预处理命令#property script_show_inputs。当我们启动该脚本时,可以从列表中选择变量dayOfWeek枚举的值之一。我们启动 EnumInInput脚本,然后点击 输入参数 标签。默认情况下,变量swapday的值是周三(3日利息),但是我们可以指定任何其他值,并使用此值来更改程序的操作。
枚举型数据的元素数量是有限的。为了选择输入值,需要使用下拉列表。枚举数据每个元素的助记符名称显示在列表中。如果助记符名称与注释相关联,如本例所示,则 注释 显示在下拉列表中。
dayOfWeek枚举的每个值都具有一个数字值,从0到6,但是在参数列表中,将显示为每个值的注释。这为编写具有清晰描述输入参数的程序提供了额外的灵活性。
变量修饰符sinput
带有输入修饰符 input 的变量不仅可以让用户在启动程序时设置更改外部参数的值,并且在策略测试器中优化参数时也是必需的。除了字符串类型的输入参数之外,其它类型的输入变量都可以用于优化。
有时在测试EA时,需要在所有传递的参数中排除一些外部程序参数。这种情况下,就需要用到 sinput 内存修饰符。 sinput代表外部静态变量声明(sinput = 静态输入)。 这意味着在EA程序代码中会出现以下声明
sinput int layers=6; // Number of layers(层数)
上例中的格式 等同于 下列完整格式的声明
static input int layers=6; // Number of layers(层数)
用sinput修饰符声明的变量是MQL5程序的一个输入参数。 启动程序时可以更改此参数的值。 但是,这个变量不用于输入参数的优化。 换句话说,当搜索符合指定条件的最佳参数集时,其值不被列举。
上面所示的EA交易有5个外部参数。“Number of layers(层数)”声明时为 外部静态输入变量,并输入值等于6。交易策略优化期间该参数不能改变。我们可以指定必要的值用于进一步使用。初始值(Start)、每次增加(Step)和终止值(Stop)字段都不可用于这样的变量参数。(在中文版MT5中,对应的字段是 开始、阶段和停止)
因此,在为变量指定了sinput修饰符后,用户将无法优化此参数。 换句话说,在优化过程中,终端用户将无法在策略测试器中为其指定范围内的自动枚举设置初始值和最终值。
但是,这个规则有一个例外:使用ParameterSetRange()函数,可以在优化任务中改变sinput变量。 这个函数专门用于程序控制任何输入变量(包括声明为静态输入的输入变量)的可用值集。 ParameterGetRange()函数允许在优化启动时(在OnTesterInit()处理程序中)接收输入变量值,并重置一个变化步长值和一个范围,在这个范围内将优化参数值进行枚举。
通过这种方式,将sinput修饰符和两个与输入参数一起工作的函数结合在一起,可以创建一个灵活的规则来设置依赖于另一个输入参数值的输入参数的优化间隔。
另见 iCustom(),枚举型,程序属性
# 1.6.6 外部变量
extern关键字用于把变量声明为具有全局使用范围的静态存储类型变量。从程序启动开始,这些变量即存在,并且在程序启动后立即对它们分配内存空间和进行初始化。
您可以创建包含多个源文件的程序;在这种情况下,需要直接使用预处理 # include指令。具有相同类型和同名的外部变量声明,可以存在于一个项目的多个不同源码文件中。
在编译整个项目时,具有相同类型和名称的所有外部变量都与全局变量池的一部分内存空间相关联。外部变量对于单独编译的源文件非常有用。外部变量可以被初始化,但只能初始化一次 —— 禁止具有相同类型和相同名称的外部变量被多次初始化。
另见 数据类型, 类型密封和扩展,变量初始化, 可见范围和变量使用期, 创建和删除对象
# 1.6.7 变量初始化
任何变量在声明定义时都可以初始化。如果变量没有显性初始化,其值可能为任何值。不可使用隐性初始化。
全局变量和静态变量只能由相应类型的常量或常量表达式初始化。局部变量可以由任何表达式初始化,而不仅仅是一个常量。
每个程序中的全局变量和静态变量只会执行一次初始化。但局部变量,在每次调用相应函数时,都会进行一次初始化。
示例:
int n = 1;
string s = "hello";
double f[] = { 0.0, 0.236, 0.382, 0.5, 0.618, 1.0 };
int a[4][4] = { {1, 1, 1, 1}, {2, 2, 2, 2}, {3, 3, 3, 3}, {4, 4, 4, 4 } };
//--- 来自俄罗斯方块
int right[4]={WIDTH_IN_PIXELS+VERT_BORDER,WIDTH_IN_PIXELS+VERT_BORDER,
WIDTH_IN_PIXELS+VERT_BORDER,WIDTH_IN_PIXELS+VERT_BORDER};
//--- 零值结构所有字段的初始化
MqlTradeRequest request={0};
2
3
4
5
6
7
8
9
数组元素的值列表必须用花括号括起来。初始化时省略过去的值被认为等于零。带有成员或序列的变量(如数组类型、结构类型等)在初始化时必须至少有一个值:该值被赋于序列中第一个元素,而之后省略的元素被认为等于零。
如果在声明一个数组型变量时,未指定数组的大小,则编译器会根据初始化序列的大小来确定。多维数组不能被一维序列(没有额外的花括号的序列)初始化,除非是这样,只有一个初始化元素被指定(通常为零)。
数组(包括声明为局部变量的数组)只能由常量初始化。
示例:
struct str3
{
int low_part;
int high_part;
};
struct str10
{
str3 s3;
double d1[10];
int i3;
};
void OnStart()
{
str10 s10_1={{1,0},{1.0,2.1,3.2,4.4,5.3,6.1,7.8,8.7,9.2,10.0},100};
str10 s10_2={{1,0},{0},100};
str10 s10_3={{1,0},{1.0}};
//---
Print("1. s10_1.d1[5] = ",s10_1.d1[5]);
Print("2. s10_2.d1[5] = ",s10_2.d1[5]);
Print("3. s10_3.d1[5] = ",s10_3.d1[5]);
Print("4. s10_3.d1[0] = ",s10_3.d1[0]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
对于结构类型,允许变量分批的初始化,静态数组(隐式地设置大小)也一样。您可以初始化一个或多个结构或数组的第一个元素,
对于结构类型变量的部分初始化,以及静态数组(具有隐式设置大小)。在这个例子中,其他元素将被初始化为零。
另见 数据类型, 类型密封和扩展, 可见范围和变量使用期, 创建和删除对象
# 1.6.8 变量的可见范围和使用期
变量有两种基本范围:局部范围和全局范围。
在所有函数外部声明的变量具有全局范围。可以在程序的任何地方访问这些变量。这些变量位于内存的全局池中,因此它们的生命周期与程序的生命周期相一致。
内部变量声明属于局部范围。这种变量外部不可见(因此无法得到)。大部分局部变量声明都是一个函数内声明的。局部变量声明位于存储器中,使用期同于函数使用期。
在一段程序代码块(程序代码中被包含在一对花括号中的一部分代码)中声明的变量属于局部范围。这样的变量在代码块之外是不可见的(因此也是不可用的),因为变量是在该代码块中声明的。局部变量声明最常见的例子是在自定义函数中声明的变量。声明的局部变量位于函数的堆栈空间中,而该变量的生命周期等于该函数的生命周期。
局部变量范围在存储器中声明,也可以在其他存储器以同名声明;也可以高级别声明,乃至全局范围。
由于局部变量的范围仅仅是是声明它的代码块内部(即,从声明变量开始 到 该代码块的结束标识符右花括号结束),所以可以在其它代码块中声明具有同名的变量;同样也可以在更高级别的代码块中 或/和 全局范围中声明同名的变量。(但并不建议这样做,用不同的变量名使程序代码更具可读性。)
示例:
void CalculateLWMA(int rates_total,int prev_calculated,int begin,const double &price[])
{
int i,limit;
static int weightsum=0;
double sum=0;
//---
if(prev_calculated==0)
{
limit=MA_Period+begin;
//--- 为第一限价柱设置空值
for(i=0; i < limit; i++) LineBuffer[i]=0.0;
//--- 首先计算明显值
double firstValue=0;
for(int i=begin; i < limit; i++)
{
int k=i-begin+1;
weightsum+=k;
firstValue+=k*price[i];
}
firstValue/=(double)weightsum;
LineBuffer[limit-1]=firstValue;
}
else
{
limit=prev_calculated-1;
}
for(i=limit;i < rates_total;i++)
{
sum=0;
for(int j=0; j < MA_Period; j++) sum+=(MA_Period-j)*price[i-j];
LineBuffer[i]=sum/weightsum;
}
//---
}
for(int i=begin; i < limit; i++)
{
int k=i-begin+1;
weightsum+=k;
firstValue+=k*price[i];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
注意声明变量i,所在的代码行
这里的变量i,其范围仅为for循环;还有另一个具有相同名称的变量i,在函数的开始处就声明了。此外,变量k也是在for循环内部声明的,其范围也就是在for循环内部。
声明局部变量时,也可以使用访问修饰符 static 。在这种情况下,编译器将该变量放在全局内存池。因此,静态变量的生命周期等于程序的生命周期。但这样一个变量的作用范围仍然仅限于声明它的代码块内部。
另见 数据类型, 类型密封和扩展,变量初始化, 创建和删除对象
# 1.6.9 创建和删除对象
将MQL5程序加载执行后,首先会按照声明的变量类型分配内存空间。根据访问级别,所有的变量都分为两类 —— 全局变量 和 局部变量。根据内存存储类型分类,它们可以是MQL5的输入参数,静态的 或者 自动的。如果需要,每个变量都由对应其数据类型的值进行初始化。在使用了一个变量之后,程序结束时,使用过的内存会被返回到MQL5执行系统中。
全局变量的初始化和反初始化(析构)
MQL5程序载入后,在调用任何函数之前,全局变量首先自动初始化。初始化过程是,初始值被分配给简单类型的变量和构造函数(如果有的话)。输入变量总是在全局范围声明,程序启动时由用户在对话框中设置初始值。
即使是在程序代码块内部声明的静态局部变量,也会与全局变量一样,仍要首先预分配内存空间,程序载入后即初始化静态变量。
初始化顺序对应于程序中的变量声明的顺序。反初始化(析构)的执行顺序则是与初始化命令相反。此规则只适用于 不是由 new 语句创建的变量。这些变量(由 new 指令创建的变量)是在加载后自动创建和初始化的,并且在程序卸载之前被反初始化(析构)。
局部变量的初始化和反初始化(析构)
如果声明的局部变量不是静态变量(意即,没有用 static 修饰符),则会自动为这样一个变量分配内存。局部变量,和全局变量一样,在程序执行到声明该变量的语句时,即自动初始化该变量。因此,初始化顺序对应于声明的顺序。
局部变量在程序结束时无法初始化。程序模块是复合语句,是选择语句切换,循环语句(for, while, do-while),函数主体,或者if-else 语句的一部分, 局部变量在程序代码块的末尾被反初始化(析构),按照在该程序代码块中声明它们的顺序,反初始化(析构)以相反顺序进行。程序代码块可以是一个复合运算符,如 switch 语句 的一部分,循环语句(for,while,do - while),一个自定义函数体的一部分 或if - else语句的一部分。
只有当程序执行到声明局部变量的语句时,才开始初始化局部变量。如果在程序执行过程中,声明变量的代码块未被执行,则该变量不会被初始化。
放置对象的初始化和反初始化(析构)
