# Python 学习文档
# 我的学习目标
- 写个 DOS 游戏的管理程序;
- 用来自动化操作 Office ,类似 脚本精灵;
- 爬虫 也想整一个;
- 网站也必须要试试,因为我好歹也学过点 前端 啊,Html5+Css+Js 多少也知道点儿;
- 能写个小游戏玩玩也不错;
- 没准做动画也用得上;
- 人工智能 不敢想,但听说可以用 Python 写程序自动打飞机,坦克大战之类的游戏,挺想试试,这也算机器学习吧,看看电脑玩游戏能玩出什么效果?
暂时就这么多吧……个人vx: 21523544
2020.12
关于学习的方法,个人感觉看书、图文并茂的那种最为合适。因为写下来的白纸黑字就是固定的,图片也是固定的。除非后面涂改,否则内容不会变化。除非把书烧了才会消失。不然知识就总会在那里、静静的、固定的。我的大脑也喜欢存储这种固定的知识,没明白的可以翻回去再复习一下。固定在大脑里的知识越多、自然大脑就越丰富。视频、音频这种流动的形式,在学习上真的只能用来辅助、比如观察一个过程的时候,视频可以看到连续的变化,确实是一个便捷的方式。但这种流动的媒体很容易被时间冲淡,而且对关键知识点的集中理解反而会有一些干扰。所以,即使是用视频来学习,也必须用笔写下关键词、截图或拍照固定住关键帧、只有固定下来,才有便于记忆,才是真正学会了,能应用。(也有的人的大脑就是适应流动的知识,他们的大脑更喜欢联动交互的知识点。因此学习方法也有所不同。各人选择最适合自己的方式就好了。另 2023 GPT走向大众了,人人都可以按自己的节奏来安排学习进度了,多好。 )欢迎加QQ群线上讨论:861129742
# 第 0 章 入门
2021.08
说实话也学了这么久了,感觉还没入门呢。主要是没找到用得上的地方,就是没有目标。所以自己乱摸,也不知道往哪个方向走。趁最近在整量化交易,用得是 中泰证券XTP 和 功夫量化,也是一些初级的Python语法,重整一下。
https://docs.python.org/zh-cn/3/
就有2个教程,这次好好学习下。
https://docs.python.org/zh-cn/3/tutorial
https://docs.python.org/zh-cn/3/reference/index.html
讲真,官方教程文档不是给人类看的!
2022年10月,Python 更新到了 3.11 版。传闻后续起码到 3.33 之后。所以 Python 4.0 先别想了。
开始之前先看看自己的电脑配置哈。不至于还有人比我还怀旧吧?我是 DOS 时代过来的人呢?哈哈。
现在主流的操作系统应该都是 win10 或 win11 了吧?硬件方面真的不需要过于纠结,可以这么说,只要是能正常开机进入桌面的电脑,用来学个编程基本都没什么压力。当然,你也不要为难自己嘛,非要用个古董机,卡得要死,开机都得2分钟的那种,何必呢?人生苦短,学习也好,工作也罢,能顺溜一点不好吗?下图的配置,仅供参考吧。

接下来当然是需要安装好 Python 环境。建议用 AnaConda 或 Miniconda (迷你,小巧的Conda环境)就足够了。方便、快捷、简单、高效,省好多折腾。以后学会了、用熟了,再自已安装必要的环境、库,都来得及。不要一开始贪多嚼不烂。

如果你是使用苹果电脑的用户,就可以直接开始撸 Python 了,因为苹果的 OS 系统已经内置了 Python 环境。因此可以直接跳到 0.4 节,选用你自己喜欢的代码编缉器就可以了。
# 0.1、安装 AnaConda
https://www.anaconda.com
长城之内访问上面那个链接又慢又卡,还是不建议了。还是用下面的 清华大学镜像 吧。
清华大学镜像
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
选择对应的 Windows installers 安装程序。
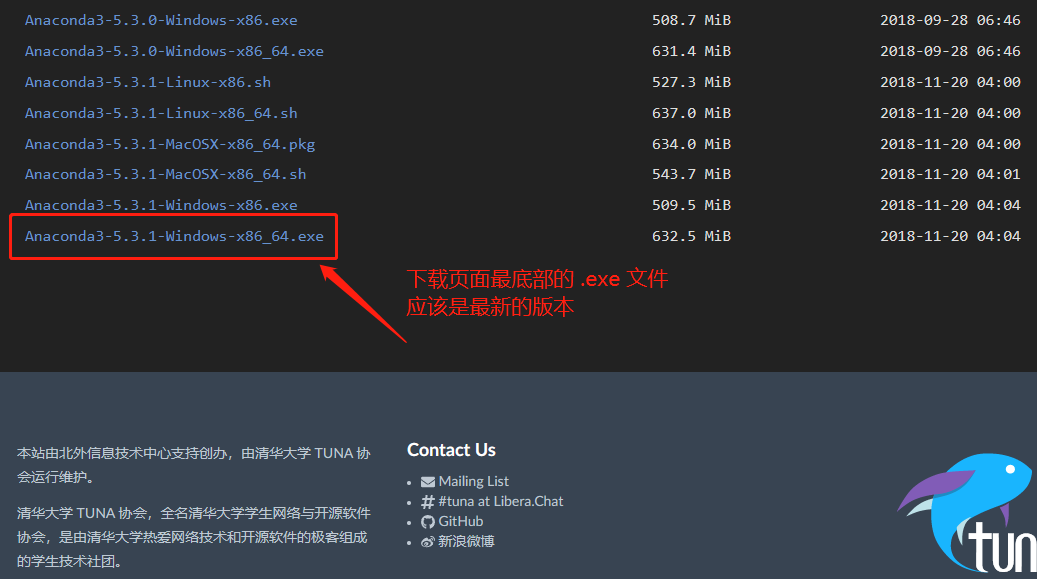
我用的是 Windows 10 64位系统,所以选择这个安装好之后,就自带了 Conda 环境和 Python。下载得到一个可执行的文件
Anaconda3-5.3.1-Windows-x86_64.exe
这是一个Windows的应用程序文件,大约 632.5M。双击即可开始安装、一路 Next(下一步),应该没有难度。
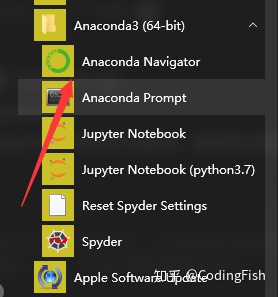
安装完成之后,在 Windows 开始 菜单中即可看到
- Anaconda Navigate
- Anaconda Prompt
- Jupyter Notebook
- Spyder
......等选项,如下图所示:
此时可以点击 Anaconda Navigate ,即可看到如下画面:
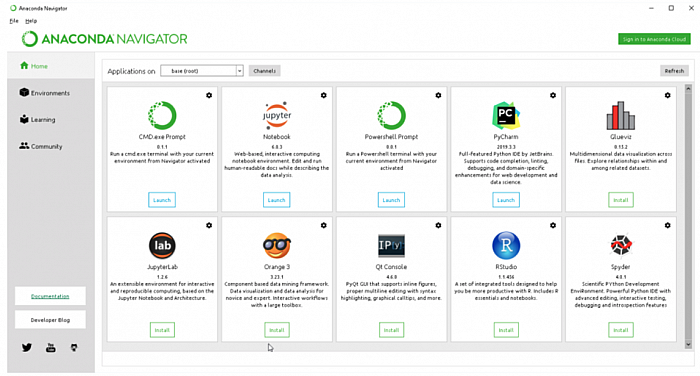
如果发现 Anaconda Navigate 卡住了,打不开。可能需要尝试更换 Anaconda 的源,请参考第三节的内容。
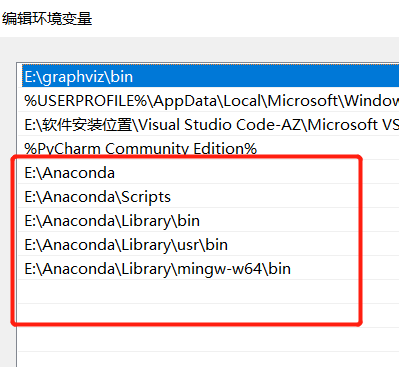
# 0.2、 Windows 添加环境变量
注意添加环境变量
此电脑——属性——高级系统设置——环境变量——path——编辑——新建
X:\Anaconda(Python需要)
X:\Anaconda\Scripts(conda自带脚本)
X:\Anaconda\Library\mingw-w64\bin(使用C with python的时候)
X:\Anaconda\Library\usr\bin
X:\Anaconda\Library\bin(jupyter notebook动态库)
2
3
4
5
请根据你自己安装时的路径,把这些文件夹路径,都添加到Windows 的环境变量中,避免以后使用时出错。
# 0.3、换成国内的下载镜像源
如果你比较老派,怀旧,可以考虑 把 pip 装上。其实 conda 就是用来代替 pip 的功能,用来管理 包、库和模块的工具,用 pip 的位置都可以用 conda 来代替。
在 Windows 中以 管理员身份运行 打开 命令行发送以下指令即可:
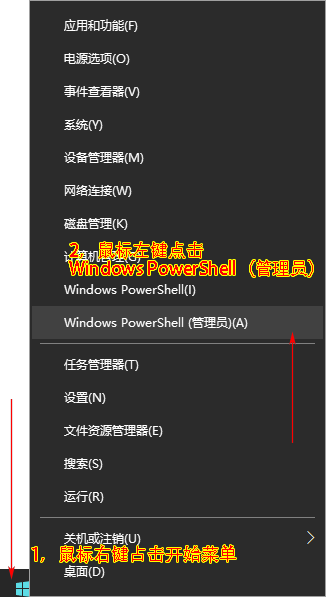
conda install pip

同时建议也更换一下 pip 的源,在 Windows 中,pip的配置文件叫 pip.ini,通常保存在文件夹:
C:\ProgramData\pip\
或
C:\用户\你的名字\AppData\Roaming\Python\
如果你找半天也没找着,可以用以下指令查询一下:
pip config debug
应该会看到如下类似的回应消息:
env_var:
env:
global:
C:\ProgramData\pip\pip.ini, exists: False
site:
C:\Miniconda3\pip.ini, exists: False
user:
C:\Users\Administrator\pip\pip.ini, exists: False
C:\Users\Administrator\AppData\Roaming\pip\pip.ini, exists: False
2
3
4
5
6
7
8
9
其中的路径即是 pip.ini 文件所在的文件夹。如果没有,可以在对应的文件夹中创建一个。其中的内容如下所示:
[global]
index-url=https://mirrors.aliyun.com/pypi/simple/
extra-index-url=
https://pypi.tuna.tsinghua.edu.cn/simple/
https://pypi.mirrors.ustc.edu.cn/simple/
https://pypi.douban.com/simple/
[install]
trusted-host=mirrors.aliyun.com
[freeze]
timeout = 10
2
3
4
5
6
7
8
9
10
11
如果是 Linux 系统 ,那么 pip 的配置文件通常名为 pip.conf,保存的路径为:
/etc/pip.conf
或
~/.pip/pip.conf
或
~/.config/pip/pip.conf
我换成了国内镜像,以后使用方便。
- 清华:https://pypi.tuna.tsinghua.edu.cn/simple
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
- 华中理工大学:http://pypi.hustunique.com/
- 山东理工大学:http://pypi.sdutlinux.org/
- 豆瓣:http://pypi.douban.com/simple/
检查一下是否修改成功,可以用指令: pip config list
升级 pip 的指令: python -m pip install --upgrade pip
找到 .condarc 文件,把其中的文本,替换成国内的镜像地址,这样可以大大提高下载更新时的速度,避免去境外网站下载,又慢又卡。通常这个文件在:
C:\用户\你的用户名\.condarc
顺便提示一下 Linux 系统中在
/home/你的用户名/.condarc
若没有这个文件就新建一个,注意文件名为 .condarc,不要有任何其他后缀。建议用 Notepad++,然后把下列镜像的链接地址,复制 —— 粘贴 到文件中,最后记得保存。
- 清华大学镜像
https://mirrors.tuna.tsinghua.edu.cn/
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 上海交通大学开源镜像站
https://mirrors.sjtug.sjtu.edu.cn
default_channels:
- https://anaconda.mirrors.sjtug.sjtu.edu.cn/pkgs/r
- https://anaconda.mirrors.sjtug.sjtu.edu.cn/pkgs/main
custom_channels:
conda-forge: https://anaconda.mirrors.sjtug.sjtu.edu.cn/cloud/
pytorch: https://anaconda.mirrors.sjtug.sjtu.edu.cn/cloud/
channels:
- defaults
2
3
4
5
6
7
8
- 中国科学技术大学 USTC Mirror
https://mirrors.ustc.edu.cn/
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
ssl_verify: true
2
3
4
5
6
完成之后,可以用以下指令检查是否有效:
conda config --show-sources
回应的信息中应该可以看到是否已显示为国内镜像源。
确定更新源都已经改好之后,可以输入以下命令:
conda update --all
此命令表示把所有的模块、包都升级到最新版。用国内的源,速度顺畅多了。请等待安装完成,然后重启一次电脑。
之后,你会感受到用国内的镜像,那速度嗷嗷的,也不报错了。
# 0.4、 选用 IDE(代码编缉器)
IDE(Integrated Development Environment)这事儿吧,各人习惯就好,其实选择也很多,如:PyCharm,VS code,GNU Emacs,IDLE,PyScripter,JuPyter/IPython Notebook,开心就好。
- 如果你安装了微软的 Visual Studio Code ,请在 Anaconda Navigate 中点击一次。这样以后 VS Code 中的 python 就是 Anaconda 环境了。既然用 Windows ,当然要用 VS Code 了。

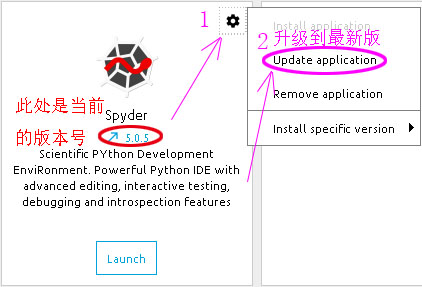
- 直接用 AnaConda 环境自带的 IDE —— Spyder ,真香。

建议把 Spyder 升级到最新版。在 AnaConda 界面中,点击 Spyder 框中的右上角的 齿轮 按钮。然后在出现的菜单中,点击 Update application