一个特殊的例子是对象指针,因为指针声明不需要初始化相应的对象。动态放置的对象只在new 语句创建 类 样本时初始化。对象的初始化假设调用对应类的构造函数。如果 类 中没有相应的构造函数,那么它的简单类型的成员将不会被自动初始化;类型字符串、动态数组和复杂对象的成员将自动初始化。
指针可以在局部或者全局范围内声明;它们初始化时,可以为 空值 或 相同类型的指针的值 或 继承类型的指针的值。如果 new 语句调用的是局部范围内声明的指针,则必须在退出该范围之前对该指针执行 delete语句。否则,指针将丢失,对象的显式删除将失败。
所有由object_pointer = new Class_name表达式创建的对象,必须被delete(object_pointer)语句删除。如果由于某些原因,当程序完成时,delete 语句无法删除该变量,则相应的消息条目将出现在“EA”日志中。可以声明多个变量,并为所有变量指定一个对象的指针。
如果一个动态创建的对象有一个构造函数,那么这个构造函数将在 new 语句执行的时刻被调用。如果对象有析构函数,则在执行 delete 语句时调用它。
因此,只有在调用相应的 new 语句时才会创建动态放置的对象,并且在程序卸载过程中被delete 语句 或 MQL5执行系统自动删除。动态创建对象的指针的声明顺序不会影响初始化的顺序。初始化和反初始化(析构)的顺序完全由程序员控制。
MQL5中的动态内存分配
当使用动态数组时,释放的内存立即返回到操作系统。
当使用new语句处理动态类对象时,会从内存管理器正在处理的 类 内存池中请求最初的内存空间。如果内存池中没有足够的内存,则从操作系统请求内存。当使用delete 语句删除动态对象时,释放的内存立即返回给 类 内存池。
内存管理器退出下列事件处理函数后立即释放内存返回操作系统:OnInit(), OnDeinit(), OnStart(), OnTick(), OnCalculate(), OnTimer(), OnTrade(), OnTester(), OnTesterInit(), OnTesterPass(), OnTesterDeinit(), OnChartEvent(), OnBookEvent()。
变量的简要特征
下表给出了关于创建、删除、构造函数和析构函数调用顺序的主要信息。
| 全局自动变量 | 局部自动变量 | 动态创建对象 | |
|---|---|---|---|
| 初始化 | 加载MQL5程序后 | 执行到声明语句时 | 执行 new 语句时 |
| 初始化顺序 | 按照声明的顺序 | 按照声明的顺序 | 不考虑声明的顺序 |
| 反初始化(析构) | MQL5程序卸载前 | 当程序执行到退出声明该变量的代码块时(即,遇到代码块结束符右花括号) | 执行删除操作符或者MQL5卸载前 当执行 delete 语句时,或在MQL5程序卸载前 |
| 反初始化(析构)顺序 | 与初始化命令顺序相反 | 与初始化命令顺序相反 | 不考虑声明的顺序 |
| 调用构造函数 | 加载MQL5程序时 | 在初始化时 | 执行 new 语句时 |
| 调用析构函数 | 卸载MQL5程序时 | 当程序执行到退出该变量初始化的代码块时(即,遇到代码块结束符右花括号) | 当执行 delete 语句时 |
| 错误日志 | 在“专家(EA)”标签中会出现一条日志消息关于试图删除一个自动创建的对象未成功 | 在“专家(EA)”标签中会出现一条日志消息关于试图删除一个自动创建的对象未成功 | 在“专家(EA)”标签中会出现一条日志消息关于在一个MQL5程序卸载时试图删除动态创建对象未成功 |
另见
数据类型, 类型密封和扩展,变量初始化, 可见范围和变量使用期
# 1.7 预处理器
预处理器是MQL5编译器的一个特殊的子系统,它的目的是在程序源代码编译之前预先直接编译一些额外的程序源码。
预处理器可以增强源代码的可读性。代码的结构可以由包含MQL5程序源代码的特定文件组成。为特定的常量分配助记符名称,有助于增强代码的可读性。(如果你熟悉C语言,联想一下define命令,就容易理解了)
预处理器也用来确定MQL5程序的一些指定参量:
• 常量声明
• 设置程序属性
• 声明包含文件
• 导入外部函数
• 条件编译
如果在程序源代码中,一行以 # 符号开头,则这一行被认为是预处理器指令。一个预处理器指令以换行符(回车Enter)结尾表示结束。
# 1.7.1 常量声明 (#define, #undef)
#define直接用来指定常量助记名(在 c 语言里也被称为 宏替换)。有两种形式:
#define identifier expression // 无参数形式
#define identifier(par1,... par8) expression
2
#define 指令表示,在之后的源代码文本中,指定的标识符,都替换成指定的表达式。指定的标识符必须是单独书写的(如 替换 功能中的条件,整词匹配),才会被替换。如果在源代码文本中,出现的标识符是注释的一部分、字符串的一部分 或 另一个较长的标识符的一部分,则该标识符不会被替换。
常量标识符同样遵循上述规则控制,如变量名一样。该值可以是任何类型:
#define ABC 100 // 表示在之后的源码中,如果有 ABC,就替换成 100
#define PI 3.14 // 表示在之后的源码中,如果有 PI,就替换成 3.14
#define COMPANY_NAME "MetaQuotes Software Corp." // 表示在之后的源码中,如果有 COMPANY_NAME
就替换成 "MetaQuotes Software Corp."
...
void ShowCopyright()
{
Print("Copyright 2001-2009, ",COMPANY_NAME);
Print("https://www.metaquotes.net");
}
2
3
4
5
6
7
8
9
10
expression 由几种标记组成,例如关键字,常量,有常量无常量表达式。expression在直线末端结束,不可转到下一行。
表达式可以包含几个标识符,如关键字、常量、常量 或/和 非常量表达式。表达式以换行符尾结束,不能写到下一行。
示例:
#define TWO 2
#define THREE 3
#define INCOMPLETE TWO+THREE
#define COMPLETE (TWO+THREE)
void OnStart()
{
Print("2 + 3*2 = ",INCOMPLETE*2);
Print("(2 + 3)*2 = ",COMPLETE*2);
}
// 结果
// 2 + 3*2 = 8
// (2 + 3)*2 = 10
2
3
4
5
6
7
8
9
10
11
12
带参数形式的 #define 通过带参数形式的宏替换,表示在之后的源代码文本中,指定的标识符,都替换成指定的表达式,并考虑到实际的参数。
例如:
// a和b两个参数的示例
#define A 2+3
#define B 5-1
#define MUL(a, b) ((a)*(b))
double c=MUL(A,B);
Print("c=",c);
/*
expression double c=MUL(A,B);
is equivalent to double c=((2+3)*(5-1));
*/
// 结果
// c=20
2
3
4
5
6
7
8
9
10
11
12
13
在表达式中使用参数时,一定要将参数括起来,因为这将有助于避免难以发现的非明显错误。如果我们在不使用括号的情况下重写代码,结果将是不同的:
// a和b两个参数的示例
#define A 2+3
#define B 5-1
#define MUL(a, b) a*b
double c=MUL(A,B);
Print("c=",c);
/*
expression double c=MUL(A,B);
is equivalent to double c=2+3*5-1;
*/
// 结果
// c=16
2
3
4
5
6
7
8
9
10
11
12
13
使用参数形式时,最多允许带8个参数。
// 正确的参数形式
#define LOG(text) Print(__FILE__,"(",__LINE__,") :",text) // 一个参数 - 'text'
// 不正确的参数形式
#define WRONG_DEF(p1, p2, p3, p4, p5, p6, p7, p8, p9) p1+p2+p3+p4 // 从p1到p9的超过8个参数
2
3
4
5
#undef 反宏替换指令
#undef指令用于取消之前定义的宏替换声明。
示例:
#define MACRO
void func1()
{
#ifdef MACRO // #ifdef 是条件编译 预处理指令
Print("MACRO is defined in ",__FUNCTION__);
#else // #ifdef 是条件编译 预处理指令
Print("MACRO is not defined in ",__FUNCTION__);
#endif // #ifdef 是条件编译 预处理指令
}
#undef MACRO
void func2()
{
#ifdef MACRO // #ifdef 是条件编译 预处理指令
Print("MACRO is defined in ",__FUNCTION__);
#else // #ifdef 是条件编译 预处理指令
Print("MACRO is not defined in ",__FUNCTION__);
#endif // #ifdef 是条件编译 预处理指令
}
void OnStart()
{
func1();
func2();
}
/* Output:
MACRO is defined in func1
MACRO is not defined in func2
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
另见 标识符,字符常量
# 1.7.2 程序属性 (#property)
每个mql5程序都允许使用 #property 预处理指令来指定一些附加的特定参数,用来帮助客户端为程序提供适当的服务,而无需显式地启动它们。首先,这涉及到指标的外部设置。包含文件(如 .mqh)中的描述属性(#property)会被完全被忽略。#property 描述属性预处理指令必须在主文件.mq5中指定。
#property identifier value
编译器将在执行模块的配置中写入声明的值。
| 常数 | 类型 | 描述 |
| icon | string | 指定一个图像文件的路径,该图像将被用作EX5程序的图标。路径规则与 资源(图形与声音文件) 相同。该属性必须在MQL5主模块源代码中指定。图标文件必须是ICO格式。 |
| link | string | 链接到公司网站 |
| copyright | string | 公司名称 |
| version | string | 程序版本,最大31位字符 |
| description | string | mql5程序的简短文本描述。可以同时有几个文本描述,每个描述文本占用一行。所有描述文本的总长度不能超过511个字符,包括换行符。 |
| stacksize | int | 指定MQL5程序堆栈的大小。当执行函数递归调用时,需要有足够大小的堆栈。 当在图表上启动脚本或EA时,至少要分配8 MB的堆栈。如果是指标,堆栈的大小总是固定的,等于1 MB。 当在策略测试器中启动一个程序时,总是为它分配16MB的堆栈。 |
| library | 一个程序库;没有分配启动函数,带有 输出修饰符 的函数可以导入 到其他mql5 程序中 | |
| indicator_applied_price | int | 指定一些指标(如:Moving Average )的设置窗口 参数 标签中,“应用到”字段的默认值。如果属性没有指定,您可以指定一个 ENUM_APPLIED_PRICE值,默认值为PRICE_CLOSE(即收盘价) |
indicator_chart_window  | 指标显示主图表窗口中。(意即:与报价K线叠加) | |
| indicator_separate_window | 指标显示在独立副图窗口中 | |
| indicator_height | int以像素为单位修正指标独立窗口的高度(属INDICATOR_HEIGHT) | |
| indicator_buffers | int | 指标计算缓冲区(之后需要与 数组 绑定) |
| indicator_plots | int | 指标 图解系列(绘画风格) 数目 |
| indicator_minimum | double | 独立指标窗口底部最小值比例限制 |
| indicator_maximum | double | 独立指标窗口顶部最大值比例限制 |
| indicator_labelN | string | 为在 数据窗口 中显示的n个 图解系列(绘画风格) 设置一个标签。对于需要多个指标缓冲区的 图解系列(绘画风格) (DRAW_CANDLES, DRAW_FILLING和其他),用分号“;”来分隔标签名称。 |
| indicator_colorN | color | 第 N种线的颜色,N为图解系列(绘画风格) 的数量;从1开始计数 |
| indicator_widthN | int | 第 N种线的粗细(宽度),N为图解系列(绘画风格) 的数量;从1开始计数 |
| indicator_styleN | int | 第 N种线的 图解系列(绘画风格) 的线型,由ENUM_LINE_STYLE 值(如:实线,折线,虚线...)指定。N为 图解系列(绘画风格) 的数量;从1开始计数 |
| indicator_typeN | int | 第 N种线的 图解系列(绘画风格) 的绘图种类,由ENUM_LINE_STYLE 值(如:线,柱子,箭头...)指定。N为 图解系列(绘画风格) 的数量;从1开始计数 |
| indicator_levelN | double | 独立指标窗口中第 N根水平线 |
| indicator_levelcolor | color | 指标水平线颜色 |
| indicator_levelwidth | int | 指标平线粗细(宽度) |
| indicator_levelstyle | int | 指标水平线类型 |
| script_show_confirm | 运行脚本前显示确认窗口 | |
| script_show_inputs | 在运行该脚本之前,使用属性显示窗口,并禁用此确认窗口 | |
| tester_indicator | string | 以“indicator_name . ex5”的格式的命名自定义指标的名称。需要测试的指标会自动从iCustom()函数的调用中定义,如果相应的参数是通过一个常量字符串设置的。对于所有其他情况(使用IndicatorCreate()函数或在设置指标名称的参数中使用非常量字符串),此属性是必需的 |
| tester_file | string | 使用双引号(作为常量字符串)表示扩展名的测试器的文件名。指定的文件将被传递给测试器。要测试的输入文件,如果有必要的话,必须始终指定。 |
| tester_library | string | 库名称与扩展名,双引号。一个库文件可以有“.dll”或“.ex5”作为文件扩展名。需要测试的库是自动定义的。但是,如果某个自定义指标使用了任何库文件,则需要使用此属性 |
描述和版本号的任务例子
#property version "3.70" // EA交易的当前版本
#property description "ZigZag universal with Pesavento Patterns"
#property description "At the moment in the indicator several ZigZags with different algorithms
are included"
#property description "It is possible to embed a large number of other indicators showing the
highs and"
#property description "lows and automatically build from these highs and lows various graphical
tools"
2
3
4
5
6
7
8
为每个指标缓冲区指定单独的标签的示例(“C open; C high; C low; C close”)
#property indicator_chart_window
#property indicator_buffers 4
#property indicator_plots 1
#property indicator_type1 DRAW_CANDLES
#property indicator_width1 3
#property indicator_label1 "C open;C high;C low;C close"
2
3
4
5
6
# 1.7.3 包括文件 (#include)
#include 命令可以放置到程序的任意部分,但是通常所有文件的源代码被统一放置。调用格式;
#include <file_name>
#include "file_name"
2
示例
#include <WinUser32.mqh>
#include "WinUser32.mqh"
2
预处理器将会用文件 WinUser32.mqh 的内容 替换 #include <file_name> 所在的行。尖括号表示WinUser32.mqh文件将从标准目录中获取(通常它是在 终端安装目录\MQL5\include 文件夹中)。搜索包含文件,不包含当前目录和子文件夹。
如果文件名是用 双引号 括起来的,那么表示在当前目录(包含主源文件)中搜索。在搜索中则不包括标准目录(即:终端安装目录\MQL5\include)。
另见 标准数据库 ,输入函数
# 1.7.4 导入函数(#import)
从已编译的MQL5模块(.ex5文件) 和 操作系统模块(.dll文件)导入函数。模块文件名称必须在 #import语句中指定。为了让编译器能够正确地导入函数调用并组织适当的传输参数,需要对函数进行完整的描述。函数描述直接紧跟在 #import "模块文件名称"指令 后面。新起一行的 #import 语句(没有带任何参数的)表示导入函数代码块结束。
#import "file_name"
func1 define;
func2 define;
...
funcN define;
#import
2
3
4
5
6
导入的函数可以命名为任何名称。具有相同名称但来自不同模块文件的函数可以同时导入。导入的函数可以和内置函数具有一样的名称。范围解析语句 (:😃 定义了哪些函数会被调用。
导入函数指令 #import 指定的文件的搜索顺序,请参考 调用导入函数 部分的具体描述。
由于导入的函数是在模块之外编译的,MQL编译器无法验证传递参数的有效性。因此,为了避免运行时错误,必须精确地描述传递给导入函数的参数的组成和顺序。传递给导入函数的参数(来自EX5,以及来自dll模块)可以有默认值。
以下元素不能用作导入函数的参数:
• 指针 (*);
• 包含动态数组 和/或 指针的对象的链接。
类,字符串数组 或 包括字符串 和/或 任何类型的动态数组的复合对象不能作为参数传递给来自DLL的导入函数。
示例:
#import "user32.dll"
int MessageBoxW(uint hWnd,string lpText,string lpCaption,uint uType);
#import "stdlib.ex5"
string ErrorDescription(int error_code);
int RGB(int red_value,int green_value,int blue_value);
bool CompareDoubles(double number1,double number2);
string DoubleToStrMorePrecision(double number,int precision);
string IntegerToHexString(int integer_number);
#import "ExpertSample.dll"
int GetIntValue(int);
double GetDoubleValue(double);
string GetStringValue(string);
double GetArrayItemValue(double &arr[],int,int);
bool SetArrayItemValue(double &arr[],int,int,double);
double GetRatesItemValue(double &rates[][6],int,int,int);
#import
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在mql5程序执行期间导入函数,需要使用前期绑定。这意味着在ex5程序加载时,就会加载模块库。
不建议为可加载模块使用完整的文件路径名称,如 :Drive:\Directory\FileName.Ext。MQL5库从 客户端目录\MQL5\libraries文件夹中加载。
另见 包含文件
# 1.7.5 条件编译 (#ifdef, #ifndef, #else, #endif)
预处理器条件编译指令允许编译或跳过部分程序,具体取决于特定条件的满足情况。 条件可以是下列形式之一
#ifdef identifier
// 如果#define指令已经为预处理器定义标识符那么就会编译位于这里的代码。
#endif
#ifndef identifier
// 如果#define预处理器指令当前没有定义标识符则编译位于这里的代码。
#endif
2
3
4
5
6
条件编译指令可以写在任何代码行之后,以 #ifdef 或 #ifndef 开头,其中可能包含 #else指令并以 #endif结尾。如果已验证的条件为真,则 #else与 #endif之间的行将被忽略。如果验证的条件为假,则忽略 #else指令之前的所有行(如果没有 #else ,则直接跳到 #endif指令之后)。
例如:
#ifndef TestMode
#define TestMode
#endif
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
#ifdef TestMode
Print("Test mode");
#else
Print("Normal mode");
#endif
}
2
3
4
5
6
7
8
9
10
11
12
13
14
根据程序类型和编译模式,标准宏的定义如下:
在编译时 .mq5文件时定义__MQL5__宏,在编译时.mq4文件时定义__MQL4__宏。
在调试模式下编译时定义_DEBUG宏。
在发布模式下编译时定义_RELEASE宏。
示例:
//+------------------------------------------------------------------+
//| 脚本程序开始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
#ifdef __MQL5__
#ifdef _DEBUG
Print("Hello from MQL5 compiler [DEBUG]");
#else
#ifdef _RELEASE
Print("Hello from MQL5 compiler [RELEASE]");
#endif
#endif
#else
#ifdef __MQL4__
#ifdef _DEBUG
Print("Hello from MQL4 compiler [DEBUG]");
#else
#ifdef _RELEASE
Print("Hello from MQL4 compiler [RELEASE]");
#endif
#endif
#endif
#endif
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 1.8 面向对象的程序设计
面向对象程序设计,是一个难点。以前确实没看懂。后来才渐渐明白,因为那些教材上翻译的名词,都不一样啊(都不说人话啊)。比如:class 这个词,有的翻译成类,有的翻译成类型,还有翻译成 课、经典....我服了。这也罢了,问题是英文原文,一个东西或一个事儿,也有多个单词来表达(人家英文就是这样,咋的了?还不让人家英国人词汇丰富点了?)比如:声明一个变量 或 函数。 声明 这个词的英文原文,有时是 declaration ,有时是 statement ,有时 explication,caption 、define 、description...写程序语言教材的真心不是英语老师,用词那个任性,也是醉了。
好吧,说远了。说结构、类、成员、方法、函数、变量、实例、对象、行为,就这些中文名词都够搞脑子的了。好好理解吧。
面向对象的程序设计(OOP)主要是针对数据进行编程,而数据和行为是不可分离地链接在一起的。数据和行为合起来称为类,而对象是类实例。
面向对象编程处理的组件有:
• 类型封装和扩展性
• 继承机制
• 多态性
• 重载
• 虚拟函数