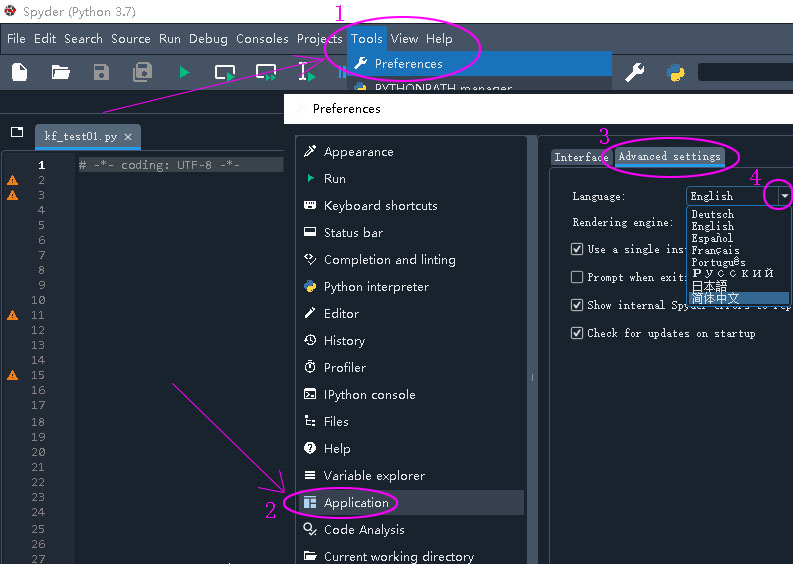
打开 Spyder 之后,如果想要切换到 简体中文。请按以下步骤操作:
- 点击主菜单上的 ”Tools --> Preferences“ ;
- 在弹出的窗口中,点击 ”Application“;
- 然后在右侧点击 ”Advanced settings“ 标签,即可看到 Language。
- 点击其后面的 向下三角按钮,即可打开一个下拉菜单,选择其中的”简体中文“;
最后最重要的一步,点击窗口右下部分的 “OK” 按钮。Spyder 会自动重启,重启后即是 简体中文 界面。
# 本篇小结
学习 Python 从安装 AnaConda 环境开始是正解。
I. 去镜像网站下载一个 .exe 文件,一路 next 就好了。
II. 安装完 AnaConda 之后,建议把 pip 也安装好。然后必须把文件夹路径添加到 Windows 的环境变量中。把下载源换成国内的镜像,conda 和 pip 的下载源也一起换成国内的镜像哦
conda install pip
然后用指令全部升级到最新版。
conda update --all
操作之后,重启一下。这样 Anaconda Navigate 就不会卡住了。
III. 选用自己喜欢的IDE,记得在 Anaconda Navigate 的界面中,点击一下就可以了。例如,微软的 Visual Studio Code,点一下就一切OK了。以后在 VS code 中用 Python 就是自带 AnaConda 环境了,少了诸多麻烦。
折腾环境,算是告一段落。
# 第一章 开始
之前我还看过 菜鸟教程 上的 Python 3 部分,还看过 廖雪峰 的 Python 教程。哎,还是菜得抠脚,没摸着门。讲得是很基础,但可能教程是想更全面、深入一点,就感觉有点乱了,不知道重点在哪儿了,所以有点犯晕。
借此机会重头再捋捋,试试看能不能捋顺了,捋明白了。
如前面准备的一样,我是在 Windows 10 64位版中学习 Python 的,我也安装好了 AnaConda 环境 和 VS Code(注意不是 Visual Studio )
# 1.1、 Hello World
不知道啥时候开始的,每种计算机语言,都是从 Hello World 开始的。好吧,我也不能免俗。具体的操作从先创建一个文件夹开始吧,文件的名称就用 studyPY 好了。
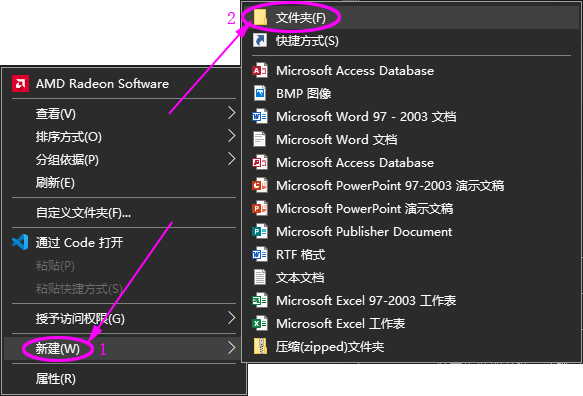
单击一下鼠标的右键,即可看到以上的菜单,在菜单中选择 “新建” --> “文件夹”。然后输入文件夹的名称即可:
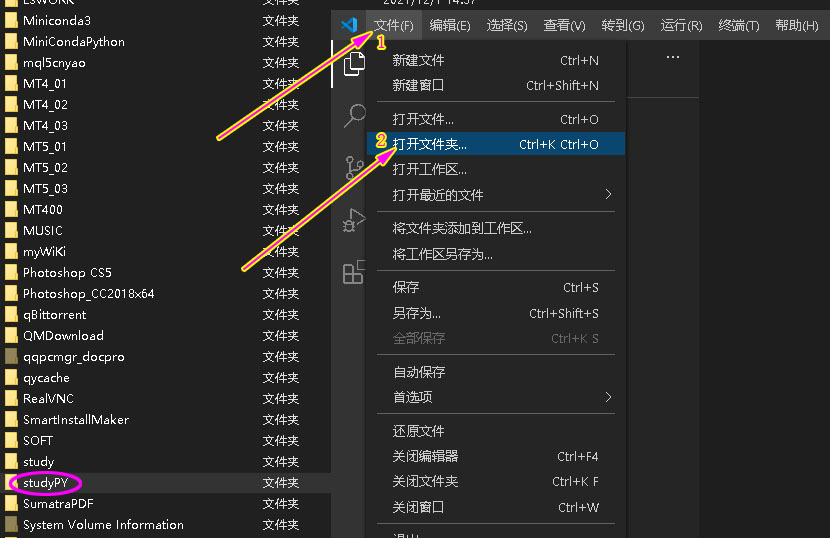
有了文件夹之后,就可以在 VS code 中,打开这个文件夹。依次点击菜单栏中的 “文件” --> “打开文件夹”,在弹出的窗口中,选择刚刚创建的文件夹 studyPY
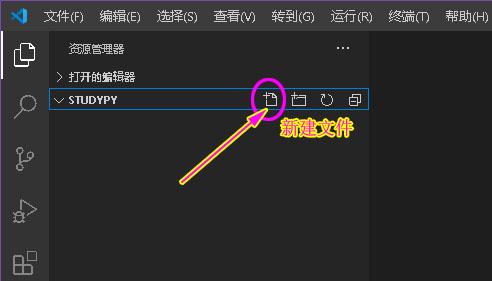
用文件夹来管理相关的文件,这是一个好习惯。在 VS Code 中即可看到添加的文件夹。用鼠标的光标指向这个文件夹里,在其后面会出现四个按钮,第一个即是 新建文件 按钮,点击即可新建文件。
在文件夹中创建第一个 Python 程序文件命名为: HW.py 吧。
X:\studyPY\HW.py
TIP
文件的后缀名为 .py ,表示这是一个 Python 的源码文件。比如 C++ 的源码文件是 .cpp, JavaScript 的源码文件是 .js,都是类似的概念。
新建的文件 HW.py,其中当然是啥啥没有。接下来手敲代码吧:
print("Hello World")
完成,这就是第一个完整的 Python 程序,记得要 保存。那么问题来了,这是干嘛呢?这程序有啥用?
用人话翻译一下就是:
“电脑,给我在屏幕上打印一串文本字符,就是“Hello World”。
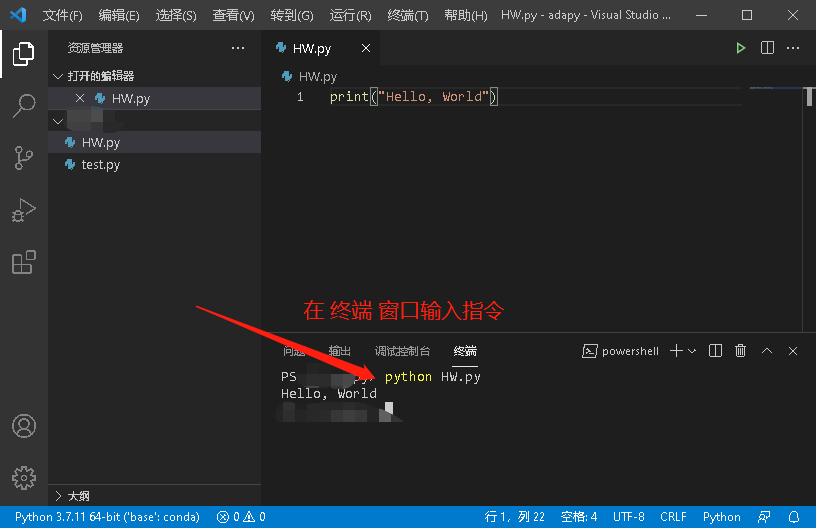
编程就是教电脑按我们的要求做事的过程。现在问题又来了,教是教了,但没看到有反应啊?刚刚我们完成的只是第一步,编写了源代码。但还没有执行啊,要执行一个 Python 程序,请在 VS Code 的终端窗口中,输入以下指令:
python HW.py
即可看到回应消息,这说明程序执行一切顺利。
到此,这就是编程的一个完整的过程了。写代码、执行,看结果。如果结果不对,那就得回到写代码的步骤,再来一遍,通常这个过程叫作: Debug。
如果执行的结果与预期的需求是一致(或是接近)的,程序就OK了。所以,程序员最怕两件事儿,
- 改需求。好不容易程序执行正常了,说有新需求,这谁接得住啊?
- Debug。代码敲错了,或逻辑写错了,也是让人很头疼的事儿;
所以,实际工作中,在敲代码之前,把需求沟通清楚、把逻辑想明白,才是重要的事儿。编程就是这么一回事儿:
- 沟通需求、梳理逻辑!(这是最重要的一步)
- 敲代码;
- 编译(解释)执行,看结果或错误消息;
- 根据结果或错误消息修改代码 ———— Debug;
回头再来看看我们的 Hello World 的例子。因为需求简单,所以没有考虑过多,就直接敲代码了。然而老程序猿的思维是:
- 只打印输出这个字符串吗?
- 是显示在屏幕上吗?
- 没有前提条件了吗?比如等2秒再显示?
- 没有后面的动作了吗?比如,显示10秒消失或换成别的文字?
- 没有其它要求了吗?
- ......
是不是很“轴”,很多疑,脑回路很清奇?
是的,写程序其实就是这样的,专业的术语叫作“逻辑闭合”,说人话就是必须要考虑周全。因为随着需求的复杂度,编写的程序也会是一个宠大的工程,其中某一条指令执行的结果,往往是牵一发而动全身,没准可能导致整个系统的崩溃,就来自一个小小的 Bug。
从用户的角度出发,当然是越简单越好。无论多么复杂的事儿,能给我一个万能如意按钮就好了,点一下就完成了,多好。但要达到这个目的,开始写程序之前,就得把各种情况要想好,考虑周全。否则可能就是南辕北辙、鸡同鸭讲。另一个原因,每个人的想法都是不同的,明明写好的程序,但使用程序的人偏偏要脑洞大开,花样玩耍......

这一开始就有 劝退 的味道啊,哈哈。
# 1.2、 字符集编码
这个问题很重要,尤其是我们要用到中文时,必须要注意字符集。简单说在 .py 源码文件的第一行,请写上:
# -*- coding:utf8 -*-
这样就OK了。这是一个好习惯,避免了很多乱码错误。只要是编程写代码,用 UTF-8 编码已经是一种国际惯例。非不写呢?就不听话,任性!那以后看到了一些奇奇怪怪的乱码字符,那就......开心就好。
到此,我们已经基本学会如何用 Python 编程了。打开一个文本,在其中一行一行的写代码就对了,写完之后保存。执行的时候用指令:
python 程序源代码文件名.py
就OK了。就这么简单!
# 1.3、 学习步骤
上一节,我们已经写出了第一个 Python 程序了,就是 Hello World。虽然很简单,但的的确确就是一个完整的程序。
print("hello World")
这个 print 通常被称为 指令、操作符 或 语句。按官网教程上的来吧,这种执行某些操作动作的指令,以后我们都称为 语句 。“Hello World” 是一串文本字符,是我们敲键盘输入的,告诉电脑的,这通常被称为 常量,就是一个确定的值,不会改变了。所以电脑就忠实地打印了一串文本字符。
其实 print 这个 语句 ,后面的圆括弧()也是它的本体,真正完整的样子是 print() ,这通常被称为 函数。可以理解为 函数 是一种 加强型的 语句。很多很多年以前,编程界早就是 函数式编程 的天下了(或称为 面向过程式编程)。几乎每一条 语句 都是一个函数,直观看上去每一条 语句 都是带 圆括弧 的。更早之前叫 指令式编程(就是 语句式编程),那已经是历史了。更时髦的是 面向对象式编程 (或 事件驱动式编程)。直观看上去,就是很多标识符都带个 句点(.),然后紧接着后面又是标识符。好了,打住,说多了又有劝退的味道了,不着急,慢慢了解。
学习一门计算机语言,基本都是如下步骤:
1, 认识输出信息的指令,如 print ,一般都是从打印输出 Hello World 开始;
2, 认识 数据类型,就是简单的整数啊,小数啊,数组啊等等;接着就是 运算符,比如,+ - * / ,比较大小,大于> 小于< 等于 ==,不等于 != 之类 ,与/或/非 之类,还有用得比较少的可能会有,按位运算啊…… ,需要注意的难点就是 运算优先级,就是常说的 先乘除后加减,圆括号内的最优先……
3, 认识 基本指令,最基本的包括:
赋值 指令,a=1+2 ;
条件分支语句 if else ;
循环 while for 等,用循环时肯定会有 跳到下一轮循环 continue 和 中断循环 break 指令;
4, 然后就开始有 函数,更早的时候叫 代码块。就是把一段代码写好,为了方便以后多次反复调用,就指定(赋予)一个名称,就像给一个变量赋值一样。之后,如果要用这段代码,就直接用这个名称就好了,这就是 函数名称。在操作系统中也称为 批处理,意即一次执行一批操作。
5, 认识了函数,就自然要用到 库(或叫做模块,包),简单说就是前辈们写好的一些常用的函数的集合,方便后学的程序员使用的。经常用到的,就叫 标准库 或 标准模块。了解的 函数库 越多,写程序就越快。好比一开始只认识几个字,写文章费劲。后来读的文章(例程)多了,就会写出精彩的文章了(因为大段大段的文字都是直接copy(摘抄)的,或是稍稍修改之后就可以直接用了)。编程过程中,鼓励多用前人写的标准库,提高效率。当然前提是学习、熟悉这些标准库(模块)。
6,再后来就要学习一些 文件操作,比如 打开、读取、写入、关闭之类的指令(或函数)。这里会用到与操作系统的交互指令。比如输入输出啊,图形界面啊……
7,现在计算机都用数据库了,计算机语言一般都有操作数据库的指令。
8,如今早就是互联网的时代了,任何计算机语言都或多或少要用到网络通讯的指令了。比如电子邮件、网页H5元素等。
9,再往后就很高级了,到这里,可以说基本已经可以熟练运用一门计算机语言了。然后多看需求、多看例子,好好运用计算机语言这个工具,帮助我们的工作和生活吧。
好了,打住。把新人小白全吓跑了,不要在意以上这些概念术语新名词都这么陌生,难懂。这不是正要学习嘛,那都懂了,就不用往下继续了,有个印象就行。一步一步的往前走。
# 1.4、 人机对话
人机对话 这个词今天来看仍然是很时髦的。想象中就是人说一句,电脑可以回一句,来言去语,交谈甚欢。其实呢,大多数情况下,就是刚刚我们用到的那个 print 指令,让电脑把信息打印出来,我们用眼睛去阅读。高级一点的方式就是转化成图形显示出来,因为人的大脑更喜欢看图片。时至今日(2021年8月),能用语音直接对话的电脑,还没有什么进展。所以......还是老老实实用 print 吧。
print 不仅能打印出一些文本,还可以打印数字计算的结果。比如:
# -*- coding:utf8 -*-
print("2+2 =",2 + 2)
print("50 -5*6 =",50 -5*6)
print("(50 - 5*6) / 4 =",(50 - 5*6) / 4)
print("8/5=",8 / 5)
2
3
4
5
上例十分简单吧?就是打印输出数字计算的结果,这简直小学生都会。所以,计算机程序就是如此,你给它指令和数据,它返回结果给你,这个过程就是 人机对话,这就是编程。高级点的无非就是用图形或声音来交流、互动。哎,说着说着,有点玩游戏的味道了。好好学习啊!
# 本篇小节
其实编程就是:
- 找数据,怎么找,上哪儿找,找到了存哪儿,用什么格式?所以 沟通 很重要,好好说话!
- 算数据,加减乘除还是比大小?字符串是不是要拼接起来还是要截取其中某一段?
- 看数据,显示在屏上还是打印?做成表格还是画个图?
# 第二章 数据类型 和 运算符
如前面所说的,计算机编程就是和数据打交道。曾经遇到有人提过一个问题:为什么有那么多种计算机语言,就用一种不得了?这是因为数据也有多种多样的啊。有的擅长处理文字、有的擅长处理数字、还有的擅长处理图像、视频的。Java 适合做电商、HTML5就适合写网页、C++适合驱动硬件......镙丝刀起子还分个一字型的和十字型(梅花型)呢,对吧。你要说非就用一把镙丝刀拧天下所有的镙丝,霸王硬上弓,大力出奇迹!也行,但别扭啊,有合用趁手的,为啥不用呢?