OOP认为计算就是对行为建模。建模的项目是用计算抽象表示的对象。假设我们想写一个著名的游戏“俄罗斯方块”。为了做到这一点,我们必须学习如何用四个正方形随机组成的图形来建模。我们还需要调整形状的下降速度,定义旋转的操作和形状的移动。在屏幕上移动形状还会受到预定的井字格边界的限制,这个要求也必须被建模。此外,必须消除填满的行,然后获得相应的得分。
因此,这个简单易懂的游戏需要创建几个模型----图形模型,井字格对象模型,移动模型等等。所有这些模型都是抽象的,用计算机的计算来表示。为了描述这些模型,使用了抽象数据类型---ADT(或复杂数据类型)的概念。严格说来,DOM中“图形”运动模型并不是数据类型,而是“图形”数据类型的一组操作,使用“井字格”数据类型的限制。
对象是类变量。面向对象的程序设计允许您轻松地创建和使用ADT。面向对象程序设计使用了继承机制。继承的好处在于,它允许从用户已经定义的数据类型中获得派生类型。
例如,创建俄罗斯方块的图形,首先创建一个基本类图形很方便;代表所有可能图形的其他七个类可以从基本图形衍生出来。图形行为在基本类中就确定了,而执行每个独立图形的行为在派生类中定义。
在OOP中对象定义自己的行为操作。ADT开发人员应该包括一段代码来描述相关对象期望的操作行为代码。实际上,对象自身定义自己的行为操作,显著简化了该对象的用户程序设计编程任务。
如果我们想要在屏幕上画一个图形,我们需要知道中心点在哪里,以及如何画它。如果独立的图形知道如何画自己,当程序员需要使用这个图形时,只用发送一个“draw”消息即可。
MQL5语言类似于C++,也有ADT的封装机制。一方面,封装结合了特定类型的实现的内部细节,另一方面,它结合了外部可访问的函数,可以影响这种类型的对象。使用这种类型的程序可能无法访问实现细节。
OOP概念有一系列相关概念,包括以下内容:
• 模拟真实世界操作
• 用户定义数据类型的有效性
• 隐藏执行细节
• 通过继承机制重新使用代码的可能性
• 执行期解释调用函数
一些概念非常不明确,有一些很抽象,另一些又很大众化。
# 1.8.1 类型的密封和扩展
OOP是一种平衡的编写软件的方法。数据和行为被打包在一起。这种封装创建了用户自定义的数据类型,扩展了计算机语言自身的数据类型,并与之交互。类型可扩展性是一个向计算机语言添加用户自定义数据类型的机会,该类型像基本类型一样,很容易使用。
一个抽象的数据类型,例如,一个字符串,是对理想的,众所周知的操作字符的行为类型的描述。
字符串用户知道字符串操作,例如连结或者打印,具有一定的行为。连接和打印操作称为方法。
ADT的某些实现可能有一些限制,例如,字符串的长度可能是有限的。这些限制影响了对所有人开放的行为。同时,内部或私有实现细节不会直接影响用户看到对象的方式。例如,字符串通常是作为一个数组实现的,而这个数组的内部基本地址和它的名称对用户来说并不重要。
封装的意思是:在提供用户自定义类型的开放接口时,隐藏执行细节的能力。在MQL5中,以及在C++中,类和结构的定义(class和struct )都适用于封装条款,与访问关键字private、protected和public相结合。
关键字public表示接入其后面的成员,无任何限制都可以访问。没有这个关键字,类成员就会被默认封装。private 成员表示只能由这个 类 中的成员函数才能访问。
Protected类函数不仅可以在其类中得到,也可以在其继承类中得到。Public类函数可以在类声明范围任一函数中得到。保护可以隐藏类的部分执行,因此阻止了数据结构中意外改变。接入限制 或/和 数据隐藏都是面向对象程序设计的一个特点。
通常情况下,声明类函数时,带有 protected修饰符进行保护,而读取和写入的操作,由带有publics修饰符定义的所谓的set设置 和 get方法来执行。
示例:
class CPerson
{
protected:
string m_name; // 名称
public:
void SetName(string n){m_name=n;}// 设置 名称
string GetName(){return (m_name);} // 返回 名称
};i fcdx
2
3
4
5
6
7
8
这种方法有几个优点。首先,通过函数名,我们可以理解它的作用——设置或获取类成员的值。其次,也许在将来,我们需要更改CPerson类中的m_name变量的类型,或者在它的任何派生类中更改。
在这种情况下,我们只需要更改函数SetName()和GetName()的实现,而CPerson类的对象就可以在程序中使用,而不需要修改任何代码,因为用户甚至不知道m_name的数据类型已经发生了变化。
示例:
struct Name
{
string first_name; // 姓
string last_name; // 名
};
class CPerson
{
protected:
Name m_name; // 名称
public:
void SetName(string n);
string GetName(){return(m_name.first_name+" "+m_name.last_name);}
private:
string GetFirstName(string full_name);
string GetLastName(string full_name);
};
void CPerson::SetName(string n)
{
m_name.first_name=GetFirstName(n);
m_name.last_name=GetLastName(n);
}
string CPerson::GetFirstName(string full_name)
{
int pos=StringFind(full_name," ");
if(pos>0) StringSetCharacter(full_name,pos,0);
return(full_name);
}
string CPerson::GetLastName(string full_name)
{
string ret_string;
int pos=StringFind(full_name," ");
if(pos>0) ret_string=StringSubstr(full_name,pos+1);
else ret_string=full_name;
return(ret_string);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
另见 数据类型
# 1.8.2 继承算法
OOP的特点是通过继承算法鼓励代码重复使用。一个新的 类 可以从现存的,基本的 类 中生成。派生类使用基本类成员,但是也可以修改和补充它们。
许多类型是现有类型的变体。为每个类开发新的代码通常很乏味。此外,新代码意味着新的错误。派生类继承基类的描述,因此不必重新开发和重新测试代码。继承关系是分层级体系。
层级是一种允许复制所有元素的多样性和复杂性的类函数(方法)。它介绍了对象等级分类。例如,元素周期表上有气体。它们具有所有周期性元素固有的特性。
惰性气体构成下一个重要的子类。等级是惰性气体,如氩是气体,而气体则是系统的一部分。这种层次结构可以很容易地解释惰性气体的行为。我们知道它们的原子中含有质子和电子,这对其他元素都是成立的。
我们知道如其他气体一样它们在常温也是气体状态。我们还知道在惰性气体这个子集中,没有某一种气体能与其他化学元素发生化学反应,这是所有惰性气体的特性。
考虑一个几何形状继承的例子。为了描述各种各样的简单形状(圆、三角形、矩形、正方形等),最好的方法是创建一个基类(ADT),它是所有派生类的祖先。
让我们创建一个基本类 CShape,它包括描述图形最常用的成员构件。这些成员构件描述任何图形所特有的属性 -- 形状类型和主要锚点坐标。
示例:
//--- 基本类的形状
class CShape{}
{
protected:
int m_type; // 形状类型
int m_xpos; // 基本点的X - 坐标
int m_ypos; // 基本点的Y - 坐标
public:
CShape(){m_type=0; m_xpos=0; m_ypos=0;} // 构建函数
void SetXPos(int x){m_xpos=x;} // 设置 X
void SetYPos(int y){m_ypos=y;} // 设置 Y
};
2
3
4
5
6
7
8
9
10
11
12
下一步,创建基本类衍生出的新类,这里我们可以添加说明类的必要的字段。对于圆形添加包括半径值构件是必须的。正方形以边值为特点。因此,由继承基本类CShape而衍生的类如下声明:
接下来,创建从基类派生的新类,这里我们可以添加必要的字段用于说明类,每个字段指定一个类。对于圆形形状,需要添加一个包含半径值的成员。方形形状的特点是边长值。因此,继承自基类CShape的派生类将被声明为:
//--- 派生类 圆形
class CCircle : public CShape // 冒号后定义基本类
{ // 从继承算法开始
private:
int m_radius; // 圆弧半径
public:
CCircle(){m_type=1;}// 构造函数, 类型 1
};
2
3
4
5
6
7
8
9
正方形类声明类似:
//--- 派生类 方形
class CSquare : public CShape // 冒号后定义基本类
{ // 从继承算法开始
private:
int m_square_side; // 方形的边
public:
CSquare(){m_type=2;} // 构造函数,类型2
};
2
3
4
5
6
7
8
9
注意对象创建时首先调用基本类构造函数,然后调用派生类的构造函数。当对象毁坏时首先调用派生类的析构函数,然后调用基本类析构函数。
应该注意的是,创建对象时,首先调用基类中的构造函数,然后调用派生类中的构造函数。当一个对象被销毁时,首先调用派生类中的析构函数,然后调用基类析构函数。
因此,通过声明基类中最普通的成员,我们可以在派生类中添加一个额外的成员,该成员指定一个特定的类。灵活运用继承算法可以创建强大的代码库,这些库可以多次重复使用。
从现存类创建派生类的句法如下:
class class_name :
(public|protected|private)opt base_class_name
//(opt 表示3个修饰符可选其中之一)
{
class members declaration
};
2
3
4
5
6
派生类的一个方面是其成员继承人(继承)的可见性(公开)。关键字public, protected 和private用于指明在多大程度上,基本类的成员构件也可用于派生类。在派生类的标题中冒号之后的关键字public表明,基类CShape的protected和public成员构件应该继承为派生类CCircle的protected和public成员构件。
基类的private成员构件不能用于派生类。public继承也意味着派生类(CCircle和CSquare)是基于类CShape派生出来的。也就是说,正方形(CSquare)是一个形状(CShape),但是形状不一定是正方形。
派生类是基本类的变体,它继承了基本类的protected 和 public成员构件。基本类的构造函数和析构函数不能继承。除了基本类的构件,派生类也可以添加新构件。
派生类可能包括成员函数的履行,不同于基类。它与 重载函数 没有什么共同之处,重载函数 是指 2个或多个函数的名称相同,但它们的含义因不同的 形式参数 而不同。
在protected继承中,基本类的public和protected 成员构件成为派生类的protected成员构件。在private 继承中,基本类的public 和protected 成员构件成为派生类的private成员构件。
在protected 和 private 继承中,“派生类的对象就是基类的对象”的关系是不正确的。protected 和 private继承类型很少见,而且每一个都需要小心使用。
应该了解继承类型(public,protected或private)不会影响从派生类访问继承层次结构的基类成员的方法。任何继承类型中,只有public 和 protected访问说明符声明的基类成员可用派生类。让我们考虑一下下面的示例:
应该理解的是,继承的类型(public,protected或private)不会影响从派生类中访问继承层次结构中的基类成员的方法。对于任何类型的继承,只有用public 和 protected访问修饰符声明的基类成员,才可能从派生类中获得。让我们来看看下面的例子:
#property copyright "Copyright 2011, MetaQuotes Software Corp."