Python 号称是最适合 人工智能 的计算机语言。千里之行,始于足下。先别想多了哈,还是从基本的、简单的开始吧。
# 2.1、 数字
数字 是最基本的数据类型,在 Python 中有四种类型:整数、布尔型、浮点数和复数。
- 整数: 1,2,3,4,5,6,7,8,100,300,500,709,999;不带小数点后的数字就是整数。
- 浮点数: 3.14159126,12.79,300.87。带小数点后面的数字,就是浮点数。
- 布尔型:非 真(true) 即 假(false), 0表示 假,非0的值表示 真。
- 复数:如 1 + 2j、 1.1 + 2.2j。这个用得较少,复数包含 实部 和 虚部 两个部分。数学不及格……就沉默先。
# 2.2、 运算符
有了数字,必然的就要用到 运算符,就是 加减乘除,下表列出了 Python 中的 算术运算符:
# 2.2.1 算术运算符
| 运算符 | 描述 | 实例结果 |
|---|---|---|
| + | 加 | 10 + 20 结果 30 |
| - | 减 | 10 - 20 结果 -10 |
| * | 乘 | 10 * 20 结果 200 |
| / | 除 | 20 / 10 结果 2 |
| % | 取模 —— 返回除法的余数 | 20 % 10 结果 0 |
| ** | 幂 —— 返回x的y次幂 | 2**3 输出结果 8 |
| // | 整除 - 返回商的整数部分(向下取整) | 9//2 结果 4 -9//2 结果 -5 |
# 2.2.2 赋值运算符
计算了数字,总要先保存一下吧。这就要用到 赋值运算符 了。简单说就是先把计算的结果放在一个 变量 中,变量 可以想象为一个 盒子 ,用来临时放一下数据。前面我们已经看到这最简单的例子了,比如: a = 10 表示先把 10 这个数字,放在 a 这个 变量(盒子)中,呆会儿没准还要用的。
| 运算符 | 描述 | 实例结果 |
|---|---|---|
| = | 简单的赋值,把等号右边的值,赋予给左边的变量。 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值 | c += a 等效于 c = c + a |
| -= | 减法赋值 | c -= a 等效于 c = c - a |
| *= | 乘法赋值 | c *= a 等效于 c = c * a |
| /= | 除法赋值 | c /= a 等效于 c = c / a |
| %= | 取模赋值 | c %= a 等效于 c = c % a |
| **= | 幂赋值 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,用于在 表达式内部 为变量赋值。Python3.8 版本新增运算符。 | 意即在 if ,while 等语句中,给变量赋值。这样可以少写代码,显得很简洁。 |
age = 20
if age > 18:
print("已经成年了")
#以下是用 海象运算符 的例子,运行结果和以上的代码一致。
if (age:= 20) > 18:
print("已经成年了")
2
3
4
5
6
7
个人感觉,就用第一个 等号(=)赋值 就完了,简单清晰明了。后面的都属于炫技式的写代码方式,如果已经熟悉了Python 语言,那确实可以多运用。记得某大佬的酒后真言:“所谓好的代码,就是一年级新生都看得懂的代码。”(你非要装逼炫酷,显得高明,好吧,开心就好。)
# 2.2.3 比较(关系)运算符
为了比较数字大小就会用到 比较(关系)运算符,如下表:
| 运算符 | 描述 | 实例结果 |
|---|---|---|
| == | 等于 —— 比较是否相等 | (10 == 20) 返回 False |
| != | 不等于 —— 比较两个对象是否不相等 | (10 != 20) 返回 True |
| > | 大于 —— 比较x是否大于y | (10 > 20) 返回 False |
| < | 小于 —— 比较x是否小于y | (10 < 20) 返回 True |
| >= | 大于等于 —— 比较x是否大于等于y | (10 >= 20) 返回 False |
| <= | 小于等于 —— 比较x是否小于等于y | (10 <= 20) 返回 True |
所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量 True 和 False 等价。注意,Ture 和 False 的首字母是大写。
# 2.2.4 逻辑运算符
Python语言也支持 逻辑运算符 与/或/非
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | "与" —— x 和 y 都为 True 时,结果才为 True | (a and b) 返回 20。 |
| or | x or y | "或" —— 如果 x 或 y 有一个为 True,结果就为 True | (a or b) 返回 10 |
| not | not x | "非" —— 如果 x 为 True,返回 False 。反之亦然 | not(a and b) 返回 False |
# 2.2.5 成员运算符
在 Python 中还有颇具特色的运算符 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到指定值,就返回 True,否则返回 False | 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到指定值返回 True,否则返回 False | 如果 x 不在 y 序列中返回 True |
成员运算符比较有趣,请先参考下面的例子,如果没看懂没关系,后面会有更多的讨论:
a = 10
b = 20
list = [1, 2, 3, 4, 5 ]
if ( a in list ):
print ("1 - 变量 a 在给定的列表中 list 中")
else:
print ("1 - 变量 a 不在给定的列表中 list 中")
if ( b not in list ):
print ("2 - 变量 b 不在给定的列表中 list 中")
else:
print ("2 - 变量 b 在给定的列表中 list 中")
# 修改变量 a 的值
a = 2
if ( a in list ):
print ("3 - 变量 a 在给定的列表中 list 中")
else:
print ("3 - 变量 a 不在给定的列表中 list 中")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 2.2.6 身份运算符
Python 中还有 身份运算符
在 python 中,一切皆对象。好长一段时间,都不理解这句 “一切皆对象”是什么意思。现在可以简单的理解为,只要是一个 标识符,它都是带属性的(或 方法)。比如,
a = 100
这是一个最简单的赋值指令,声明了一个变量 a,同时赋值 100。声明的意思就是:告诉电脑,我要用一个变量了,这个变量叫 a ,它代表一个数字是 100, 以后我说 a 的时候,电脑你就要知道我 a 等于 100, 记住了哈!
TIP
用任何一种计算机语言编程时,声明 是一个很好的习惯。虽然这已经不是一个强制要求了。
因为在 python 中,一切皆对象。所以 a 也同时是一个对象,它有一个属性,id 。这个 id 可以理解为类似 c 语言中的指向内存存储地址的一个指针。我们称 a 为变量名, 100 为这个变量的值,a 还有一个 id 值,可以通过 id()来查看:(关于对象、属性 和 方法这些概念在 面向对象 章节还有更多的讨论。)
a = 100
print( id(a) )
# 结果可能是一串数字 23565234423 ,这就是 a 这个变量的 id,这个 id 是唯一的。
2
3
4
这个id 就好比 变量a 的身份证。那么 身份运算符 就是用来比较两个对象的 id 是不是一样的,是不是都指向同一个内存地址。
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
身份运算符 is 和 关系运算符 == 的区别
简单说, is 用于判断 变量引用的内存地址是不是一样; == 用于判断 变量 的值是不是一样。
a = [1, 2, 3]
b = a
print("b 和 a 是指向同一个内存地址吗? ",b is a )
print("b 和 a 是相等的吗? ",b == a)
# b 和 a 是指向同一个内存地址吗? True
# b 和 a 是相等的吗? True
b = a[:] # 把列表 a 全部截取,然后赋值给列表 b
print("b 和 a 是指向同一个内存地址吗? ",b is a)
print("b 和 a 是相等的吗? ",b == a)
# b 和 a 是指向同一个内存地址吗? False
# b 和 a 是相等的吗? True
2
3
4
5
6
7
8
9
10
11
12
13
14
如果一时没看懂也没关系,因为这个涉及到内存指针、深(浅)拷贝、等问题,说白了用得好,就可以节约内存,提升性能。但现在个人电脑内存都大,足足的。自己写点小程序,不在乎这一点半点。等到了编写服务器程序的时候,才会需要考虑这些深度的细节问题。那时候,就已经是大神了。
# 2.2.7 位运算符
Python 中当然也有用于二进制运算的 位运算符。个人认为这是每种计算机语言都有的,学计算机的人都考过的,但实际运用中用得最少的 运算符。大约 C 语言中用得多一点,因为与硬件打交道,用到 位运算 比较直接高效。
| 运算符 | 描述 |
|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。~x 类似于 -x-1 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 |
| >> | 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数 |
# Python 中的运算符小结
Python 语言支持以下类型的运算符:
- 算术运算符 ———— 加减乘除,取余数,求次冥,取整;
- 比较(关系)运算符 ———— 就是比大小;
- 赋值运算符 ———— 就是 等号(=),各种花式等号;
- 逻辑运算符 ———— 与、或、非
- 成员运算符 ———— 比较有特色,就是 in 和 not in
- 身份运算符 ———— 比较对象的 id 是否一样,涉及到内存指针等概念,用得少。
- 位运算符 ———— 用于二进制运算的操作,用得较少
前面几个应该都很好理解吧? 算术运算、比较(关系)运算、赋值和逻辑运算是经常用到的操作,成员运算 和 身份运算 比较有特色,后面会更详细的讨论。位运算符真的用得很少。(什么?你是大神,你的脑子就是二进制的?大佬大佬,66666)
运算符优先级
简单说就是 先乘除后加减,加上圆括号,就先运算。以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 乘方 |
+x,-x,~x | 正,负,按位非 NOT |
*,@,/,//,% | 乘,矩阵乘,除,整除,取余 |
+,- | 加和减 |
<<,>> | 移位 |
| & | 按位与 AND |
| ^ | 按位异或 XOR |
| | | 按位或 OR |
in, not in, is, is not, <, <=, >, >=, !=, == | 比较运算,包括成员检测和标识号检测 |
not x | 布尔逻辑非 NOT |
and | 布尔逻辑与 AND |
or | 布尔逻辑或 OR |
if -- else | 条件表达式 |
lambda | lambda 表达式 |
| := | 赋值表达式 |
建议初学者,老老实实的一行一行的写,让程序顺序执行就好。别整些妖娥子,自己折腾自己。
到现在为止,我们已经认识了 变量 (就是用来临时保存一下 数字 的盒子) 和 很多运算符。那么在程序中 变量 和 运算符 是经常一起出现的。单独的一个变量,或 运算符 孤零零的出现在程序中,几乎没有什么意义。它们通常是组合出现,这种由 变量 和 运算符 一起出现的组合,有个专有的名词,叫作 表达式。也就是说 表达式 通常都包括 变量(或常量,就是具体的数字) 和 运算符,并且一般情况下都有一个运算结果。
1+2 # 这个表达式,由2个具体的数字常量和 加号(+) 组成。运算结果为 3
a = 3 # 这个表达式,由变量 a 赋值运算符(=) 和 常量数字 3 组成。结果为 3
a / 2 # 这个表达式,由变量 a ,运算符除号(/) 和常量数字 2 组成。结果为 1.5
2
3
4
5
小复习一下,我们到现在已经认识了: 语句、常量、变量、运算符 、表达式。学会了好多新名词呢。
我们刚刚讨论了 Python 中的一种 数据类型,就是数字。数字包括了 整数、浮点数(小数)、布尔型和几乎用不上的 复数。接下来,我们看看Python中的六种标准数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
按是否可变来分类,可以分为:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合);
# 2.3、 字符串(String)
字符串,无疑是很重要的一种数据类型。每一种计算机语言几乎都要处理 字符串,因为这样才方便 人机对话 啊。经典的 “Hello World” 就是一个 字符串。
在 Python 中用 单引号 或 双引号 包括起来的文字就是 字符串,如:
'abcdefg'
"这是一个字符串"
'A' # 这是只包含一个字母的字符串
2
3
4
5
字符串 是可以用 运算符 加号(+) 来连接在一起的,例:
print('abcdefg' + "这是一个字符串" )
会得到结果 "abcdefg这是一个字符串" ,2个字符串合并在一起了。其实2个相邻的字符串常量如果写在一起,中间没有 加号,也没有别的其它符号,它们也会自动合并在一起的。加号运算符更多的时候是用在合并2个字符串变量的时候,用来构成一个 表达式。
字符串还可以用 运算符 乘号(*) 来重复自身几次,例:
print("这是一个字符串自己重复3次"*3 )
会得到结果 "这是一个字符串自己重复3次这是一个字符串自己重复3次这是一个字符串自己重复3次"
python 中的字符串最有特点的地方是自带 2套 索引编号,这也是最常用到的一个功能。
+---+---+---+---+---+---+
| a | b | c | d | e | f |
+---+---+---+---+---+---+
0 1 2 3 4 5
-6 -5 -4 -3 -2 -1
2
3
4
5
如上所示,python 中每一个字符串,都自带 2套索引编号:
一套是从左往右数,第一个字符对应的索引编号是0,第二个字符对应的索引编号是1,依次类推,最后一个字符对应的编号是(字符串的长度 - 1)
另一套是从右往左数,最右边的第一个字符对应的索引编号是-1,没错,就是个负数。向左数第二个字符对应的索引编号是-2,依次类推,最左边的字符对应的编号是 (-字符串长度)
用一对方括号([]),其中写上一个数字,就可以用来从一个字符串中取出一个指定的字符。见下例:
print("abcdef"[3])
print("abcdef"[-3])
2
3
得到的结果,都是字母 d 。请回答,这是为什么?
如果我们想从一个字符串中提取一个子字符串,那么就要用到 切片。
print("abcdef"[0:4])
print("abcdef"[-6:-2])
print("abcdef"[-6:4])
2
3
4
5
得到的结果,都是 “abcd”。
这就是切片,方括号中包括2个数字,中间用 冒号(:)隔开;
第一个数字,表示从字符串的哪一个索引编号开始;
第二个数字表示到哪一个索引编号结束,但不包括这个索引编号对应的字符。
上例中,索引编号 0 和 -6 都是指的字符串“abcdef”中的左边第一个字符a,然后第二个数字 4 和 -2 都是对应的字符 e,因此切片取出来的字符串就是 “abcd”,不包括字符 e。
通过上例,相信应该能充分的理解 Python 中关于字符串的 2套索引编号 的意义。
为了打印出一些特殊的字符,会用到 转义符 的概念。比如想要打印输出 (\) 这个字符。你会发现:
print('给我打印一个 \。' )
看上去没毛病啊?结果就报错了。因为这个 反斜杠 是需要转换一下才能打印出来的。需要写成如下的 语句 才行:
print('给我打印一个 \\。')
很容易就看到了 反斜杠 前面又有一个 反斜杠 ,这就是 转义符 的用法。这就是告诉电脑“反斜杠后面那个字符,给我原样打印出来哈”。那么需要用 反斜杠 转换一下的这种特殊的字符有多少呢?其实也不多,实际运用中也用得少。大约如下表所示:
| 转义字符 | 说明 |
|---|---|
| \n | 换行符,将光标位置移到下一行开头。 |
| \r | 回车符,将光标位置移到本行开头。 |
| \t | 水平制表符,也即 Tab 键,一般相当于四个空格。 |
| \a | 蜂鸣器响铃。现在很多电脑都不带蜂鸣器了,所以不一定有效。 |
| \b | 退格(Backspace),将光标位置移到前一列。 |
| \ | 反斜线 |
| ' | 单引号 |
| " | 双引号 |
| |在字符串行尾的续行符,即一行未完,转到下一行继续写。 |
其实要打印原样的字符,有个更简单的方法,就是在字符串前面加个小写字母 r ,如下例:
print( r'给我打印一个 \' )
这样字符串就原样打印输出了,不用什么 转义符。(咋不早说,有罪!)
如果想跨行连续输入一长串字符串,可以用连续的 三个引号 来包括住就好了,如:
print("""
三个双引号开始
中间可以写很多文本字符
这都第三行了。如果不想换行,后面写 反斜杠 \
三个双引号结束
""")
print('''
三个单引号开始
一般用来写 注释
三个单引号结束
''')
2
3
4
5
6
7
8
9
10
11
12
13
关于 字符串,我们就先讨论到这儿吧,这就不少了(头晕)。最重要的就是在 Python 中字符串自带 2套索引编号 ,这是最具特色的地方。理解了 索引编号 的概念,就可以玩 切片 了。切片 在实际运用中,是用得非常多的操作。
除此之外,关于 字符串, 还有很多花式 玩法:比如:
- 文本序列类型 的各种操作;
- 字符串的函数(方法);
- 格式字符串字面值;
- 格式化字符串语法 str.format();
- printf 风格的字符串格式化;
我们以后慢慢讨论......
# 2.4、 列表(List)
Python 中的列表(list)无疑是最具特色的一个数据类型了。毫不夸张的说,正是因为有了列表(list),才使得 Python 别具魅力、吸引了更多的人来学习运用,成为一种流行的计算机语言。
列表其实很简单,请看下面的例子:
x = "abcdefg"
y = ['a','b','c','d','e','f','g']
print(x)
print(y)
print(x[3])
print(y[3])
print(y[-4])
2
3
4
5
6
7
8
9
第一行是我们熟悉的字符串赋值给了变量 x,
第二行就是一个列表赋值给了变量 y,
然后,原样打印输出了 x 和 y,可以看到 列表是被一对方括号([ ])包含住的,每一个字符都是独立的,它们之间用 逗号(,) 分隔着。这就是 列表(list) 的特征。
(这不就是 数组 吗?)
接下来,我们看到 x[3] ,这不就是从一个字符串中取出一个指定的字符吗?数字 3 就是字符串的 索引编号。对,完全正确。
接下来一行 y[3] ,这表示从 列表(list) 中取出索引编号为 3 的元素。对了,一个列表也是自动带有 2套索引编号 的。这里的数字 3 也是表示 从左向右数, 索引编号 3,别忘了,是从 0 开始数的哦。
那么最后一行,y[-4],就和字符串一样,负数编号是 从右向左数 ,最右边的是 -1,这里就表示对应的 索引编号 -4 位置的元素。
那么请自己写出最终的打印输出的结果吧。
注意:如果 索引编号 的数字,没有对应的元素,会收到错误消息的。比如,明明列表(list)中只有 7 个元素,你非要取第10个,那当然就出错了。
那看了半天,这 列表(list)岂不是和 字符串 没区别?当然不是了,字符串里只能是字符嘛,列表(list)就厉害了,其中的元素可以是各种类型的。比如:
print(['abc','def','hello','world'])
print([1,2,3,5,7,9,100,256,64])
print([1.14 , 2.56 , 3.99 , 108.19 , 2000.01])
# 也可以把不同类型的数据都放在一个 列表中
print([0.99 , 2 ,1.138 ,100 , 2000])
print(['abc', 56 , 3.1415926 , 'X'])
# 当然也可以 列表中放列表
print(['hi', ['a','b','c'] , 999.99 , 1024])
2
3
4
5
6
7
8
9
10
11
12
建议初学者,新手还是先简单点,在一个列表中,只存放一种类型的数据为好,别给自己套娃,把自己套糊涂了,整不会了。(什么?你就是天才,你就是大神,好吧,你随意。)
# 2.5、 元组(Tuple)
认识了 列表(List)就必须要提到 元组(Tuple)了。别听着名字 元组 ———— 好像很霸气的样子。其实就是把 列表的 方括号 换成 圆括号 就 OK 了。
[1,2,3,4,5] # 这是一个列表
(1,2,3,4,5) # 这是一个元组
列表 和 元组 唯一的区别就是 一个可以修改,一个不可以修改。请看下例:
x = [1,2,3,4,5]
y = (1,2,3,4,5)
x[4] = 99 # 把 x 的4号元素,赋值为 99
print(x) # 输出结果,看看是不是把原来的 5 改成 99 了
y[4] = 99 # 把 y 的4号元素,赋值为 99,出错。
2
3
4
5
6
7
当你想要一个元素都必须确定,不可修改的数据时,就用 元组(tuple)吧,这样代码更安全。比如,用来比较数据时,保留一份不可修改的 元组 数据,就可以方便以后比对了。
那么 列表(list) 和 元组(tuple) 其它的特性都是一样一样的,比如 自带2套索引编号、可以切片、也都可以用内置函数 len()来获取元素的数量。
当然,列表(list) 中是可以有 元组(tuple) 的,反之亦然,相互套娃儿嘛。总之,大神玩得开心就好。
# 2.6、 字典(Dict)
如果说 列表(list) 让 Python 这种计算机语言别具魅力,那 字典(dict) 就是大放异彩,Carry 全场的技能。所以,我们必须要好好掌握。dict 全称 dictionary,在其它语言中也称为 map,使用 键-值(key-value) 存储,具有极快的查找速度。
一个字典的简单示例:
{0:'a',1:'b',2:'c',3:'d',4:'e',5:'f',6:'g'}
{-7:'a',-6:'b',-5:'c',-4:'d',-3:'e',-2:'f',-1:'g'}
上例中,就是 2 个字典(dict)。很显明,一对花括号包含的内容,都是用 逗号(,)分隔的,一对一对的,中间有个 冒号(😃 的形式出现的。冒号前面的称之为 键(key),冒号后面的称为 值(value)。
哎,看上去眼熟,咋看咋这么像把 索引编号 写出来的 字符串列表呢?从左往右 就是 0 到 6,从右往左就 -1 到 -7,对应的元素都是单个的字符。这明明就是把 索引编号 和 值 都写出来了的 列表(list)嘛。对了,好眼力,看得没错!字典(dict) 就是如此。但 字典 更强大一点,就是 这些 键 不仅可以是数字,也可以是 字符串 啊。这就好比,你家门牌上不仅可以是纯数字,还可以写上你的名字了,更好识别了一些吧?值 就没什么特别的了,和 列表(list) 中的一样,可以是任何数据类型。
确实可以这样理解,字典(dict) 就是把 索引编号 和 元素值 都可以写出来,还可以编辑修改的 列表(list)。其中 索引编号 ,不仅仅可以用 数字,还可以用 字符串。只要是 不可变的数据类型 就可以,也就是说,还可以用 元组(这就玩得高级了)。建议新手还是就用 字符串 吧,自己也清楚,别人也看得明白,少弦技(装逼)。注意一点,在一个 字典(dict)中, 键(key)是不能有重复的。值 就没有任何限制,和列表(list)一样,可以是各种数据类型。
既然和 列表(list)比较,那必须还要注意一点,因为 列表(list) 里的 索引编号 是自带的,不由你修改,所以列表(list)里的元素是有顺序的,要么你从左往右数,0、1、2、3、4......要么你从右往左数 -1、-2、-3、-4、-5......这个顺序,不会改变,没有第三种数次序的方式。但 字典(dict)中,把这个 索引编号 解锁了,你可以编辑修改,所以这种 从左往右 或 从右往左 的次序就没了。这一点需要注意,后面我们还会讨论这一特性。
字典(dict)更像是一个有两栏(列)的表格,左边一栏是说明这一行是什么数据,右边一栏就是具体的值。请看下面的一些例子:
# -*- coding:utf8 -*-
tel = {'张三': 82984098, '李四': 13857854898,'王五':8258455 }
print(tel) # 打印输出字典 tel
print(tel['王五']) # 打印字典 tel 中一个键名为 ‘王五’的值
del tel['王五'] # 删除一个 键
print(tel) # 再次打印字典,看看 删除成功没?
print ('李四' in tel ) # 还记得 成员运算符 吗?终于用上了
print('jack' not in tel) # 成员运算符,就是用在这里的。
2
3
4
5
6
7
8
9
10
11
12
13
现在知道 成员运算符 的用法了吧?就是查查,某个数据,是不是已经在 字典(dict) 中了,方便快捷。
# 2.7、 集合(Set)
认识了 字典(dict) 当然就要认识 集合(set)了(这句好熟啊,就像 列表(list) 和 元组(tuple))。
集合(set) 就是只包含 键 的一个 字典(dict)。键 是不会有重复的,所以在 集合(set)中,每一个元素都是唯一的。其它方面,集合(set) 和 字典(dict) 都是一模一样的,没什么差别。下面是一个 集合(set) 的例子:
{0,10,20,30,40,50,60}
{"Google", "bing", "Taobao"}
集合(set)也是一对花括号包含的内容,每个元素之间是用 逗号(,)分隔的。记住,这些都是 键(key),不是 值(value)。切记,切记。
# 本篇小结
内容还是很多的,现在小结一下吧。其实也就是 6 种数据类型 和 7 种运算符。
Python 中的数据类型有六种: List(列表)和 Dict(字典)是用得取多的,必须掌握。
| 类型 | 可变属性 | 是否有序 |
|---|---|---|
| Number(数字) | 不可变 | 包含4种,整数、小数(浮点数)、布尔数(0或非0)、复数(基本不用) |
| String(字符串) | 不可变 | 有序。自带索引编号,要么从左往右数,要么从右往左数。 |
| Tuple(元组) | 不可变 | 有序 |
| List(列表) | 可变 | 有序 |
| Set(集合) | 可变 | 无序 |
| Dict(字典) | 可变 | 无序 |
Python 中的运算符有七种:成员运算符比较有特色,最常用。
| 运算符 | 功能 |
|---|---|
| 算术运算符 | 加减乘除,取余数,求次冥,取整; |
| 比较(关系)运算符 | 就是比大小; |
| 赋值运算符 | 就是 等号(=),各种花式等号 |
| 逻辑运算符 | 与、或、非 |
| 成员运算符 | 比较有特色,用于字典、集合这种数据类型较多,方便。 |
| 身份运算符 | 比较对象的 id 是否一样,涉及到内存指针等概念,用得少。 |
| 位运算符 | 用于二进制运算的操作,用得较少 |
# 第三章 走向编程的第一步
在 Python 官方的 入门教程里,
https://docs.python.org/zh-cn/3/tutorial/index.html
以及 菜鸟教程 里
https://www.runoob.com/python3/python3-step1.html
都有对应的章节来讨论关于 流程控制 的问题。所谓 流程控制,说人话就是:做事的步骤。这就是程序。编程就是把做事的步骤给捋顺了,捋明白了。总共也就三种:
- 一步一步的顺序做,直着走。
- 路分叉了,做选择,走左边还是走右边?选A还是B。
- 重复绕圈走,走多少圈?
一步一步直着走,就不用说了,猩猩都会吧。做选择就难一点吧,很多人都有 选择困难症 吧?二选一还好,如果面对很多选择,立马就变成了只猴子,进了玉米地,不知道掰哪个好了。循环绕圈就更高级一点,就是把需要重复做的事,交给电脑去做,省人工。但简单的一个循环还行,循环套循环就晕了,多重循环就更......
# 3.1、 条件选择 if 语句
好吧,还是从一个简单的例子开始吧,终于开始正经八摆的写程序代码了。打开 VS code ,新建一个文件吧,名称可以写 ageif,当然你随意也行。
# -*- coding: utf-8 -*-
age = 3
if age >= 18:
print('你的年龄是your age is', age)
print('成年人adult')
else:
print('你的年龄是your age is', age)
print('你还小teenager')
2
3
4
5
6
7
8
第一行,是告诉电脑,这个文件是个源码文件,用的字符编码是 uft-8 ,这是个好习惯;
第二行,是一个赋值运算符,这个我们都认识。注意这一行的末尾是没有任何符号的,别的语言里,可能会有一个分号(;)作为结束符号 ;
第三行,是今天才认识的 if 语句,就是 “如果”的意思,后面是个 关系运算表达式,表达的是 age 大于等于 18,结果为 假。因为 age = 3 啊,3 小于 18 。这一行的末尾有个 冒号(😃,这个很重要。这就是 python 语言的语法规则,这个冒号是 if 语句 的一部分,不能缺失;
第四行 和 第五行 是我们已经很熟悉的 print 语句,就是打印输出圆括号()中的内容。需要注意的是,它们都往右边空了4个空格。这就是 python 语言的语法特色之一,一组代码块是用 空格 来区分的,而在其它语言中,基本都是用 花括号({})包含的。
TIP
我都习惯用 花括号{} 了,这下又整 空格,都把我整不会了。
第六行,也是今天才认识的 else: ,表示“否则”,承接前面的 if 是完整的一句话,“如果......否则......”,通常称之为 子语句。注意末尾也有个 冒号(😃,这个不能缺失。 第七行 和 第八行 和前面的 四、五行一样, print 语句,就是打印输出圆括号()中的内容。
整个程序表达的是:
如果年龄满了18岁了,就打印输出 你的年龄是your age is 18 成年人
否则,就打印输出 你的年龄是your age is 3 你还小teenager
其中的 如果 就是 if , 否则 就是 else ,这就是 条件控制,意即:路分叉了,做选择,走左边还是走右边?选A还是B。
上例中,打印输出什么,取决于 age 的数字。但例子中,age 是写在程序里面的,每次要打开源码文件,修改了,再保存,然后再运行这个 python 程序,好麻烦。试试下面这个例子吧:
# -*- coding: utf-8 -*-
age = int(input("请输入你家狗狗的年龄: "))
print("")
if age <= 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人。")
elif age == 2:
print("相当于 22 岁的人。")
elif age > 2:
human = 22 + (age -2)*5
print("对应人类年龄: ", human)
### 退出提示
input("点击 enter 键退出")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在这个例子中,我们用到了一个之前没有用过的(语句),就是input()函数,这个 函数 的功能是等待用户敲键盘输入一个数字。细心的朋友一定发现了前面有个 int ,这是表示输入的值一定是 整数 类型的数字。然后输入的值就放到了 age 这个变量中。接下来,根据 age 的大小,程序就开始选择分支,决定打印输出哪些文本信息。最后有一个提示,点击 enter 键,程序就结束了。
成功。到此你已完成了一个完整的,有输入、有输出的 人话对话 程序。
我们来看看 if 语句的完整体:
if <条件判断1>:
<执行语句1>
elif <条件判断2>:
<执行语句2>
elif <条件判断3>:
<执行语句3>
else:
<执行语句4>
2
3
4
5
6
7
8
用 if 开头,后面紧接着一个 条件判断表达式 ,意即,这个表达式的结果 必须是 非真(非0)即假(0) 的结果。然后根据 真/假 选择执行后面的语句,二选一。elif 其实就是 if 语句的子语句,表示又要做选择,前面的路又分岔了,必须要做出选择。如此这般,就可以实现多分支选择了。
初学的时候还是用好 if else 就好吧,捋明白才是重点。据说 Python 3.0 之后,支持多选一的语句了。因为别的计算机语言中都有类似 do case / switch 之类的指令,可以实现多选一的功能。
再看一个例子,巩固一下:
# -*- coding: utf-8 -*-
height = 1.75
weight = 80.5
bmi = weight/(height**2)
if bmi < 18.5:
print("体重过轻,注意营养")
elif bmi < 25:
print("体重正常,继续保持")
elif bmi < 28:
print("体重过重,适量控制")
elif bmi < 32:
print("已经肥胖,注意运动")
else :
print("严重肥胖,影响健康")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
请自已理解这个程序的每行语句,并写出运行结果吧。
记住完整的 if 是有 子语句 elif 和 else 的。
# 3.2、 多分支语句 —— match 语句
match 仅在 Python 3.10 版之后才有效。
a = 1
match a:
case 1:
print('case 1')
case 2:
print('case 2')
2
3
4
5
6
7
8
当变量a 不满足任意一个 case 条件时,如果我们没有对“其它”情况进行处理,那么是不会执行任何操作的。
如果想要对“其他”情况进行处理,那么写法如下:
# -*- coding: utf-8 -*-
a = 3
match a:
case 1:
print('case 1')
case 2:
print('case 2')
case x:
print('case x=', x)
2
3
4
5
6
7
8
9
10
11
可以看到,当变量a不符合任意一个条件时,就会运行到 x 分支,同时会把变量值赋值给 x 变量。
# 3.3、 循环语句
接下来,我们要讨论 循环 了。这无疑是所有计算机语言中最重要的事情了。我们为什么要编程?为什么要用电脑这个工具?就是想把枯燥、重复、还耗时耗力的工作交出去啊。
刚刚我们学习了 if 语句,其实就是做选择,根据条件执行 A 或 B。那么稍做修改,我们想要:条件没达到之前,一直转圈————重复执行一些指令。直到条件达到了,就不再重复了。跳出循环,再继续往后执行。
我们来认识一下 while 语句,请看下例:
# -*- coding: utf-8 -*-
sum = 0
counter = 1
while counter <= 100:
sum = sum + counter
counter += 1
print("从 1 加到 100 的和为: " ,sum)
2
3
4
5
6
7
8
9
10
第一行,我们都知道了,这是告诉电脑,这个文件的字符编码是 uft-8 ,这是个好习惯;
第二行是空行;
第三行 和 第四行 是 赋值运算符,我们也都熟悉了。用到了2个变量,sum 用来保存计算的结果,counter 用来计数;
第五行,是今天的主角 while 语句,表示 “当...的时候”,后面是个 关系运算表达式,结果为 非真即假,这一行的意思就是:“当 counter 小于 等于100 为真 的时候,就执行后面缩进的语句。当 counter 小于 100 为假 的时候,就是大于100的时候,就不再执行循环了,就要去执行后面的 语句”。注意这一行的末尾有个 冒号(😃,这个很重要。这就是 python 语言的语法规则,这个冒号是 while 语句 的一部分,不能缺失;
第六行 往右边空了4个空格,这是 python 语言的语法特色,表示这一行 语句 是 while 的循环体的一部分,也就是需要重复执行语句的一部分。这是一个 算术表达式,把 sum 和 counter 相加,然后把结果保存到 sum 中。
第七行 也往右边空了4个空格,表示这一行语句也是 while 的循环体一部分,也是需要重复执行的。这也是一个 算术表达式,把 counter 加 1,然后再保存到 counter 中,这样 counter 就是一个计数器了,循环每执行一次,counter 就会加 1。然后,会回到第三行,再来比较一下 counter 和 100 的大小。
第八行是空行;
第九行,是 print 语句,就是打印输出圆括号()中的内容。注意这一行是没有往右空格的,表示这是循环外面的语句了,只有 while 循环完成之后,再会执行到这里。
整个程序表达的是什么?这还用想吗?哈哈,就是计算从1加到100的 和 啊。
即然前面的 if 有 else ,那这个 while 有没有 else 呢?答案是有的!来看看完整本体吧
while <条件判断>:
<循环体中的重复执行的语句>
else:
<执行语句>
2
3
4
条件判断的结果为 true 时,就执行循环体中的语句块,如果为 false 时,则执行 else 后面的 执行语句。注意 while 这一行末尾的 冒号(😃 和 else 后面的冒号(:)很重要,不能缺失。while 也带有 子语句 else
关于循环,最常用的还是 for 语句,这个在各种计算机语言中,都支持。python 当然也不例外,直接来看看完整的本体吧。
for <循环变量> in <序列>:
<循环体语句>
else:
<执行语句>
2
3
4
for in 语句也是带有 子语句 else 的。
有心的朋友一定发现了,在 for 后面这不是一个 成员运算符 in 吗?但它真不是 成员运算符,它是表示“从一个序列数据中,一次取出一个元素,一直取到最后一个元素,只到没有元素可取了为止”。而成员运算符 是表示“这个元素 是/否 在数据中”。
我们先用字符串来试试:
# -*- coding: utf-8 -*-
x = "abcdefg"
for y in x:
print("从左开始,这次获取的 y 是 ",y)
else:
print("已经遍历过有序数据 a,循环结束。")
2
3
4
5
6
7
第一行,告诉电脑,这个文件的字符集用得是 UTF-8 国际惯例;
第二行是空行;
第三行 赋值运算符,我们也都熟悉了。用到1个字符串变量,字符串变量是自带索引编号的哟,而且还是带2套,从左往右,从右往左,都可以。
第四行 就是大名鼎鼎的 for 语句了,后面的 in 表达的意思是:“从 x 这个序列数据中,从最左边开始,每次取出一个元素,执行一次循环体内的语句,直到取到最后一个元素为止,就不再执行循环了。然后去执行 else 后面的语句”。注意这一行的末尾有个 冒号(😃,这个很重要。这就是 python 语言的语法规则,这个冒号是 for 语句 的一部分,不能缺失;
第五行 是 print 语句,就是打印输出圆括号()中的内容,特别把 y 也打印出来了,这样可以检查每次执行循环时,取出来的 y 是哪一个字符。
第六行 是 for 的 else 语句,表示循环结束后要执行的语句,注意 冒号(:)不能缺失;
第七行 是 else 后面的 print 语句,就是打印输出圆括号()中的内容,把 y 也打印出来了,可以检查下看看,应该是 x 中的最后一个字符。
程序执行的结果为:
从左开始,这次获取的 y 是 a
从左开始,这次获取的 y 是 b
从左开始,这次获取的 y 是 c
从左开始,这次获取的 y 是 d
从左开始,这次获取的 y 是 e
从左开始,这次获取的 y 是 f
从左开始,这次获取的 y 是 g
已经遍历过有序数据 a,循环结束。
2
3
4
5
6
7
8
Python 的 for 语句与 其它语言中的 for 是不同的。Python 的 for 后面的 in 不是成员运算表达式。它就是从一个有序数据中,从左开始,每次取出一个元素,执行一次循环体内的语句块,直到取到最后一个为止,就不再执行循环了。这个动作,通常称之为 迭代(或 遍历),而那些可以被遍历的数据,通常称之为 可迭代(Iteration)的数据。
而其它语言中,for 语句后面通常是一个 循环变量,然后很可能还有一个 关系表达式。每次循环中都会修改 循环变量 的值 ,然后计算 关系表达式的结果,根据非真即假的结果,再决定是否继续执行循环体。 这一点了解就好,先把 Python 搞明白吧。
刚刚那个 字符串 的例子太简单了,完全没有难度,我们再看一个用 列表(list)的例子:
# -*- coding: utf-8 -*-
x = ["abc",123,"hello","world",3.14159]
for y in x:
print("从左开始,这次获取的 y 是 ",y)
else:
print("已经遍历过有序数据 a,循环结束。")
2
3
4
5
6
7
这个显而易见,列表(list)也是可 迭代 的。肯定啊,因为 列表(list)和字符串一样,都是自带索引编号的数据,同时 元组(tuple)也是一样一样的。从左开始取元素,肯定是取得到的,理解这一点应该没有任何难度。
那么集合(set)呢?集合(set)就是只包含 键 的一个字典(dict),每一个元素都是唯一的,但是集合(set)是不带 索引编号的。答案是 集合也是可迭代(Iteration)的数据。从左开始取 集合(set) 中的 键,一个一个的取,是可以取到最后一个的。但是因为不带索引编号,所以有可能 取到的顺序 和 保存的顺序 不一样。
最复杂的来了,那 字典(dict) 是可迭代(Iteration)的数据的吗?字典(dict)中保存的都是 键-值 对啊,一对一对的怎么遍历?