#property link "https://www.mql5.com"
#property version "1.00"
//+------------------------------------------------------------------+
//| 一些访问类型的示例类 |
//+------------------------------------------------------------------+
class CBaseClass
{
private: //--- 从派生类,private成员不可用
int m_member;
protected: //--- 从基类及其派生类,protected方法不可用
int Member(){return(m_member);}
public: //--- 类构造函数可用于类的所有成员
CBaseClass(){m_member=5;return;};
private: //--- 将值分配给m_member的private方法
void Member(int value) { m_member=value;};
};
//+------------------------------------------------------------------+
//| 有错误的派生类 |
//+------------------------------------------------------------------+
class CDerived: public CBaseClass
// 由于默认的原因,public继承规范可以忽略。
{
public:
void Func() // 在派生类中,定义调用到基类成员的函数。
{
//--- 试图修改基类的private成员
m_member=0; // 错误,基类private成员不可用
Member(0); // 错误,基类的private方法不可用在派生类
//--- 阅读基类的成员
Print(m_member); // 错误,基类的private成员不可用
Print(Member()); // 没有错误,protected方法可从基类及其派生类使用
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
在上面的示例中,CBaseClass只有一个public方法——构造函数。构造函数在创建类对象时被自动调用。因此,private成员m_member和protected方法Member()不能从外部调用。但是如果是public继承类型,基类的Member()方法将可以从派生类使用。
如果是protected继承类型的情况下,所有public和protected访问权限的基类成员都会成为protected。这就意味着如果public基类的数据成员和方法从外部访问,那么protected继承类型的情况下,它们只能来自派生类及其派生类的类。
//+------------------------------------------------------------------+
//| 一些访问类型的示例类 |
//+------------------------------------------------------------------+
class CBaseMathClass
{
private: //--- private成员不可从派生类使用
double m_Pi;
public: //--- 获取和设置m_Pi值
void SetPI(double v){m_Pi=v;return;};
double GetPI(){return m_Pi;};
public: // 类构造函数可用于所有成员
CBaseMathClass() {SetPI(3.14); PrintFormat("%s",__FUNCTION__);};
};
//+------------------------------------------------------------------+
//| 一个派生类,在此m_Pi不能修改 |
//+------------------------------------------------------------------+
class CProtectedChildClass: protected CBaseMathClass
// Protected继承类型
{
private:
double m_radius;
public: //--- 派生类中的Public方法
void SetRadius(double r){m_radius=r; return;};
double GetCircleLength(){return GetPI()*m_radius;};
};
//+------------------------------------------------------------------+
//| 脚本启动函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 创建派生类时,基类的构造函数将自动调用
CProtectedChildClass pt;
//--- 指定半径
pt.SetRadius(10);
PrintFormat("Length=%G",pt.GetCircleLength());
//---如果我们取消注释下面一行,将会出现编译错误,因为SetPI()是 protected
// pt.SetPI(3);
//--- 现在声明基类变量,尝试将Pi常量设置等于10
CBaseMathClass bc;
bc.SetPI(10);
//--- 下面是结果
PrintFormat("bc.GetPI()=%G",bc.GetPI());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
实例表明,基类CBaseMathClass的方法SetPI()和GetPi()是开放状态并可以从程序的任何地方进行调用。但与此同时,对于从其派生的CProtectedChildClass来说,这些方法只能从CProtectedChildClass类或其派生类的方法进行调用。
如果是private继承类型,所有public和protected访问权限的基类成员都会成为private,并且在进一步继承中无法进行调用。
MQL5没有多继承算法。
另见
# 1.8.3 架构和类
多态性
多态性为表达不同类别的对象提供了一个机会,通过继承关系,在调用相同的函数元素时以不同的方式响应,它有助于创建一个通用的机制,不仅仅是用来描述基本类的行为,还包括子类的行为。
让我们继续开发一个基类CShape,并定义一个成员函数GetArea(),用于计算一个形状的面积。在从基类继承的所有子类中,我们按照计算特定形状区域的规则重新定义了这个函数。
对于一个正方形(类CSquare),通过它的边长计算面积,对于一个圆形(类CCircle),通过其半径来计算面积。我们可以创建一个数组来存储类CShape的对象,一个基类的对象和所有后裔派生类的对象都可以存储。进一步,我们可以为数组的每个元素调用相同的函数。
示例:
//--- 基本类
class CShape
{
protected:
int m_type; // 形状类型
int m_xpos; // 基本点的X - 坐标
int m_ypos; // 基本点的Y - 坐标
public:
void CShape(){m_type=0;}; // 构造函数, 类型=0
int GetType(){return(m_type);};// 返回 图形类型
virtual
double GetArea(){return (0); }// 返回 图形区域
};
2
3
4
5
6
7
8
9
10
11
12
13
现在,所有的派生类都有成员函数 getArea(), 返回0值,该函数以每个后代变化转变为基础实现。
//--- 派生类 圆形
class CCircle : public CShape // 冒号后定义基本类
{ // 从继承算法开始
private:
int m_radius; // 圆弧半径
public:
void CCircle(){m_type=1;}; // 构造函数, 类型=1
void SetRadius(double r){m_radius=r;};
virtual double GetArea(){return (3.14*m_radius*m_radius);}
// 圆形 区域
};
2
3
4
5
6
7
8
9
10
11
对于类Square来说,声明是一样的:
//--- 派生类 方形
class CSquare : public CShape // 冒号后定义基本类
{ // 从继承算法开始
private:
int m_square_side; // 方形的边
public:
void CSquare(){m_type=2;}; // 构造函数, 类型=1
void SetSide(double s){m_square_side=s;};
virtual double GetArea(){return (m_square_side*m_square_side);}
// 方形区域
};
2
3
4
5
6
7
8
9
10
11
12
为了计算正方形和圆的面积,我们需要 m_radius和 m_square_side的相应值,所以我们在相应类的声明中添加了函数SetRadius() 和SetSide()。
假定我们的程序中使用了从一个基本类型CShape派生的不同类型的对象(CCircle和CSquare)。 多态性允许创建基本CShape类的一个对象数组,但是当声明这个数组时,这些对象还是未知的,它们的类型是未定义的。
在程序执行过程中,将直接决定在数组的每个元素中包含什么类型的对象。这涉及到动态创建适当类的对象,因此必须使用对象指针而不是对象。
运算符 new 用于对象的动态创建。每个这样的对象都必须单独使用,并使用delete操作符明确地(显式地)删除。因此,我们将声明一个CShape类型的指针数组,并为每个元素创建一个合适类型的对象(新的Class_Name),如下面的脚本示例所示:
//+-----------------------------------------------------------------+
//| 脚本程序开始函数 |
//+-----------------------------------------------------------------+
void OnStart()
{
//--- 声明基本类型对象指针的数组
CShape *shapes[5]; // CShape对象指针的数组
//--- 这里以派生对象填充数组
//--- 声明指针到CCircle类型的对象
CCircle *circle=new CCircle();
//--- 在圆形指针设置对象属性
circle.SetRadius(2.5);
//--- 将指针值置于shapes[0]
shapes[0]=circle;
//--- 创建另一个CCircle对象并写下其指针在shapes[1]
circle=new CCircle();
shapes[1]=circle;
circle.SetRadius(5);
//--- 这里我们故意“忘记”设置shapes[2]值
//circle=new CCircle();
//circle.SetRadius(10);
//shapes[2]=circle;
//--- 不使用的元素设置为NULL
shapes[2]=NULL;
//--- 创建CSquare对象并写下其指针在shapes[3]
CSquare *square=new CSquare();
square.SetSide(5);
shapes[3]=square;
//--- 创建CSquare对象并写下其指针到shapes[4]
square=new CSquare();
square.SetSide(10);
shapes[4]=square;
//--- 我们有一组指针,获得其大小
int total=ArraySize(shapes);
//--- 通过数组的所有指针循环通过
for(int i=0; i < 5;i++)
{
//--- 如果指定指数的指针有效
if(CheckPointer(shapes[i])!=POINTER_INVALID)
{
//--- 记录类型和正方形
PrintFormat("The object of type %d has the square %G",
shapes[i].GetType(),
shapes[i].GetArea());
}
//--- 如果指针类型POINTER_INVALID
else
{
//--- 错误的通知
PrintFormat("Object shapes[%d] has not been initialized! Its pointer is %s",
i,EnumToString(CheckPointer(shapes[i])));
}
}
//--- 我们必须删除所有已创建的动态对象
for(int i=0;i < total;i++)
{
//--- 我们只可以删除POINTER_DYNAMIC类型指针的对象
if(CheckPointer(shapes[i])==POINTER_DYNAMIC)
{
//--- 删除的通知
PrintFormat("Deleting shapes[%d]",i);
//--- 通过指针删除对象
delete shapes[i];
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
请注意,当使用delete操作符删除对象时,必须检查其指针的类型。只有具有POINTER_DYNAMIC指针的对象可以使用delete来删除。对于其他类型的指针,将返回一个错误。
但除了在继承期间重新定义函数之外,多态还包括在一个类中实现具有不同参数集合的同一个功能。 这意味着这个类可能有几个具有相同名称但具有不同类型 和/或 一组参数的函数。 在这种情况下,多态性是通过函数重载实现的。
另见 标准程序库
# 1.8.4 重载
在一个类中,可以定义两个或多个名称相同,但是参数的数量不同的方法(函数)。这种情况,这个类中的 方法(函数)即被称为重载方法(类似重载函数),这样的过程称为方法重载。
方法(类中的函数声明)重载是实现多态的一种方式。 方法的重载按照与函数重载相同的规则执行。
如果被调用的方法(类函数)无法准确的匹配,则编译器会按顺序在三个级别上搜索合适的函数:
1.类函数中搜索;
2.在基类的方法(类函数)中搜索,始终从最近的父级类开始,一直到最顶级的基本类。
3.其他函数中搜索。
如果任何阶中都没有确切匹配的,但是在不同阶中找到几个适合的函数,使用最近阶找到的函数。一个阶中,只有一个适合的函数。
如果在所有层级中都没有找到精确的匹配对应方法(类函数)声明,但是已经找到了在不同层级上的几个合适的函数,那么就会使用在最低级别上被发现的函数。在一个层级中,不可能有多个合适的函数。
MQL5没有 类似 c++ 中的 操作符重载。
另见 重载函数
# 1.8.5 虚拟函数
关键字 virtual 是函数声明的修饰符,它提供了一种机制,可以在运行时动态地在 基本类和/或 派生类 的成员函数(方法)中选择适当的函数(方法)。 结构中不能有虚拟函数,它只能用于改变函数声明。
虚函数就像一个普通函数一样,必须有一个可执行体。 被调用时,其语义与其他函数相同。
虚拟函数可能在派生类中被重写(被重新定义)。虚拟函数(在运行时)选择调用哪个函数定义是动态的。典型情况是,当一个基类中包含一个虚拟函数,但派生类中又含有这个函数的另外的版本。
指向基类的指针可以指向基类对象或派生类的对象。要调用的成员函数的选择将在运行时决定,并将取决于对象的类型,而不是指针的类型。如果没有派生类的成员,则默认使用基类的虚拟函数。
无论是否使用了关键字 virtual 修饰符,析构函数永远是虚拟的。
让我们来看下面的例子,在MT5_Tetris.mq5的中使用的虚拟函数。虚拟函数 Draw 的基本类CTetrisShape,在包含文件MT5_TetrisShape.mqh中定义。
//+------------------------------------------------------------------+
class CTetrisShape
{
protected:
int m_type;
int m_xpos;
int m_ypos;
int m_xsize;
int m_ysize;
int m_prev_turn;
int m_turn;
int m_right_border;
public:
void CTetrisShape();
void SetRightBorder(int border) { m_right_border=border; }
void SetYPos(int ypos) { m_ypos=ypos; }
void SetXPos(int xpos) { m_xpos=xpos; }
int GetYPos() { return(m_ypos); }
int GetXPos() { return(m_xpos); }
int GetYSize() { return(m_ysize); }
int GetXSize() { return(m_xsize); }
int GetType() { return(m_type); }
void Left() { m_xpos-=SHAPE_SIZE; }
void Right() { m_xpos+=SHAPE_SIZE; }
void Rotate() { m_prev_turn=m_turn; if(++m_turn>3) m_turn=0; }
virtual void Draw() { return; }
virtual bool CheckDown(int& pad_array[]);
virtual bool CheckLeft(int& side_row[]);
virtual bool CheckRight(int& side_row[]);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
此外,对于每个派生类,该函数根据后代类的特征来实现。 例如,第一个形状CTetrisShape1有它自己的执行函数(方法)Draw():
class CTetrisShape6 : public CTetrisShape
{
public:
//--- 绘画形状
virtual void Draw()
{
int i;
string name;
//---
for(i=0; i < 2; i++)
{
name=SHAPE_NAME+(string)i;
ObjectSetInteger(0,name,OBJPROP_XDISTANCE,m_xpos+i*SHAPE_SIZE);
ObjectSetInteger(0,name,OBJPROP_YDISTANCE,m_ypos);
}
for(i=2; i < 4; i++)
{
name=SHAPE_NAME+(string)i;
ObjectSetInteger(0,name,OBJPROP_XDISTANCE,m_xpos+(i-2)*SHAPE_SIZE);
ObjectSetInteger(0,name,OBJPROP_YDISTANCE,m_ypos+SHAPE_SIZE);
}
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
根据所创建的对象所属的类(基类或派生类),它会选择调用基类或派生类中的虚拟函数。
void CTetrisField::NewShape()
{
//--- 创建7个随机形状中的一个
int nshape=rand()%7;
switch(nshape)
{
case 0: m_shape=new CTetrisShape1; break;
case 1: m_shape=new CTetrisShape2; break;
case 2: m_shape=new CTetrisShape3; break;
case 3: m_shape=new CTetrisShape4; break;
case 4: m_shape=new CTetrisShape5; break;
case 5: m_shape=new CTetrisShape6; break;
case 6: m_shape=new CTetrisShape7; break;
}
//--- 绘画
m_shape.Draw();
//---
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
修饰符 'override'
'override' 修饰符表示声明的函数必须重写父类的函数类。通过这个函数类您可以避免重写错误,例如它可以让您避免意外修改函数类签名。假设,'func' 函数类定义在基本类。函数类会接受int变量为自变量:
修饰符'override'意味着在派生类中声明的方法(函数)必须覆盖父类中声明的方法(函数)。 使用这个修饰符可以避免重写错误,例如它可以避免意外的修改了函数(方法)的形式参数。 假设函数(方法)'func'是在基本类中定义的。该函数(方法)接受一个int(整数型)变量作为参数:
class CFoo
{
void virtual func(int x) const { }
};
2
3
4
下一步,在子类中重写了该函数:
class CBar : public CFoo
{
void func(short x) { }
};
2
3
4
然而,自变量类型错误的从int 变为short。实际上,这不是类函数重写,而是类函数重载。根据重载函数定义算法,在某些情况下编译器可以选择在基类中定义的函数类来替代重写函数类。
然而,形式参数的类型被错误地从int变为short。实际上,这不是类函数重写,而是类函数重载。根据重载函数定义算法,在某些情况下编译器可能选择在基类(CFoo)中定义的函数,而不是在派生类(CBar)中重写的函数。
为了避免这样的错误,你应该为你想要覆盖的函数(方法)明确的添加修饰符'override'。
class CBar : public CFoo
{
void func(short x) override { }
};
2
3
4
如果在重写过程中更改了方法(函数)的形式参数,编译器将无法在父类中找到相同形式参数的方法(函数),并且将返回一个编译错误:
'CBar::func' method is declared with 'override' specifier but does not override any base class method
类'CBar::func' 函数是通过'override' 标识符声明但不会重写任何基本 类 的类函数
2
修饰符 'final'
修饰符'final'则是与'override'功能相反的 — 它禁止基本类中的方法(函数)在子类中被重写(覆盖)。如果一个类方法(函数)的定义(实现)已经非常充分并得到足够完成,那么使用'final'修饰符来声明这个类方法(函数),以确保它以后不被修改。
class CFoo
{
void virtual func(int x) final { }
};
class CBar : public CFoo
{
void func(int) { }
};
2
3
4
5
6
7
8
9
如果您尝试用上面的示例中所示的“final”修饰符覆盖方法,编译器将返回一个错误:
'CFoo::func' method declared as 'final' cannot be overridden by 'CBar::func'
see declaration of 'CFoo::func'
声明为'final'的'CFoo::func' 函数类不能通过 'CBar::func'重写
请见 'CFoo::func' 声明
2
3
4
另见 标准程序库
# 1.8.6 类/结构的静态成员
静态成员
类的成员可以使用存储修饰符static声明。 这些被修饰符 static 声明过的成员数据,可以被这个类的所有实例对象共享,并存储在内存中一个固定的地方。非静态成员数据(没有用修饰符 static 声明过的成员数据)在每个类的实例对象中创建变量。
禁用声明类的静态成员,会导致需要在程序的全局层面声明这些数据。这将会破坏数据和它们的类之间的关系,并且这样做(在全局层面声明变量数据)不符合OOP的基本范式--在类中加入数据和处理它们的方法。在类中声明的静态成员数据,可以不针对特定的具体实例(对象),而存在于类的范围中。
由于静态类成员不依赖于具体实例,则对它的引用如下:
class_name::variable
这里 class_name 是类的名称,而 variable 是类成员的名称。注意是 范围解析操作符(::)两个冒号。
如您所见,要访问类的静态成员,将使用 范围解析操作符:: 。当您在类方法中访问静态成员时,范围解析操作符 是可选的。
类的静态成员必须用期望的值明确地(显式)初始化。 它必须在全局范围声明和初始化。静态成员初始化的顺序将与它们在全局范围内声明的顺序相对应。
例如,我们有一个用于解析文本的类CParser,我们需要计算经过处理的单词和字符的总数。我们只需要将必要的类成员声明为静态并在全局层面初始化它们。然后,该类的所有实例将使用常用的单词和字符计数器。
//+----------------------------------------------------------------+
//| 类 "文本解析" |
//+----------------------------------------------------------------+
class CParser
{
public:
static int s_words;
static int s_symbols;
//--- 构造函数和析构函数
CParser(void);
~CParser(void){};
};
...
//--- 全局层面解析类静态成员的初始化
int CParser::s_words=0;
int CParser::s_symbols=0;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
静态类成员可以通过 const关键字来声明。这种静态常量必须在全局层面以const 关键字进行初始化:
//+----------------------------------------------------------------+
//| 类 "Stack" 存储处理数据 |
//+----------------------------------------------------------------+
class CStack
{
public:
CStack(void);
~CStack(void){};
...