答案:YES。默认情况下,字典(dict)迭代的是 键(key)。如果要迭代 值(value),可以用 for value in d.values(),如果要同时迭代 键(key)-值(value),可以用 for k, v in d.items()。
TIP
合着就是说 python 中的数据类型除了 数字,都是可迭代(Iteration)的呗。都可以用在 for 语句中来当作循环条件。数字当然不用迭代了,数字咋遍历?遍历啥?从1数到无穷大啊?死循环啊?
好了,现在我们终于认识了 Python 中的 for 循环了,它果然与众不同。那么我们现在实际运用一下,把前面那个例子,就是 从 1 累加到 100 的程序,用 for 循环来实现一下吧。记住哦,for 循环中用得是 遍历,要用到一个 可迭代 的序列数据。没有 关系表达式,更没有自已可修改的特环变量,哎,这还真难住了,难道要写:
y = 0
for x in [1,2,3,4,5,6,7,8,9,10,11,12,13......98,99,100]
y = x + y
print(y)
2
3
4
5
这岂不是连小学生都不如?
所以,我们需要用到一个内置函数 range(),它经常用来和 for 配合,生成一个数字序列,用于遍历最合适不过了。
举个例子,如果想要生成一个 列表(list),包含[1, 2, 3, 4, 5, 6, 7, 8, 9, 10......98,99,100],那就可以用range(1, 101) 来实现:(早说嘛,这省事儿多了。)
y = 0
for x in range(1,101):
y = x + y
print(y)
2
3
4
5
试试看运行的结果是什么吧?
关于 循环语句,前面我们看到本体的时候也认误了 子语句,例如 else 。接下来还有2个子语句需要了解下 break 和 continue
- break 就是字面意思 ,中断循环,跳到循环体外面去。通常在 if 语句中,表达当某情况出现时,中断循环。请见下例:
# -*- coding: utf-8 -*-
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('循环结束')
2
3
4
5
6
7
8
上例中,原本是想计算 1 到 100 累加的结果的,但中途到 11 的时候,就中断了,跳出了循环。
- continue 也是字面意思 ,在循环过程中,跳过当前的这次循环,直接开始下一次循环。通常在 if 语句中,表达当某情况出现时,跳过本此循环,执行下一次循环。
# -*- coding: utf-8 -*-
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)
2
3
4
5
6
7
原来是想一个一个打印输出 1 -- 10 的数字,但用了 continue 之后,遇到偶数,就跳过了。所以打印输出的数字,就全是 奇数了。
作为本篇最后一个登场的语句 pass ,看上去真像一个 子语句,但其实并不是。pass 就是一条正经的语句,用得也挺多。实际上 pass 语句不执行任何操作,表达的意思就是 “过”,通常用来做为 占位符。比如一时还没想好用什么 子语句,就写个 pass ,以后想起来了再写。
# 本篇小节
到这里,可以说已经 Python语言入门了。因为我们已经可以自己动手敲代码了,写出完整的程序,成功运行好多次了。
- 运用了 if 语句实现了条件分支的控制,还用到了 子语句 elif 、 else;
- 用 input()函数,我们还写了一个完整的,可以交互的人话对话程序;
- 认识了 while 循环语句,而且它也带有子语句 else;
- Python 中的 for 循环确实不一样,是通过 遍历可迭代(Iteration)的数据来实现循环的。关于 可迭代 的概念,后面还会有更多的讨论;
- 认识了 range() 函数来生成可迭代的列表,配合 for 循环;
- 循环的子语句 break, continue 是必不可少的,通常都必须和 if 配合使用,表示当出现某个条件时,中止循环或跳过本次循环。
- 很像 子语句 的 pass 语句,它是什么都不干的占位符。
# 番外篇 Python 代码规范
既然都开始写代码了,不得不插入这一篇来聊聊 Python 的代码规范,有的地方也叫 语法风格。就好比已经要开始正经写字了,就要写在格子里,写的整齐规范,养成好习惯。
如果一开始就强调这一点,貌似太早了点。因为都不知道从哪儿下笔呢,就说什么应该写方块字、要写得整齐、每个字要写在格子里,让人听着就有浓浓的劝退的味道。到现在为止,已经写了几个小程序了,麻雀虽小、五脏俱全嘛。所以现在就开始养成正确的书写规范正当时。
言归正传。Python 的源代码文件其实就是一个文本文件,当然其它的高级编程语言的源代码文件也都是文本文件。今天这些文本文件的字符集都是 UTF-8 ,这已经国际惯例了。
第一,无论是用什么文本编辑来写 Python 的代码,请在第一行写上:
# -*- coding: utf-8 -*-
第二,一条语句写一行。虽然 Python 中允许在一行中写多条语句,甚至还可以看到用分号(;)来做为分隔符。但还是强烈建议,在 Python 源码文件中不要出现任何 分号(😉,以免扰乱思维。
第三,建议一行中最多写 79 个英文半角字符。虽然允许用 反斜杠(\) 来分行书写。但请尽可能避免用 反斜杠(\) 来连接很长的一行。
第四,写注释无疑是程序猿的好习惯。Python 中的注释以 井号(#) 开头后空一格,可以写一行注释。多行注释可以用3个连续的 单引号或双引号('''/""")包括住即可。注释即可能 言简意骇 ,一两句话能说清楚即可。
第四,缩进是 Python 语言的最大的特色了。强烈建议用 4 个空格,不要用 Tab键!。必须记住的是,当开始用 空格 书写缩进的第一行代码时,上一行代码的末尾应该有一个 冒号(😃 作为这一段代码块的起始标志。
第五,善用 空行 让程序代码更容易阅读。
第六,圆括号不要滥用。因为很容易和 元组(tuple) 弄混。
规范要说起来还有很多很多,点点滴滴、细节处见功夫嘛。但暂时就先说这些,后面随着学习的深入,用到的时候再提示也不迟。
本章就到这里吧。
# 第四章 函数——不要重复你自己
终于,我们要开始讨论 函数 了,也就是开始 面向函数 编程了。如果掌握了 函数,不说天下我有吧,至少也可以闯荡江湖了。下一个更高阶的功力就是 面向对象 了,如果练成了那绝对可以列入高手的行列!什么,你不要看 函数,直接就玩 面向对象?敢问大佬,你是何方神圣?失敬失敬。
程序员有个信条叫做“不要重复你自己(Don’t repeat yourself, DRY)”
# 4.1、 Python 中的内置函数
其实,在前面的学习过程,我们已经认识了几个函数,比如: print()、input()和 range(),他们和 语句 一样,都是执行一些操作。如果说有什么区别的话,最明显的莫过于,函数 都带有一对圆括号()。Python 中内置了一些 函数,可以直接使用。就如同 print(),input()这些一样:
| abs( ) | dict( ) | help( ) | min( ) | setattr( ) |
| all( ) | dir( ) | hex( ) | next( ) | slice( ) |
| any( ) | divmod( ) | id( ) | object( ) | sorted( ) |
| ascii( ) | enumerate( ) | input( ) | oct( ) | staticmethod( ) |
| bin( ) | eval( ) | int( ) | open( ) | str( ) |
| bool( ) | exec( ) | isinstance( ) | ord( ) | sum( ) |
| bytearray( ) | filter( ) | issubclass( ) | pow( ) | super( ) |
| bytes( ) | float( ) | iter( ) | print( ) | tuple( ) |
| callable( ) | format( ) | len( ) | property( ) | type( ) |
| chr( ) | frozenset( ) | list( ) | range( ) | vars( ) |
| classmethod( ) | getattr( ) | locals( ) | repr( ) | zip( ) |
| compile( ) | globals( ) | map( ) | reversed( ) | __import__( ) |
| complex( ) | hasattr( ) | max( ) | round( ) | |
| delattr( ) | hash( ) | memoryview( ) | set( ) |
是不是很多啊,密集恐惧症都犯了。其实这些内置的函数,可以参考 《Python 标准库》 中的 内置函数,链接如下:
https://docs.python.org/zh-cn/3/library/functions.html
用到的时候,就像查字典一样,去了解他们的用法就可以了,不必死记硬背。当然你天赋异禀、过目不望还能理解透彻,用起来得心应手。大神大神————求膜拜。
从上表中可以看到,函数通常由 函数名称和一对圆括号组成。其实函数的完整体包括:函数名称(有时也被称为 句柄)、一对圆括号、圆括号中包括的是一个参数列表 以及 函数体。并且通常一个函数会有一个返回值,意即函数执行完毕后有一个结果。
# 4.2、 用户自定义函数
除了内置函数之外,编程工作中用得最多的,就是自定义函数了。听起来好像很难的样子,其实就是把经常要用到的一些 语句,或者 需要反复使用的一些代码块,写好、保存好,给他们起个名字。这样做就是为了方便以后直接用一个名称来调用执行一个代码块,免得每次要用的时候又得写一遍代码。好处很明显,省时省力省脑子。比如循环体中的那些代码块,就可以写成一个自定义函数,这样再用的时候,就直接调用函数就可以了。免得又把循环体里面的代码又抄一点,复制粘贴也累啊,而且还有可能粘错。
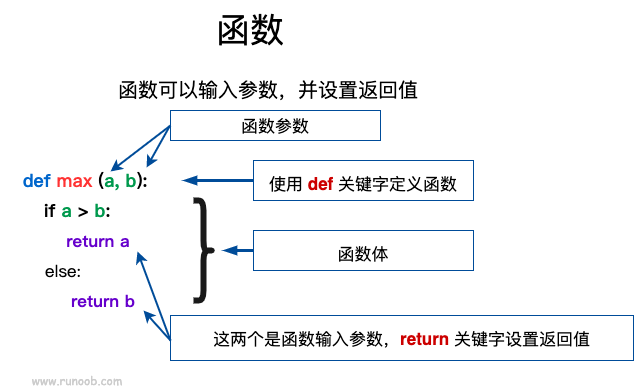
写一个自定义函数很简单,用关键字 def 开头,然后空一格写一个函数名,这个名称不要用中文,也不要用一些奇奇怪怪的名字,方便以后要调用的,简单明了就好。紧接着是一对圆括号(),圆括号中可以写上参数列表,这些参数被称为 形式参数,中间用 逗号(,) 分隔。最后以 冒号(😃 结尾。接下来一行,就应该是 函数体 了,必须 缩进 4个空格,记住要遵循 Python 的语法规范哦!然后就可以一行一行的写具体的 语句 了,最后可以用 return 返回一个或多个结果值,其实就是一个 元组(tuple),当然也可以省略,什么也不返回。
def 函数名(参数列表):
函数体
return(返回值列表)
2
3
我们来看一个简单的例子吧,在学习循环的时候,我们已经理解了下例中的代码是用来求 1 加到 100 的和。
# -*- coding: utf-8 -*-
sum = 0
counter = 1
while counter <= 100:
sum = sum + counter
counter += 1
print("从 1 加到 100 的和为: " ,sum)
2
3
4
5
6
7
8
9
现在我们学到了 函数,上手改写试试吧。
# -*- coding: utf-8 -*-
def sum100(x):
sum = 0
counter = 1
while counter <= x:
sum = sum + counter
counter += 1
return(sum)
x = 100
print("从 1 加到 100 的和为: " ,sum100(x))
2
3
4
5
6
7
8
9
10
11
12
13
第一行,坚持我们的好习惯,告诉电脑我们写的源码文件是 UTF-8 字符集;
第二行,是空行;
第三行,就是我们刚刚学习的 自定义函数的写法。用关键字 def 开头,然后空一格写了一个函数名 sum100,紧接着是一对圆括号(),圆括号中有一个 x,代表一个 形式参数,表示这个函数需要传入一个参数。最后以 冒号(😃 结尾;
第四行 到 第八行,简直就是照抄 循环例子中的原文嘛,这个就不解释了;
第九行,是空行;分隔一下,方便阅读,这也是个好习惯;
第十行,是函数中用到的 return 语句,表示函数执行完之后,把圆括号中的东东传出去,就像报告一下结果;
第十一行,是空行;这里我们写的自定义函数已经结束了;
第十二行,声明了一个变量 x =100,很明显这是为 函数 的形式参数准备的;
第十三行,最精彩的部分来了。调用自己写的函数,真香。打印输出的时候,直接就写上了 函数名,同时传入参数 x,这里的 x = 100 哦。
那么程序运行的结果是:(请你来回答吧)
在这么一个小例子中,应该或多或少体会到了使用函数的好处了吧?一次书写,反复调用。关键是还可以传入参数、返回结果。试试把上例中的 x 修改为 1000,试试吧。实际上,我们已经把一个 计算1加到100的循环,修改成为了一个 可以计算 1 加到 任意整数 的函数了。这个任意整数由 形式参数 x 来决定。并且随时可以调用这个函数,传入不同的数,就会得到不同的结果。厉害吧。
再来看一个例子:
# -*- coding: utf-8 -*-
# 计算矩形面积的函数
def area(width, height):
return width,height,width*height
w = 4
h = 5
a,b,c = area(w, h) # 复合赋值语句,函数返回3个值,一次赋值给3个变量。
print("宽的单位 =", a, " 高的单位 =", b, "\n 面积为宽*高 =", c)
2
3
4
5
6
7
8
9
10
11
请自行分析例子中的每一行代码所表达的意义吧。比较炫技的大约是第9行,这是 Python 中特有的 复合赋值语句,就是在一行中给多个变量赋值。并且自定义函数返回了3个值,这一行就把3个值都分别赋给了3个变量。
自定义函数,就是如此简单、方便。下一节,我们更详细的讨论 形式参数。因为函数的魅力所在,就是因为可以传入不同的参数,计算出结果,然后返回回来。函数定义完成之后通常不会大的改动,但可以通过传入不同的参数,获得想要的结果,这多厉害啊。
# 4.3、 函数的形式参数
自定义函数时,首先要确定的,除了函数名 ,就是 参数 了;这些参数决定了交给函数的是什么数据,以便后面的函数体获得这些数据,然后加工计算,最后把得出的结果用 return 语句传回来。我们需要做的就是把参数的名字和位置确定下来,然后在调用这个函数的时候,只需要传递正确的参数,就能获得正确的函数返回值。
在 Python 中,写一个自定义函数非常简单,但灵活度却非常大。这体现在参数的设置上,玩法花样可多了,我们慢慢来看。
# 4.3.1 位置参数(必备参数)
前面那个计算矩形面积的函数,用到了2个参数,宽 和 高,有了这2个数据,才能计算出一个矩形的面积。这2个参数,通常被称为 位置参数。意即,参数是对号入座的,位置次序是固定的。而且必须有,不能缺少。所以也被称为 必备参数。如果函数参数中设置了2个 位置参数,但调用的时候只给一个 或 一个参数都不给,就会出错:
# -*- coding: utf-8 -*-
# 计算矩形面积的函数
def area(width, height):
return width,height,width*height
w = 4
h = 5
a,b,c = area(w) # <-- 这里只传入一个参数,会出错的。
print("宽的单位 =", a, " 高的单位 =", b, "\n 面积为宽*高 =", c)
# 注意第 9 行,只传入了一个参数
# TypeError: area() missing 1 required positional argument: 'height'
# 错误: area()函数缺失了一个必需的位置参数: height
2
3
4
5
6
7
8
9
10
11
12
13
14
15
由例子可见,函数的 位置参数 就像设置好的座位,在调用函数传入参数的时候就必须要按参数的实际数量对号入座,不能缺少,少一个都不行,否则函数就出错了。要求2个参数,就必须要传入2个参数,并且传入的参数是按 位置 的次序对号入座的。这时我们不需要知道函数的形式参数的名称,只需要注意需要参数的个数和次序就可以了。
# 4.3.2 关键字参数
如果已经知道了函数的形式参数的名称,那么这些名称就可以看作是 关键字。传入参数时,我们就可以按这些关键字来传入参数值,而不用按位置和次序来对号入座了。换言之,就是按名称来对号入座,而不是按次序的位置了。同上例,我们就可以看 关键字参数 来调用函数,传入对应的参数值。
# -*- coding: utf-8 -*-
# 计算矩形面积的函数
def area(width, height):
return width,height,width*height
a,b,c = area(height=5,width=4) # <-- 这里只传入一个参数,会出错的。
print("宽的单位 =", a, " 高的单位 =", b, "\n 面积为宽*高 =", c)
2
3
4
5
6
7
8
9
10
注意第 7 行,我们在调用函数的时候,没有按函数定义时的次序传入参数。而是用了 形式参数名称 = 值 ,这种形式来传入参数,运行结果也是正确的。所以,如果已经知道了一个函数的形式参数的名称,就可以用这种方式来传入参数,这样可以更加 精准 的传入对应的参数。
# 4.3.3 特殊参数(命名关键字参数)
那么问题来了。调用函数的时候,即用 位置参数 来传参数,又用 关键字参数 的方式来传参数,可不可以?(你咋那么秀呢?)答案是:可以。
但是,为了加以区别和限制,在 定义函数里,会用到 斜杠(/) 和 星号(*)来表示:哪些参数是按位置,哪些参数是按关键字 来对号入座的。请看下面的例子:
# -*- coding: utf-8 -*-
# 计算立方体体积的函数
def volume(length,/,width,*, height):
return length,width,height,length*width*height
a,b,c,d = volume(8,height=5,width=4)
print("长的单位 = ",a,"宽的单位 =", b, " 高的单位 =", c )
print("体积为 =", d)
2
3
4
5
6
7
8
9
10
11
第四行 自定义函数时,参数部分包含了 斜杠(/) 和 星号(*),
- 斜杠表示前面的参数 length 必须按 位置参数 的方式来对号入座;
- 星号(*)表示后面的参数 height 必须按 关键字参数 的方式来对号入座;
- 中间那个 width 则没有要求;即可以用 位置 ,也可以用 关键字 方式来对号入座;
第七行 那么在调用函数volume的时候,传入参数时,就得按定义时的方式来对号入座了,不能写错。否则就会收到错误消息。不信就自己动手试试吧,比如传入第一个参数时,就非要写上 关键字,如下所示:
a,b,c,d = volume(length = 8,height=5,width=4)
会得到什么结果呢?
TIP
我谢谢你,少玩花样。
调用函数时传入参数这件事,是一件要求精准精确的操作。轻则程序出错,函数无法执行。重则全盘崩溃得出意外的结果。因此小心谨慎为上,少玩花样。
# 4.3.4 默认参数
在定义函数的形式参数时,直接写一个默认值就是 默认参数 了。这样即使调用函数时没有传入参数,但有默认值,函数还是可以用默认值正常运行的。另外,也不影响传入参数,因为从外部传入的参数会替换默认值,函数会优先按传入的参数执行、当缺失参数,就会按默认值执行。这下显得聪明多了。
例如:
# -*- coding: utf-8 -*-
# 计算矩形面积的函数
def area(width=4, height=5): # <-- 定义参数时写上了 默认值
return width,height,width*height
a,b,c = area() # <-- 这里一个参数都没有传入。
print("宽的单位 =", a, " 高的单位 =", b, "\n 面积为宽*高 =", c)
# 运行正常
a,b,c = area(10) # <-- 这里按 位置参数 传入了 width 的值
print("宽的单位 =", a, " 高的单位 =", b, "\n 面积为宽*高 =", c)
# 也运行正常,并且是按传入的值进行计算的。
a,b,c = area(height=20) # <-- 这里按 关键字参数 传入了 height 的值
print("宽的单位 =", a, " 高的单位 =", b, "\n 面积为宽*高 =", c)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
WARNING
注意: 定义函数时,形式参数都写上默认值是个好习惯。如果不是每个参数都有默认值,请把 有默认值的参数,次序放在后面,即靠右的位置。没有默认值的参数 放在前面,即靠左的位置。参数的默认值一定是个 不可变数据,即:Number(数字)、String(字符串)、Tuple(元组);再说直白点,就是一个确定的值。
使用默认参数最大的好处就是可以简化函数的调用。
初学者把 形式参数 用好,先注意以下两点:
- 定义 形式参数 时赋值一个 默认值 是好习惯,记住形式参数的默认值一定是 不可变数据
- 传入 形式参数 时,按 位置 或 关键字 对号入座;
这就 OK 了。这有助于思路清晰,程序代码也清晰。实际运用中也足够应付大多数的现实问题。
# 4.3.5 可变数量参数(不定长参数)
在实际工作中,有一种情况虽然很少出现,但确实会遇上,那就是事前无法确定参数的数量。可能这次需要2个参数,下次可能需要5个参数。这个没办法在定义函数的时候就写好。这时候,就要用到 可变参数(又称 不定长参数)了。请看下面的例子:
# -*- coding: UTF-8 -*-
def printinfo(x, *y):
"打印任何传入的参数"
print("输出: ")
print(x)
for var in y:
print(var)
return
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, 60, 50 )
2
3
4
5
6
7
8
9
10
11
12
13
第三行,自定义函数时,在参数列表中,第一个是必备的位置参数,意即调用这个函数时,必须传入这个参数,对应从左开始第一个位置,对号入座,这个我们已经学习过了。第二个参数前面有个 星号(*),这就表示后面可能要传入的参数数量,是不确定的。可能是3个、5个,很多个,也可能是 0 个。
有心的朋友一定想到了,这种参数数量不确定的情况,特别适用于传一个 列表(list)或 元组(tuple) 啊。把想要传递的参数都放在一个 列表(list)/元组(tuple) 里,然后在调用函数时,加个 星号(*),这不就一下传过去了么?而且 列表(list)/元组(tuple) 都是自带索引编号的,正好就是 位置参数 一样,对号入座了。
即然都有 位置参数 了,那肯定要用上 关键字参数啊。对了,还有一种写法就是在要传入的参数前加 两个星号(**),这样就表示把参数作为 字典(dict) 传入,因为 字典(dict) 就是 键-值(key-value) 的形式,正好就附合 关键字参数 的特点。示例如下:
# -*- coding: UTF-8 -*-
def printinfo(x, **y): # <-- 这里的参数 y 前面有2个**号
"打印任何传入的参数"
print("输出: ")
print(x)
print(y)
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, a=60, b=50 )
2
3
4
5
6
7
8
9
10
11
说到这里,函数的 形式参数 貌似有好多种啊,好复杂,头晕头晕。稍稍小结一下,我们刚刚提到了:
- 位置参数(必备参数)
- 关键字参数
- 特殊参数(命名关键字参数)
- 默认参数
- 可变数量参数(不定长参数)
我又想劝退了。
其实搞那么多花样干嘛?请用好 位置参数 和 关键字参数就好了,再说直白点就是按次序编号,对号入座;以及 按 参数的名称对号入座。正好也对应了 列表(list)/元组(tuple) 以及 字典(dict) 的 键=值 对。
所以,对于任意函数,最神奇的是通过类似
func(*args, **kw)
的形式调用它,无论它的参数是如何定义的。你可以理解为 *args 就是一个 元组(tuple),对应 位置参数,**kw 就是一个 字典(dict),对应 关键字参数。这样就不用关心参数的数量了。
TIP
再次谢谢你,少搞花样
虽然函数的形式参数组合多达 5 种,你玩好前面 2 种就够够的了,最好能给每个参数写上一个默认值,又清晰又明了,还不容易出错!!
啥?你是大神,就是要炫技,好吧,你随意。
# 4.4、 Lambda 表达式
前面说了关于 函数 的一些基础的概念,确实都够复杂的了。后面还有 高阶函数、返回函数、匿名函数、装饰器、偏函数......打住打往,脑仁疼。说多了,真的要劝退了。我们来看一个简单的 lambda
lambda 叫作匿名函数。所谓匿名,就是说不用 def 语句这样标准的形式定义一个函数,简化写书的格式。所以它的书写格式如下:
lambda [arg1 [,arg2,.....argn]]:expression
很明显,没有用 def 这个关键字,并且也没有 函数名称,直接就写参数列表,而且多个参数之间就用 逗号(,)分隔,并没有用圆括号包括起来。参数写完了就直接写个 冒号(:)表示参数部分结束,后面接着就是 函数体,也就是要进行的处理和运算表达式。然后就没有然后了,没了。来看个例子吧:
# -*- coding: UTF-8 -*-
sum = lambda x, y: x + y
print ("相加求和 : ", sum( 10, 20 ))
print ("相加求和 : ", sum( 20, 20 ))
2
3
4
5
6
第三行 给变量 sum 赋值时,就用到了匿名函数。它就像一个 表达式。可以这样理解, lambda 就是关键字,接着就是一个形式参数列表,参数列表的末尾以 冒号(:)结束,接着就是要运算的表达式。本例中就是相加求和。
第四行 到 第五行 注意在打印输出 sum 的值的时候,我们发现,sum 明明是个变量,但看上去像个函数了。因为 sum 后面居然可以带上圆括号(),并且还可以像调用函数一样,传入参数。调用了 2 次,每次传入的参数不一样,得到的结果就不一样。这就是 lambda 妙处所在了。
如果函数只是临时一用,而且需要处理的运算逻辑也很简单,就可以用上 lambda 这个匿名函数了。就好比电影里面的群众演员,他们的戏份很少,就是衬托主演,跑跑龙套,他们的名字嘛......你懂的,不会出现在演员表里。下一次用不用他还另一说呢。
并且再往后的学习过程中,我们会接触到有关 高阶函数、返回函数、闭包、装饰器、偏函数等概念,就更有用处了。(我感觉被打脑壳)
好吧,先说简单的。lambda 既然这么简单,当然它的功能也是很有限的,需要注意以下几点:
- 讲真 lambda 只能算是一个表达式,函数体比 def 要简单很多。
- lambda 的主体只能是一个表达式,而不是一个代码块。所以只能表达实现有限逻辑运算。
- lambda 函数拥有自己的命名空间,只能访问自己参数列表中的参数。除此之外它都看不见,无法访问,包括全局参数。
- lambda 函数不等同于 C 或 C++ 中的内联函数,后者的目的是调用小函数时不占用堆栈内存从而增加运行效率。
# 本篇小节
终于小节了,再不小节的话,头都要炸了,因为本篇的内容着实不少!但也正因为如此,完成了本篇的内容,可以说 Python 语言已经上手了,就算自己一时还写不出比较大的、复杂的程序,但至少看别人写的程序源码,应该能理解的七七八八了,大致意思应该能看懂了。
本篇的内容还是很丰富的:
- 一开始我们就认识了很多 Python 的内置函数,先混个脸熟就行,不必深究。大约 68 个,很多吗?不多吧,何况有一些还压根用不上或用得很少,所以不要去死记硬背;
- 我们学会了自己写 自定义函数,就是:
def 函数名(参数列表):
函数体
return(返回值列表)
2
3
TIP
其中,参数列表部分,花样比较多。但重点是 位置参数 和 关键字参数 。就是传递参数时要注意 对号入座 。最好给每个参数写个默认值,自己也清楚,用起来也方便,还不容易出错。多好。
DANGER
再次强调:初学者,少玩新花样。
- Lambda 匿名函数。一个跑龙套的,名字都没有的表达式,但可以临时当 函数 用用;(这么一说感觉好委屈啊。哎,生活就是如此啊,亲————)
接下来,准备迎接 高阶函数、返回函数、闭包、装饰器、偏函数这些概念了吗?来吧————
# 第五章 数据结构
上一篇结束的时候,一下子抛出了很多有关函数的概念,就问你怕不怕?哈哈,那些都唬人的,等到讨论 函数式编程 的时候,再详细的讨论吧。必竟我们才刚刚认识了 Python 中的一些简单又基础的概念,比如:数据类型、语句和函数。但有了这些基础,基本上就可以编写出很多有用的程序了。
本篇的标题 ———— 数据结构,其实也挺唬人的。听起来好专业、好厉害的样子。所以得说人话:其实我们接下来要讨论的,就是一些关于 List(列表)、Tuple(元组)、Dictionary(字典)、Set(集合)和 循环结合起来的花样玩法,没什么神秘的。
# 5.1、 切片
这个之前不是学过吗?讲 字符串 的时候,我们就知道了,不就是从一个大 字符串 中,取出一部分,或一个字符嘛。对,没错。切片 就是这个意思,说专业一点就是,基于 自带索引编号 的数据,就可以从中按次序位置来截取一个片段。
简单复习一下:
# -*- coding: UTF-8 -*-
x = "abcdefg" # 这是一个字符串
y = [1,3,5,7,9,11] # 这是一个列表(list)
z = (3.14159,1.333,99.99,1024) # 这是一个元组
print(x[0:4])
print(y[-6:-2])
print(z[:3])
2
3
4
5
6
7
8
9
请你自己写出上例的运行结果吧?什么忘了?......那祝你生活愉快吧,一切都好。
那除了 切片,还有没有别的玩法?当然有了,因为人的想法是很多的,需求也是各式各样的,对应的操作当然也花样繁多啊。请看下面的例子:
# -*- coding: UTF-8 -*-
fruits = ['桔子', '苹果', '梨', '香蕉', '猕猴桃', '苹果', '香蕉']
print("列表fruits中 苹果 出现的次数:",fruits.count('苹果'))
print("列表fruits中 橘子 出现的次数:",fruits.count('橘子'))
print("列表fruits中 香蕉 的索引编号是几号?:",fruits.index('香蕉'))
print("列表fruits中 香蕉 的索引编号是几号?从 4 号开始往后数:",fruits.index('香蕉',4))
fruits.reverse() #把列表 fruits 给我反转
print("看看反转之后的列表 ",fruits)
fruits.append('葡萄') # 在列表 fruits 中加一个葡萄
print("在列表 fruits 中加一个 葡萄 看看",fruits)
fruits.sort() # 把列表 fruits 排个序(按字母)
print("fruits 排序后(按字母)",fruits)
print("从列表 fruits 中取出最末尾的那个元素 ",fruits.pop())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
上例基本用脚都看得懂吧?还是要简单说明一下, fruits 明明是个列表,为啥后面可以写个 英文句点(.)?然后紧接着好像写的是个函数呢,还可以传参数,越看越像 Python 内置函数?!