private:
static const int s_max_length; // 最大存储栈能力
};
//--- 初始化CStack类的静态常量
const int CStack::s_max_length=1000;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
指针 this 关键字 this表示一个隐式声明的指向它自己的指针 —— 在该方法执行的上下文中,它指向类的一个特定实例。它只能在类的非静态方法中使用。指针 this 是任何类的隐式非静态成员。
在静态函数中您只可以访问静态成员/类方法。
静态方法(函数)
在MQL5中,类的成员函数 可以使用静态修饰符 static。 静态修饰符 static 必须写在类的函数声明中的返回类型之前。
class CStack
{
public:
//--- 构造函数和析构函数
CStack(void){};
~CStack(void){};
//--- 最大堆栈能力
static int Capacity();
private:
int m_length; // 存储栈中的元素数量
static const int s_max_length; // 最大存储栈能力
};
//+----------------------------------------------------------------+
//| 返回堆栈中存储的元素的最大数量 |
//+----------------------------------------------------------------+
int CStack::Capacity(void)
{
return(s_max_length);
}
//--- 初始化CStack 类的静态常量
const int CStack::s_max_length=1000;
//+----------------------------------------------------------------+
//| 脚本程序起始函数 |
//+----------------------------------------------------------------+
void OnStart()
{
//--- 声明 CStack 类型变量
CStack stack;
//--- 调用对象的静态方法
Print("CStack.s_max_length=",stack.Capacity());
//--- 它也可以按以下方式调用,因为方法是静态的,无需对象的存在
Print("CStack.s_max_length=",CStack::Capacity());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
使用const修饰符的方法(函数)被称为常数(方法/函数),并且不能修改该类的隐式成员。一个类的 常数函数的声明 和 常量参数的声明 被称为 常量正确性(const-correctness)控制。通过这个控制,您可以确保编译器将确保对象的值的一致性,并且如果出现错误,将会在编译时返回错误。
修饰符const书写在类声明中的参数列表之后。类之外的定义还应包括const修饰符:
//+----------------------------------------------------------------+
//| “矩形”类 |
//+----------------------------------------------------------------+
class CRectangle
{
private:
double m_width; // 宽度
double m_height; // 高度
public:
//--- 构造函数和析构函数
CRectangle(void):m_width(0),m_height(0){};
CRectangle(const double w,const double h):m_width(w),m_height(h){};
~CRectangle(void){};
//--- 计算区域
double Square(void) const;
static double Square(const double w,const double h);// { return(w*h); }
};
//+----------------------------------------------------------------+
//| 返回“矩形”对象区域 |
//+----------------------------------------------------------------+
double CRectangle::Square(void) const
{
return(Square(m_width,m_height));
}
//+----------------------------------------------------------------+
//| 返回两变量的产品 |
//+----------------------------------------------------------------+
static double CRectangle::Square(const double w,const double h)
{
return(w*h);
}
//+----------------------------------------------------------------+
//| 脚本程序起始函数 |
//+----------------------------------------------------------------+
void OnStart()
{
//--- 创建等于5和6的矩形
CRectangle rect(5,6);
//--- 用常量方法找出矩形区域
PrintFormat("rect.Square()=%.2f",rect.Square());
//--- 通过类CRectangle的静态方法找出产品数量
PrintFormat("CRectangle::Square(2.0,1.5)=%f",CRectangle::Square(2.0,1.5));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
另一个支持使用恒常性控制的理由是,在这种情况下,编译器生成一个特殊的优化,例如,在只读内存中放置一个常量对象。
静态函数不能使用 const 修饰符定义,因为当调用该函数时,该修饰符能够确保实例成员的恒常性。但是,如上所述,静态函数不能访问非静态类成员。
另见
静态变量,变量,参考。修饰符 & 和关键字 this
# 1.8.7 函数模板
重载函数 通常被用于执行各种数据类型的相似操作。在MQL5中,ArraySize() 就是这种 重载函数 的一个简单例子。它可以返回任何数据类型的数组大小。实际上,这个内置的系统函数就是一个 重载函数,MQL5应用程序开发人员隐藏了这样一个重载的整个实现方法:
int ArraySize(
void& array[] // 检查数组
);
2
3
它意味着MQL5语言编译器为这个函数的每个调用插入必要的实现方法。例如,对于整数型数组,可以这样做:
int ArraySize(
int& array[] // 数组元素为 int 类型
);
2
3
ArraySize() 函数可以按照以下方式展示 MqlRates 类型数组,以便引用以历史数据格式处理报价:
int ArraySize(
MqlRates& array[] // 填充 MqlRates 类型值的数组
);
2
3
因此,对于不同类型的数据处理工作,使用同一个名称的函数是非常方便的。然而,所有的前期工作都应该进行——应该为正确处理所有的数据类型 重载必要的函数。
这里有一个更方便的解决方案。假设对每种数据类型的执行操作,都比较相似,则可以使用函数模板。在这种情况下,程序员只需要编写一个函数模板的描述。当以这种方式描述模板时,我们应该只指定一个 正式参数 来替代定义(声明)函数处理的数据类型。编译器将根据调用函数时所使用的参数的类型自动生成各种函数,以便适当处理基于调用函数的参数类型的每种情况。
定义(声明)一个函数模板,必需用 template 关键字开头,紧随其后的是一对尖括号,在尖括号内,是 正式参数 列表。每个 正式参数 之前都必需书写 typename 关键字。正式参数的类型可以是内置的 或 用户自定义的数据类型。它们被用于:
• 指定函数参数类型,
• 指定函数返回值类型,
• 声明函数描述中的变量
函数模板的正式参数,数量不能超过8个。模板定义中的每个 正式参数 都应该至少在函数参数列表中出现一次。每个正式参数的名称都应该是独一无二的。
下面是一个函数模板的示例,搜索任何数值类型(整数和实数)的数组中的最高值:
template < typename T >
T ArrayMax(T &arr[])
{
uint size=ArraySize(arr);
if(size==0) return(0);
T max=arr[0];
for(uint n=1;n < size;n++)
if(max < arr[n]) max=arr[n];
//---
return(max);
}
< /typename >
2
3
4
5
6
7
8
9
10
11
12
13
这个模板定义了在接收到的数组中找到最高值,并返回这个值。请牢记,MQL5中内置的ArrayMaximum()函数只用于查找最高值的索引(即返回最高值在数组中的位置是第几个)。例如:
//--- 创建数组
double array[];
int size=50;
ArrayResize(array,size);
//--- 填充随机值
for(int i=0;i < size;i++)
{
array[i]=MathRand();
}
//--- 找出数组中最高值的位置
int max_position=ArrayMaximum(array);
//--- 现在,获得数组中的最高值
double max=array[max_position];
//--- 显示获得的值
Print("Max value = ",max);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在上例中,如果用内置的函数ArrayMaximum(),我们想获得最高值,需要执行两个步骤。现在我们使用ArrayMax()函数模板,我们可以通过发送相应类型的数组获得必要类型的结果。这意味着可以替换上例中的这两行代码
//--- 找出数组中最高值的位置
int max_position=ArrayMaximum(array);
//--- 现在,获得数组中的最高值
double max=array[max_position];
2
3
4
我们现在只使用一行代码,其中返回的结果与传入函数的数组具有相同的类型:
//--- 找出最高值
double max=ArrayMax(array);
2
在这种情况下,通过ArrayMax() 函数返回的结果类型将自动匹配数组的类型。
使用typename关键字来获取参数类型作为字符串,以创建处理各种数据类型的通用方法。让我们考虑一个函数的具体例子,它以字符串形式返回数据类型:
#include < Trade\Trade.mqh >
//+------------------------------------------------------------------+
//| |
//+------------------------------------------------------------------+
void OnStart()
{
//---
CTrade trade;
double d_value=M_PI;
int i_value=INT_MAX;
Print("d_value: type=",GetTypeName(d_value), ", value=", d_value);
Print("i_value: type=",GetTypeName(i_value), ", value=", i_value);
Print("trade: type=",GetTypeName(trade));
//---
}
//+------------------------------------------------------------------+
//| 类型返回为一行 |
//+------------------------------------------------------------------+
template < typename T >
string GetTypeName(const T &t)
{
//--- 返回类型为一行
return(typename(T));
//---
} < /typename >
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
函数模板也被用于类的方法,例如:
class CFile
{
...
public:
...
template
<typename T>
uint WriteStruct(T &data);
};
template<typename T>
uint CFile::WriteStruct(T &data)
{
...
return(FileWriteStruct(m_handle,data));
}
</typename>
</typename>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
函数模板不能使用 export,virtual 和#import 关键字进行声明。
模板函数重载 重载模板函数有时可能是必需的。例如,我们有一个模板函数,它使用类型转换将第二个参数的值写入第一个参数。MQL5不允许转换string类型到bool 类型。我们可以自己做——让我们创建一个模板函数的重载。例如:
//+------------------------------------------------------------------+
//| 模板函数 |
//+------------------------------------------------------------------+
template < typename T1,typename T2>
string Assign(T1 & var1,T2 var2)
{
var1=(T1)var2;
return(__FUNCSIG__);
}
//+------------------------------------------------------------------+
//| bool+string 特殊重载 |
//+------------------------------------------------------------------+
string Assign(bool & var1,string var2)
{
var1=(StringCompare(var2,"true",false) || StringToInteger(var2)!=0);
return(__FUNCSIG__);
}
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
int i;
bool b;
Print(Assign(i,"test"));
Print(Assign(b,"test"));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
< /typename>
作为代码执行结果,我们可以看到Assign()模板函数已经用于int+string组,而第二次调用时重载版本已经用于bool+string组。
string Assign < int,string > (int&,string)
string Assign(bool& , string)
2
另见 重载
模板优势
当您需要在不同数据类型上执行相似操作的时候,使用函数模板就较为方便。例如,寻找数组中的最大元素。使用函数模板的主要优势在于您无需为每个数据类型编制独立的重载函数代码。取而代之的方案是声明每个类型的多个重载函数模版即可。
double ArrayMax(double array[])
{
...
}
int ArrayMax(int array[])
{
...
}
uint ArrayMax(uint array[])
{
...
}
long ArrayMax(long array[])
{
...
}
datetime ArrayMax(datetime array[])
{
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
对于上面的例子,我们只需要编写一个模板函数
template < typename T >
T ArrayMax(T array[])
{
if(ArraySize()==0)
return(0);
uint max_index=ArrayMaximum(array);
return(array[max_index]);
}
< /typename >
2
3
4
5
6
7
8
9
10
将其用于您的编码中:
double high[];
datetime time[];
....