没错,这些就是 Python 自带的,可以运用在 列表(list) 上的函数(也称 方法)。请看下表:
| 编号 | 方法 | 描述 |
|---|---|---|
| 01 | list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| 02 | list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| 03 | list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x)。 |
| 04 | list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| 05 | list.pop([i]) | 从列表的指定位置移除元素,并将其返回。这个参数 i 是可选的,如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。 |
| 06 | list.clear() | 移除列表中的所有项,等于del a[:]。 |
| 07 | list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| 08 | list.count(x) | 返回 x 在列表中出现的次数。 |
| 09 | list.sort() | 对列表中的元素进行排序。 |
| 10 | list.reverse() | 反转排列表中的元素。 |
| 11 | list.copy() | 返回列表的浅复制,等于a[:]。 |
是不是秒懂了?需要提醒的是: insert、remove、sort 等方法只修改 列表(list),没有返回值 ———— 返回的默认值为 None。你可以理解它们就是一个 语句, 执行指令。
还有,不是所有数据都可以排序或比较。例如,[None, 'hello', 10] 就不可排序,因为整数不能与字符串对比,而 None 不能与其他类型对比。有些类型根本就没有定义顺序关系,例如复数比大小,3+4j < 5+7j 这种比大小的运算操作就是无效的。
那么认识了这些 列表(list) 自带的方法之后,我们就可以介绍两个在计算机语言中最常见的数据结构了 ———— 堆栈 和 队列
堆栈:就像一个只有一扇大门的仓库。搬一个箱子从大门进去,放入仓库,当然是要往最里面存放,不能放在靠近大门的地方啊,因为会挡着路啊。后面还有箱子要存放进来嘛。同时,如果要取出一个箱子的时候,就会发现,最先存进仓库的箱子在最深的地方,最后存进仓库的箱子就在靠近门口的位置。所以,在 堆栈 中先存进去的东西,可能最后才能取出来;而最后存进去的东西,必须得先取出来,为里面的箱子让路嘛。这个特点叫作:“先进后出”。所以,在计算机的世界里,堆栈就是一种“先进后出”的存储数据的数据结构。
队列:就像有前后2个门的仓库。一个箱子从前门进入仓库,可以从后门搬出仓库。如果有很多箱子,就一个个顺序从前门进入,从后门出去,像排队一样,这样就是“先进先出”了。在计算机的世界里,队列就是一种“先进先出”的存储数据的数据结构。
这两种保存数据的方式,在计算机的世界中是经常会用到。那么在 Python 中,我们用 列表(List)就可以轻松实现了,请看下例:
# -*- coding: UTF-8 -*-
stack = [3, 4, 5] # 赋值一个 列表,其中包括3个元素
stack.append(6) # 用 列表的 append 方法,存入一个数据到其中
stack.append(7) # 用 列表的 append 方法,又存入一个数据到其中
print(stack)
a = stack.pop() # 用 列表的 pop 方法,取出一个数据,请问取出的是?
print("刚刚取出的数据是: ",a)
print("堆栈中还剩余的数据: ",stack) # 用 列表中还存有哪些数据?
b = stack.pop() # 再用 列表的 pop 方法,取出一个数据,请问取出的是?
print("第二次取出的数据是: ",b)
print("堆栈中还剩余的数据: ",stack) # 用 列表中还存有哪些数据?
c = stack.pop() # 再用 列表的 pop 方法,取出一个数据,请问取出的是?
print("第三次取出的数据是: ",c)
print("现在堆栈中还剩余的数据是: ",stack)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
请自己写出上例程序的运行结果吧。这样就应该可以理解用 列表(List) 来实现 堆栈 的过程了。那么如何实现 队列 呢?动脑想一想?
队列就是一个门进、一个门出嘛。上例中我们用 append 是从 列表(List) 的末尾,也就是最右边存入数据。取出的时候用的是 pop 方法,也是从最右边取出。那就给 pop 传一个参数 0 嘛,0 就表示从索引编号 0 的位置取数据,也就是从最左边取出啊。来看示例:
# -*- coding: UTF-8 -*-
stack = [3, 4, 5] # 赋值一个 列表,其中包括3个元素
stack.append(6) # 用 列表的 append 方法,存入一个数据到其中
stack.append(7) # 用 列表的 append 方法,又存入一个数据到其中
print(stack)
a = stack.pop(0) # 用 列表的 pop 方法,有个参数 0,请问取出的是?
print("刚刚取出的数据是从 0 位置取出的,取出来的是: ",a)
b = stack.pop(0) # 用 列表的 pop 方法,注意参数 0 ,请问取出的是?
print("再从 0 位置取出一个数据,取出来的是: ",b)
print("最后这个列表中还有什么啊?: ",stack)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
活学活用,用 列表(List) 就实现了 堆栈 和 队列 这样的数据结构。存取数据的方式,应该都明白了吧?
更多的列表玩法,请在实际工作中,多多练习吧。争取烂熟于胸,得心应手。
# 5.2、 迭代
前面我们已经学过了 for 循环。同时,我们现在应该已经很熟悉 Python 中的数据类型了,如 字符串、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典)这些了。
Python 中的 for 循环 是 “从一个序列数据中,一次取出一个元素,一直取到最后一个元素,只到没有元素可取了为止”。这样来完成循环的。这个逐一访问每个元素的操作,我们称为遍历,或 迭代。
Python 中的 for 循环和其它计算机语言中的 for 循环 不太一样。其它计算机语言中的 for 循环,通常都有一个 循环变量 ,然后通过这个循环变量来计数,当循环达到一定的次数时,就中止循环。
我们来看一个例子:
# -*- coding: UTF-8 -*-
a = "abcdefg"
for x in a:
print(x)
2
3
4
5
6
7
如果换成 C 语言或别的计算机语言,可能是这样:
int main()
{
char a[] = {'a','b','c','d','e','f','g'};
int i = 0;
for (i = 0; i<7 ;i++)
{
print(a[i]);
}
}
2
3
4
5
6
7
8
9
10
通过上例,是不是 Python 语言看上去简单多了?哈哈。我们再看一个遍历列表(List)的例子:
# -*- coding: UTF-8 -*-
a = [2,4,16,32,64,128,256,512,1024,'abc',3.1415926,(1,2,3)]
#这是一个列表,其中的元素类型还挺丰富的
for x in a:
print(x)
2
3
4
5
6
7
元组(tuple) 和 列表(list) 是一样一样的,就不单独举例了。我们再来看看一个字典的 遍历/迭代 操作:
# -*- coding: UTF-8 -*-
a = {'a': 1, 'b': 2, 'c': 3}
for x in a:
print(x)
for y in a.values():
print(y)
for x,y in a.items():
print(x,y)
2
3
4
5
6
7
8
9
10
11
12
第五行 是第一个 for 循环,用来遍历 a字典。每次从 a 中取出一个元素。默认情况下,取出来的是字典中的 键(key),所以打印输出结果是什么?请你自己写出来吧?
第八行 是第二个 for 循环,同样是用来遍历 a字典,但这次我们取的是 值(values)。打印输出结果是什么?请你自己来试试。
第十一行 是第三个 for 循环,也是用来遍历 a字典,但这次我们同时取 键(key) 值(values)。打印输出结果是什么?需要强调的是,在这个 for 循环中,同时引用了两个变量,这在 Python 中是很常见的。
小结一下:任何 可迭代对象 都可以用 for 循环,包括我们自定义的数据类型,只要符合迭代条件,就可以使用 for 循环来逐一 遍历 其中的元素,这就是 迭代。
# 5.3、 列表推导式(列表生成式)
前面我们已经认识了 迭代 和 列表(List)的诸多内置方法。接下来,我们就要认识 列表推导式(有时也称 列表生成式)。英文 List Comprehensions,是 Python 内置的非常简单却强大的功能,或者说是 列表(List) 的又一花式玩法。
是否还记得在学习循环的时候,我们就用到了一个例子,想要一个包含[1, 2, 3, 4, 5, 6, 7, 8, 9, 10......98,99,100]的列表,当时我们用到了 range(1, 101)。这个 range()函数就生成了一个 从 1 到 100 的列表。可以说它就是一个 列表推导式。
但需求总是花样倍出的嘛,1 到 100 这个列表太简单了,没意思。我要一个列表,其中包含的是 [1,4,9,16,25,36,49,64,81,100],对就是从 1 到 10 的每个数的2次方,来一个。
既然我们会用 循环 了,这事儿难不到我们,起手就来:
# -*- coding: UTF-8 -*-
L = []
for x in range(1, 11):
L.append(x * x)
print(L)
2
3
4
5
6
是不是很厉害。
但你这个太繁琐,不优雅,不符合 Python 的风格。
(信不信我的38码的拖鞋拍在你24寸的脸上?)
所以,在 Python 中,用 列表推导式 则可以用一行语句代替循环生成上面所需要的列表:
# -*- coding: UTF-8 -*-
L = [x * x for x in range(1, 11)]
print(L)
2
3
4
5
第三行 就是一个典型的 列表推导式(List Comprehensions),它在一对 方括号([])中,x*x 是生成元素的表达式,这个必须放在前面。然后是一个 for 循环。
当然这个太简单了,用脚都能理解了。加个小花样,比如加上 if 语句:
# -*- coding: UTF-8 -*-
L = [x * x for x in range(1, 11) if x%2 == 0]
print(L)
2
3
4
5
for 循环加上 if 条件判断,这样就筛选出仅偶数的平方。
再加点难度,这都小学生题目,循环嵌套敢不敢?
# -*- coding: UTF-8 -*-
L = [m+n for m in 'ABC' for n in 'XYZ']
print(L)
2
3
4
5
请自己动手来看看这段代码会打印输出什么结果吧?
回顾一下前面的例子,列表推导式(List Comprehensions),肯定是在一对 方括号([]) 中的,因为它最终是一个 列表(List) 嘛;方括号中最开始写的是一个 表达式,就是告诉电脑,计算元素的公式或依据,前面的例子中,x*x 和 m+n 就是 表达式。当然这个 表达式 还可以更复杂点,比如本身就是一个 列表推导式。这就是 列表推导式 的嵌套。例如:
# -*- coding: UTF-8 -*-
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
L = [[row[i] for row in matrix] for i in range(4)]
print(L)
2
3
4
5
6
7
8
9
10
11
有本事就手动写出这个程序的运行结果吧。
好了,打住打住。新人还是老实点哈,又开始浪得没边了,浪出天际了。代码可以简洁,但思路必须清晰。还循环嵌套, 列表推导式嵌套,你咋不上天呢?实际应用中,二层的循环嵌套就很少了,三层及以上更罕见,有那必要,写个函数调用,岂不是既清晰又简单多了?实际应用中,最好用内置函数替代复杂的流程语句。比如上例中,zip() 函数更好用。
实际运用中 列表推导式 来获取个当前目录的文件列表,就比较实用:
# -*- coding: UTF-8 -*-
import os # 导入 os 模块,我们马上就要学习了
l = [d for d in os.listdir('.')] # os.listdir可以列出文件和目录
print("当前路径下的文件和文件夹列表",l)
2
3
4
5
6
7
再看一个比较实用的例子,把一个 列表 中的所有字符,转换为小写字符:dir
# -*- coding: UTF-8 -*-
L = ['Hello', 'World', 'IBM', 'Apple']
print([s.lower() for s in L])
2
3
4
5
看上去,越来越像 函数 了,是吧?但这确实只是 列表推导式(List Comprehensions),它只是用来生成一个列表。
需要注意的是在 列表推导式 如何用 if ... else 语句。列表生成式 肯定是在一对 方括号([]) 中,开头写的是列表中每个元素的 生成条件,或者说是 计算公式,表达这个元素是根据什么产生的。紧接着是 for 循环,表达一个接一个的计算出这些 元素。后面用上 if 是为了进一步筛选出符合条件的 元素,所以这个写在 for 循环 后面的 if 语句是不带 else 的。
例如,以下代码正常输出偶数:
[x for x in range(1, 11) if x % 2 == 0]
[2, 4, 6, 8, 10]
2
但是,我们不能在最后的if加上else:
[x for x in range(1, 11) if x % 2 == 0 else 0]
^
SyntaxError: invalid syntax
2
3
记住,在 列表推导式(List Comprehensions) 中,for 前面的部分是一个 表达式,它必须表达的是 元素 计算的公式,必须有一个结果。紧接着的 for 循环是表达重复计算前面那个表达式,把结果一个接一个的计算出来,放在列表中,后面如果用上 if 是为了进一步筛选出符合条件的 元素。
# 5.4、 生成器
上一节,我们学会了通过 列表推导式(List Comprehensions)直接创建一个 列表。但是,受到内存限制,列表容量肯定是有限的。试想创建一个包含100万个元素的列表,你的电脑不死机也够呛。这不仅占用很大的存储空间,而且很可能只会用到前面一小部分元素,那后面绝大多数元素占用的空间都是浪费。
所以,在 Python 中,如果列表中的元素可以按照某种算法推算出来,需要用的时候再用循环去推算出后续的元素。这样就不必一开始就创建完整的 列表(List),从而节省大量的空间。这种一边循环一边计算元素的操作机制,称为生成器(generator) 列表,以下简称 生成器。
创建一个 生成器(generator) 有很多种方法。先来个最简单的,只要把一个 列表推导式(List Comprehensions)的 方括号([]) 改成圆括号(),就创建了一个 生成器(generator),来看个例子:
# -*- coding: UTF-8 -*-
L = [x * x for x in range(10)]
Print(L)
# 输出显示 [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
g = (x * x for x in range(10))
Print(g)
# 输出显示 <generator object <genexpr> at 0x1022ef630>
2
3
4
5
6
7
8
9
第三行 是我们在上一节学习过的 列表推导式(List Comprehensions),这个不再啰嗦了。
第七行 就是把 列表推导式的方括号([ ]),换成了圆括号,这就是一个 生成器(generator)。如果打印输出这个 生成器 就会看到,这是一个对象的地址,而不会输出元素。
那么问题来了,怎么打印输出 生成器(generator) 这个 列表 中元素呢? 生成器会自动创建 __iter__() 和 __next__() 方法。(关于 iter(),马上下一节就会讨论了)请看下面的例子:
# -*- coding: UTF-8 -*-
g = (x for x in range(10))
print(next(g))
print(next(g))
print(next(g))
2
3
4
5
6
上例中,就是用 next() 函数,每次从 生成器(generator) 中取一个元素,因为 生成器 保存的是算法,而不是全部的元素。因此,每次调用 next(g) 时,就计算出下一个元素的值,然后打印输出,直到计算到最后一个元素,发现没有了,就会返回 StopIteration 错误消息,表示 生成器 里面已经没有元素了。
当然,上面这种不断调用 next(g) 实在是太蠢了,通常的方法是使用 for 循环啊,我们不是学过 迭代 吗?