double max_high=ArrayMax(high);
datetime lasttime=ArrayMax(time);
2
3
4
5
这里,指定已用数据类型的正式参数 T 被替换为编译时实际的形式参数的类型,例如编译器为每个类型自动生成一个独立的函数 - double、datetime等等。MQL5还允许您使用这个方法的所有优点来开发类模板。
# 1.8.8 类模板
声明类模板使用 template关键字开头,后面紧跟尖括号<>,尖括号中包含以 typename关键字开头的正式参数列表。这样一行代码会通知编译器在执行这个 类 时,以正式参数 T 的具体数据类型来处理,T 的真实数据类型,作为一个普通 类 的形式参数数据类型来执行。例如,让我们创建一个用于存储具有T型元素的数组的矢量类:
#define TOSTR(x) #x+" " // 显示对象名称的宏
//+------------------------------------------------------------------+
//| 存储T- 类型元素的矢量类 |
//+------------------------------------------------------------------+
template < typename T >
class TArray
{
protected:
T m_array[];
public:
//--- 构造函数默认创建一个10元素数组
void TArray(void){ArrayResize(m_array,10);}
//--- 创建一个指定数组大小矢量类的构造函数
void TArray(int size){ArrayResize(m_array,size);}
//--- 返回存储在TArray类型对象中的数据类型和数据量
string Type(void){return(typename(m_array[0])+":"+(string)ArraySize(m_array));};
};
< /typename >
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
接下来,让我们应用不同的方法在程序中创建三个TArray对象来处理各种类型
void OnStart()
{
TArray < double > double_array; // 矢量默认大小10
TArray < int > int_array(15); // 矢量大小15
TArray < string > *string_array; // TArray < string > 矢量指针
//--- 创建动态对象
string_array=new TArray < string > (20);
//--- 在日志中显示对象名称,数据类型和矢量大小
PrintFormat("%s (%s)",TOSTR(double_array),double_array.Type());
PrintFormat("%s (%s)",TOSTR(int_array),int_array.Type());
PrintFormat("%s (%s)",TOSTR(string_array),string_array.Type());
//--- 完成程序之前删除动态对象
delete(string_array);
}< /string > </string > </string > </int > </double>
2
3
4
5
6
7
8
9
10
11
12
13
14
脚本执行结果:
double_array (double:10)
int_array (int:15)
string_array (string:20)
2
3
现在,我们有不同数据类型的3种矢量:double,int和string。
类模板非常适合于开发容器——用于封装任何类型的其他对象的对象。容器对象是已经包含一个特定类型的对象的集合。通常,处理存储数据会立即构建到容器中。
例如,您可以创建不允许访问数组外元素的类模板,因此也就是避免了“超范围”的严重错误。
//+------------------------------------------------------------------+
//| 自由访问数组元素的类 |
//+------------------------------------------------------------------+
template < typename T >
class TSafeArray
{
protected:
T m_array[];
public:
//--- 默认构造函数
void TSafeArray(void){}
//--- 创建指定大小数组的构造函数
void TSafeArray(int size){ArrayResize(m_array,size);}
//--- 数组大小
int Size(void){return(ArraySize(m_array));}
//--- 改变数组大小
int Resize(int size,int reserve){return(ArrayResize(m_array,size,reserve));}
//--- 释放数组
void Erase(void){ZeroMemory(m_array);}
//--- 通过索引访问数组元素的操作符
T operator[](int index);
//--- 从数组一次性接收全部元素的赋值操作符
void operator=(const T & array[]); // T 类型数组
};
//+------------------------------------------------------------------+
//| 通过索引接收元素 |
//+------------------------------------------------------------------+
template < typename T >
T TSafeArray::operator[](int index)
{
static T invalid_value;
//---
int max=ArraySize(m_array)-1;
if(index < 0 || index >= ArraySize(m_array))
{
PrintFormat("%s index %d is not in range (0-%d)!",__FUNCTION__,index,max);
return(invalid_value);
}
//---
return(m_array[index]);
}
//+------------------------------------------------------------------+
//| 分配数组 |
//+------------------------------------------------------------------+
template < typename T >
void TSafeArray::operator=(const T &array[])
{
int size=ArraySize(array);
ArrayResize(m_array,size);
//--- T 类型应该支持复制操作符
for(int i=0;i < size;i++)
m_array[i]=array[i];
//---
}
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
int copied,size=15;
MqlRates rates[];
//--- 复制报价数组
if((copied=CopyRates(_Symbol,_Period,0,size,rates))!=size)
{
PrintFormat("CopyRates(%s,%s,0,%d) returned %d error code",
_Symbol,EnumToString(_Period),size,GetLastError());
return;
}
//--- 创建容器并插入MqlRates值数组
TSafeArray < MqlRates > safe_rates;
safe_rates=rates;
//--- 数组内索引
int index=3;
PrintFormat("Close[%d]=%G",index,safe_rates[index].close);
//--- 数组外索引
index=size;
PrintFormat("Close[%d]=%G",index,safe_rates[index].close);
}
</MqlRates> </typename>
</typename>
</typename>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
请注意类声明外描述类函数时也应该使用模板声明:
template <typename T>
T TSafeArray::operator[](int index)
{
...
}
template <typename T>
void TSafeArray::operator=(const T & array[])
{
...
}
</typename>
</typename>
2
3
4
5
6
7
8
9
10
11
12
类和函数模板允许您定义多个逗号分隔的形式参数,例如,用于存储“键值”对的映射集合:
template < typename Key, template Value>
class TMap
{
...
}
2
3
4
5
另见 函数模板,重载
# 1.8.9 抽象类和纯虚函数
抽象类用于创建通用实体,就是您期待用其创建更具体的派生类。抽象类仅可以作为其他类的基类,这就是为什么不可能创建抽象类类型的对象。
一个至少包含一个纯虚函数的类就是抽象的。因此,源自于抽象类的类必须实现其全部的纯虚函数,否则它也将是抽象类。
虚函数通过使用pure-specifier语法来声明为"pure"。考虑CAnimal 类的示例,创建它只是为了提供普通函数 - CAnimal类型的对象对于实际使用过于一般。因此,CAnimal是抽象类的一个很好的示例:
class CAnimal
{
public:
CAnimal(); // 构造函数
virtual void Sound() = 0; // 纯虚函数
private:
double m_legs_count; // 动物腿的数量
};
2
3
4
5
6
7
8
这里Sound() 是一个纯虚函数,因为它是以纯虚函数PURE(=0)说明符进行声明。
纯虚函数只是以PURE说明符设置的虚函数:(=NULL) 或 (=0)。抽象类声明和使用的示例:
class CAnimal
{
public:
virtual void Sound()=NULL; // PURE 类函数,应该在派生类覆盖,CAnimal现在是抽象类,不能创建
};
//--- 派生自一个抽象类
class CCat : public CAnimal
{
public:
virtual void Sound() { Print("Myau"); } // PURE被覆盖,CCat不是抽象类,可以创建
};
//--- 错误使用的示例
new CAnimal; // 'CAnimal'错误 - 编译器返回 "不能示例抽象类"的错误
CAnimal some_animal; // 'CAnimal'错误 - 编译器返回 "不能示例抽象类"的错误
//--- 正确使用的示例
new CCat; // 无错误 - CCat 不是抽象类
CCat cat; // 无错误 - CCat 不是抽象类
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
抽象类的限制
如果抽象类的构造函数调用一个纯虚函数(直接或间接),结果是未定义的。
//+------------------------------------------------------------------+
//| 抽象基类 |
//+------------------------------------------------------------------+
class CAnimal
{
public:
//--- 纯虚函数
virtual void Sound(void)=NULL;
//--- 函数
void CallSound(void) { Sound(); }
//--- 构造函数
CAnimal()
{
//--- 虚类函数的显式调用
Sound();
//--- 隐式调用(使用第三个函数)
CallSound();
//--- 构造函数和/或析构函数始终调用其自己的函数,
//--- 即使它们是虚拟的并被派生类调用的函数覆盖
//--- 如果调用的函数是纯虚函数,
//--- 其调用将会导致危险的运行时错误:"纯虚函数调用"
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
然而,对于抽象类的构造函数和析构函数可以调用其他成员函数。
# 1.9 命名空间
namespace是一个特殊声明的区域,其中定义了各种ID:变量、函数、类等。其使用namespace关键字进行设置:
namespace name of_space {
//函数、类和变量定义的列表
}
2
3
应用'namespace'可以将全局的命名空间拆分为子空间。namespace中的所有ID都可以彼此使用,不需要特别指定。::操作符(语境解析操作)用于从外部访问命名空间(namespace)成员。
namespace ProjectData
{
class DataManager
{
public:
void LoadData() {}
};
void Func(DataManager& manager) {}
}
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 使用ProjectData命名空间
ProjectData::DataManager mgr;
mgr.LoadData();
ProjectData::Func(mgr);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
命名空间(namespaces)用于以逻辑组的形式排列代码,并避免在程序中使用多个程序库时可能发生的名称冲突。在这种情况下,可以在其命名空间(namespaces)中声明每个程序库,以便显式访问每个程序库的必要函数和类。
命名空间(namespaces)可以在一个或多个文件中的多个块中声明。编译器在预处理期间将所有部分组合在一起,并且得到的命名空间包含所有部分中声明的所有成员。假设我们在Sample.mqh包含文件中实现了A类:
//+------------------------------------------------------------------+
//| Sample.mqh |
//+------------------------------------------------------------------+
class A
{
public:
A() {Print(__FUNCTION__);}
};
2
3
4
5
6
7
8
我们想在我们的项目中使用这个类,但是我们已经有A类。若要能够使用这两个类并要避免ID冲突,只需将包含文件包含在命名空间中:
//--- 声明第一个A类
class A
{
public:
A() {Print(__FUNCTION__);}
};
//--- 将Sample.mqh文件中的A类包含在“程序库”命名空间中,以避免出现冲突
namespace Library
{
#include "Sample.mqh"
}
//--- 在“程序库”命名空间中添加另一个类
namespace Library
{
class B
{
public:
B() {Print(__FUNCTION__);}
};
}
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//--- 使用全局命名空间中的A类
A a1;
//--- 使用“程序库”命名空间中的A和B类
Library::A a2;
Library::B b;
}
//+------------------------------------------------------------------+
/*
结果:
A::A
Library::A::A
Library::B::B
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
已经嵌套命名空间。嵌套命名空间可以无限制地访问其父系空间的成员,但是父系空间的成员不能无限制地访问嵌套命名空间。
namespace General
{
int Func();
namespace Details
{
int Counter;
int Refresh() {return Func(); }
}
int GetBars() {return(iBars(Symbol(), Period()));};
int Size(int i) {return Details::Counter;}
}
2
3
4
5
6
7
8
9
10
11
12
13
全局命名空间(Global namespace) 如果ID没有在命名空间中显式声明,则认为它是全局命名空间的隐式部分。要显式地设置全局ID,请使用范围解析操作符,无需命名。这将可以使您将这个ID与位于不同命名空间中具有相同名称的任何其他元素区分开来。例如,导入函数时:
#import "lib.dll"
int Func();
#import
//+------------------------------------------------------------------+
//| 某个函数 |
//+------------------------------------------------------------------+
int Func()
{
return(0);
}
//+------------------------------------------------------------------+
//| 脚本程序起始函数 |
//+------------------------------------------------------------------+
void OnStart()
{
//+--- 调用导入函数
Print(lib::Func());
//+--- 调用我们的函数
Print(::Func());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在本例中,从DLL函数导入的所有函数都包含在相同名称的命名空间中。这使得编译器能够清楚地确定要调用的函数。
另见
全局变量、本地变量、可视范围和变量的生命周期、创建和删除对象