# -*- coding: UTF-8 -*-
g = (x * x for x in range(10))
for n in g:
print(n)
2
3
4
5
所以,当我们要访问一个 生成器(generator) 中的元素时,几乎不会用 next() 函数,而是通过 for 循环来 迭代 它,并且不需要关心 是否计算到了最后一个元素,遇到 StopIteration 的错误。
到此,我们知道了,从一个 列表推导式(List Comprehensions) 创建 一个 生成器(generator) 的方法,简单的把 方括号 换成 圆括号 就完事儿了。其它的啥啥都不变。
接下来,我们来看另一个 创建 生成器(generator) 的方法,从一个 函数 来创建,我们还会认识 yield 语句。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,之后的任意一个数都是由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
来试试用 Python 写个函数:
# -*- coding: UTF-8 -*-
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
fib(6)
2
3
4
5
6
7
8
9
10
11
这个例子中应该没有什么难理解的语句吧?调用函数 fib(6) 的运行结果就是打印输出了一串数字,从 1 到 6 的 斐波拉契数列。
1
1
2
3
5
8
2
3
4
5
6
上面的函数 和 生成器(generator) 只有一步之遥。我们把 函数fib 变成 生成器(generator),只需要把 print(b) 语句 改成 yield b 就可以了,如下例所示:
# -*- coding: UTF-8 -*-
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
2
3
4
5
6
7
8
9
值得注意的就是 第六行 yield 是第一次认识的 语句。简单说,如果一个函数中包含这个语句,那么这就不是一个函数了,这就是一个 生成器(generator)。这一点请牢记!
函数是从上到下,顺序执行每一条语句的,直到执行到最后一条指令,或遇到 return才结束。
而带有 yield 语句的 生成器,是遇到yield就返回,并且记下这个位置,下次再调用的时候就会从这里开始,继续执行后面的指令。 yield语句就像一个 断点,执行到这里,停下、保存,下次再来的时候,继续从这里开始。
这也算是 Python 语言中的一个特性吧。自定义函数 和 生成器(generator) 还真的很容易弄混。关键字就是 yield 。
同样的,只要是 生成器(generator),我们都是使用 for 循环来 迭代 的。上例中的 fib() 从函数变成 生成器了,因此就不能像调用 函数 那样来使用了,而是用 for 循环来 遍历/迭代 其中的元素:
# -*- coding: UTF-8 -*-
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
for n in fib(6):
print(n)
2
3
4
5
6
7
8
9
10
11
12
在此之前,我们就提到过,访问一个 生成器(generator) 中的元素时,几乎永远不会用 next() 函数,而是通过 for 循环来 迭代 它,并且我们还不需要关心是否计算到了最后一个元素,会不会遇到 StopIteration 的错误。那么问题来了,我就是想看到 StopIteration 这个提示消息,让我知道已经到了 生成器 的结尾了,该怎么办?(不得不说,你的脑子确实是个闭环,牛!)
可以用 while 循环嘛,接上例:
# -*- coding: UTF-8 -*-
# 接上例
g = fib(6)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
2
3
4
5
6
7
8
9
10
11
第五行 是一个 while 循环语句,表示从这里开始进入循环,后面的条件直接是一个 True ,这就是一个死循环啊。意即循环的出口,必须得用一个 break 才行;
第六行 try是一个 “错误和异常” 语句,用来捕捉程序代码中的错误、异常情况,这个后面我们还会详细讨论,这里表示:正常情况下执行下面的语句;
第七行 到 第八行 这就是 迭代 嘛 ,而且用的是 next(),这个我们都认识了,就是一次取一个元素,然后打输出;
第九行 except 语句是和前面的 try 语句配使用的 异常处理 语句,try 表示正常情况下执行的语句,那 except 表达的就是:除非(非正常)的情况下,就执行下面的语句;后面的 StopIteration 表示 生成器 中没有更多的值了,意即遇到了 生成器 中最后一个元素了,as 是一个关键字,表示定义异常实例,后面的 e 就是这个实例的名称。关于 “错误和异常” ,后面真的需要详细讨论,先别捉急哈。
第十行 打印输出:生成器返回的最后一个元素是: e.value
记住,生成器(generator) 其实就是一个 列表(List),其中的元素是有 自带索引编号 的。
# 5.5、 迭代器
认识了前面的 生成器(generator) 之后,自然就要认识 迭代器(Iterators) 了。在创建 生成器 的时候,就提到过,每一个 生成器 都会自动创建 __iter__() 和 __next__() 方法。
其中的 __iter__() 就表示这是一个 迭代器(Iterators)。意即所有的 生成器(generator) 肯定同时也是一个 迭代器(Iterators)。
因为它自带 __next__() 这就可以让我们用 next()函数 来取出下一个元素的值,直到最后遇到 StopIteration 错误消息,表示没有下一个元素了。
也可以理解为 迭代器(Iterators) 就是一个自带了 __iter__() 和 __next__() 方法的 列表(List)。换句话说就是 普通的 列表(List) 因为不带 __iter__() 和 __next__() 方法,因此就不是 迭代器(Iterators)。如何把一个 普通的 列表(List) 转换成 迭代器 呢?简单,就是用 iter() 函数就可以了。请看下例 :
# -*- coding: UTF-8 -*-
L = [1,2,3,4]
print(next(L))
# 因为 L 是一个普通的 列表(List),不带 `__iter__()` 和 `__next__()` 方法 ,因此用 next() 时会出错。
L = iter(L)
# L 经过 iter() 转换后,变成了一个 迭代器,就可以用 next() 访问了
print(iter(L))
print(next(L))
print(next(L))
2
3
4
5
6
7
8
9
10
11
这里必须小节一下了,内容挺多的,但本篇还没完。其实从这一篇开始,我们一直在讨论的是 列表(List)的花式玩法:
- 首先我们复习了一下 切片。关键点就是 自带索引编号;
- 然后认识了 列表(List) 自带的一些内置函数(方法)。注意其中没有
__iter__()和__next__()哟; - 用 列表(List) 自带的函数(方法) appand() 和 pop(),我们实现了简单的数据结构 堆栈 和 队列,也就是 先进后出 和 先进先出;
- 然后我们认识了 迭代,就是 遍历 一个列表中的全部元素嘛。
- 接着我们学习了 列表推导式(列表生成式),就是一种创建列表的办法,之前用过 range()函数,但那个太简单了,用 列表推导式(列表生成式) 来创建 列表(List)更厉害一些,有点 函数 的味道。但它的结果仍然是一个包含有限数量元素的 列表(List);
- 为了节约空间,我们用到了 生成器(generator),它更像一个 对象,其实也还是一个列表(List),它的特点在于,每次用 next() 取元素的时候,才计算下一个元素。而不是一开始就把所有的元素都准备好。创建 生成器也很简单:一种是把 列表推导式的方括号([]),换成圆括号;另一种是在一个函数中,添加一个
yield语句。记住:生成器(generator),仍然是一个 列表(List),只不过访问的时候常用 next() 或 for 循环来 遍历/迭代。 - 认识 迭代器。生成器(generator) 同时也是一个 迭代器(Iterators)。说直白点:就是只要带有
__iter__()和__next__()方法的列表,就是 迭代器,就可以用 next() 或 for 循环来 遍历/迭代。普通的 列表(List)想转换成 迭代器,用 iter()函数转换一下 就好了。
以上说来说去,就是各种花式玩转 列表(List) 的操作,内容确实不少。
# 5.6、 del 语句
本篇开始以来,我们就在不断的玩 列表(List),从最开始最简单的用 自带的索引编号 玩 切片,然后用自带的内置函数(方法)操作列表,后来还玩到了 列表推导式、生成器,都可以把一个 列表 玩成无穷大了。总是增加元素,肯定不对啊,好歹也应该有个 删除 的操作嘛, del 语句就是删除元素的,请看下面的例子:
# -*- coding: UTF-8 -*-
a = [-1, 1, 66.25, 333, 333, 1234.5]
del a[0]
print("删除了索引编号为 0 的元素,结果为: ",a)
# 输出结果为 [1, 66.25, 333, 333, 1234.5]
del a[2:4]
print("删除 从索引编号2开始,到编号4为止的元素,结果为: ",a)
# 输出结果为 [1, 66.25, 1234.5]
del a[:]
print("删除全部元素: ",a)
# 输出结果为 []
del a
print("把 a 这个变量都删了!会输出什么?",a)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这个例子应该用脚都看懂了吧?关于 del 就先说这么多吧,以后再讨论更多的用法。
# 5.7、 元组
终于提到 元组(Tuple) 了。前面讨论了那么多 列表(List)的事儿,相信你一定还记得,在 Python 中,字符串(String)、列表(List)和 元组(Tuple),几乎具有一个一致的特性,那就是它们都是 自带索引编号 的,也就是 有序 的。元组(Tuple) 说白了就是一个 不可修改其中元素值的 列表(List)。
在实际运用中,元组(Tuple)通常用来存储 一些不同类型的元素,比如 函数 的形式参数列表;而 列表(List)通常用来存储 相同类型的元素。(啥?你非要用 列表(List)保存不同类型的元素,就这么任性!行行行,没毛病。你开心就好呗,爱咋咋的。)
除了 不可修改 这一点之外。元组(Tuple) 在书写的时候,是可以省略 圆括号 的,比如:
# -*- coding: UTF-8 -*-
a = 12345, 54321, 'hello!'
print("a 是一个元组,初始化的时候没有写 圆括号: ",a)
b = (3.14159, 1.27,"带上圆括号")
print("写上圆括号的 元组: ",b)
2
3
4
5
6
7
WARNING
我谢谢你老实点把 圆括号 写上!不然打手心!!!
比较特殊的 元组(Tuple) 是 空元组 和 只包含 1 个元素的元组。
如果想要创建一个空元组,就必须要写一对空圆括号; 如果想要创建只包括一个元素的元组,书写时需要在唯一的元素后面,添加一个逗号(,)。
丑陋,但是有效。例如:
# -*- coding: UTF-8 -*-
empty = () # 这是一个 空元组
singleton = 'hello', # <-- 注意结尾处有个 逗号
print("空元组的长度:",len(empty))
print("只有一个元素的元组的长度: ",len(singleton))
print("打印输出只包含一个元素的元组:",singleton) # 注意输出时有没有 逗号 ,
2
3
4
5
6
7
8
9
10
11
请自已写出这个程序的运行结果吧?关于 元组(Tuple) 就先聊到这儿吧。
WARNING
再次提醒,你好好的写 圆括号,少玩花样,把自己给玩晕了,划不着。
# 5.8、 集合
该复习 集合 的概念了,在数学中,集合 也是指一种数据结构。在 Python 中,集合是由不重复元素组成的无序容器。最常见的基本用法就是检测是否有重复的元素。同时,关于集合的数学运算,比如合并集合、取交集、取差集、对称差分等也是支持的。
创建 集合 用一对 花括号 包含住元素即可 或 调用 set() 函数。
注意,创建一个 空集合 只能用 set(),不能用 {}!,{} 创建的是空字典。
下面是一些简单的示例:
# -*- coding: UTF-8 -*-
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
# 注意其中有 重复 的元素哦。
print(basket) # 打印输出的结果,会发现 重复 的元素只保留了一个。
# {'orange', 'banana', 'pear', 'apple'}
print( 'orange' in basket ) # 可以用 成员运算符 快速的确认 集合 中是否包含 指定的元素
# 打印输出的结果 True
print( 'crabgrass' in basket )
# 打印输出的结果 False
# 下面的例子展示的是,关于两个单词中唯一字母的集合运算
a = set('abracadabra')
b = set('alacazam')
print (a) # 打印输出的结果会发现,单词中只保留了一个 a 字母
# {'a', 'r', 'b', 'c', 'd'}
print (a - b) # 求差集,即 集合相减
# {'r', 'd', 'b'}
print ( a | b) # 求合集,即 集合相加
# {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
print ( a & b) # 求交集,即 集合中都有的元素
# {'a', 'c'}
print ( a ^ b) # 求差分,即 没有同时出现在 a b 中元素
# {'r', 'd', 'b', 'm', 'z', 'l'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
上例很简单吧?啥?看不懂?那......劝退警报响起————
与 列表推导式 类似,集合也支持推导式:
# -*- coding: UTF-8 -*-
a = {x for x in 'abracadabra' if x not in 'abc'}
print (a)
2
3
4
# 5.9、 字典
讨论了集合,必然就要提到字典 (dict)啰。
在第二篇 数据类型 和 运算符 中,我们就认识了字典 (dict) ,它是一种常用的 Python 內置数据类型。在其它计算机语言中,可能把 字典 称为 联合内存 或 联合数组 或 map。
列表(List) 和 字典(dict) 最明显的区别在于:
- 列表自带2套整数编号索引, 要么从左往右 0,1,2,3,4,5..... 要么从右往左 -1,-2,-3,-4,-5.....这些数字是有序的,不可更改。
- 字典以 关键字 为索引的,而 关键字 通常是用的 字符串 或 数字,当然也可以是其它 不可变 类型的数据。注意:不可变 是必须的,否则就会出错。
TIP
新手玩字典(dict)的时候,关键就用 字符串 或 数字就足够了。少玩新花样,把自己整晕。
可以把字典(dict)理解为 键-值(key-value) 的集合,但 字典中 的 键(key) 必须是唯一的。
创建一个空字典,就直接写一对 花括号{} 就可以了。
另一种初始化字典的方式是,在 花括号 中输入用 逗号(,) 分隔的 键-值(key-value) 对,这也是字典的输出方式。
字典(dict)的主要用途是通过 键(key) 来存储、提取 值(value)。可以把字典(dict)想象成一个有两栏(列)的表格,左边一栏是 键(key) ,右边一栏就 值(value)。
用前面我们刚刚学到的 del 语句可以直接删除字典(dict)中的 键-值(key-value) 对。
如果给字典(dict)中一个已存在的 键(key) 赋值,则该 键(key) 对应的原来的值(value)会被新值取代。
如果你对一个已包含内容的 字典(dict) 赋值 空大花括号,那等同于清空一个 字典!例如:
# -*- coding: UTF-8 -*-
tel = {'jack': 4098, 'sape': 4139} # 声明了一个 字典
tel = {}
print (tel)
# 会发现 输出为一对 空大花括号,原有的内容都没了
2
3
4
5
6
7
8
如果访问一个字典(dict)中不存在的 键(key) 则会报错。
如果对一个字典(dict) 执行 list(d) 操作,则会返回该 字典(dict) 中所有 键(key) 的列表,按插入次序排列的,意即是无序的。如果需要排序,请使用 sorted(d)。
如果想检查 字典(dict) 里是否存在某个 键(key),可以使用 成员运算符 in 和 not in。这可是 Python 语言中的一大特色哦。
说了这么多,不如来看例子:
# -*- coding: UTF-8 -*-
tel = {'jack': 4098, 'sape': 4139} # 声明了一个 字典
tel['guido'] = 4127 # 给字典中添加了一个 键-值(key-value) 对
print (tel) # 打印输出看看结果
# {'jack': 4098, 'sape': 4139, 'guido': 4127}
print (tel['jack']) # 打印输出指定一个 键 的值
# 4098
del tel['sape'] # 删除一个 键
tel['irv'] = 4127
print(tel)
# {'jack': 4098, 'guido': 4127, 'irv': 4127}
print(list(tel)) # 打印输出 字典 tel 中的所有的 键(key)
# ['jack', 'guido', 'irv']
print (sorted(tel)) # 字典 tel 按 键(key) 序之后 打印输出
# ['guido', 'irv', 'jack']
print('guido' in tel) # 检查下 guido 是不是在 字典(dict) 中
# True
print ('jack' not in tel) # 检查下 guido 是不是在 字典(dict) 中
# False
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
dict()函数 可以用来直接创建一个字典: 如果 键(key) 名称是比较简单的字符串时,直接用 关键字参数 来传递 键-值(key-value) 对 更便捷:
# -*- coding: UTF-8 -*-
d = dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
print(d)
e = dict(sape=4139, guido=4127, jack=4098) # 这就是 函数的 关键字参数 嘛。
# {'sape': 4139, 'guido': 4127, 'jack': 4098}
2
3
4
5
6
7
字典也有推导式,可以用任意键值表达式创建字典:
# -*- coding: UTF-8 -*-
e = {x: x**2 for x in (2, 4, 6)}
print (e)
# {2: 4, 4: 16, 6: 36}
2
3
4
5
# 5.10、 循环的技巧
好了,本篇到这里,我们把前面学习过的 列表(List)、元组(Tuple)、集合(Set)和字典(Dict)又捋了一遍。其中特别把 列表(List) 都玩出花儿来了:又是内置方法;又是 列表推导式(列表生成式);还有 生成器(generator), 迭代器(Iterators) 什么的。其实元组(Tuple)、集合(Set)和字典(Dict)也有自带的内置函数(方法)啊,也支持 推导式 啊。这个过程,我们多次看到了 for 循环的身影。简单说,这些数据类型的内置函数和 for 循环结合起来,可以有多种玩法、实现多种算法。我们来看几个例子吧:
比如,enumerate() 函数 和 for 循环结合起来用在一个 列表(List) 上,可以同时获取元素的 索引编号 和 对应的值:
# -*- coding: UTF-8 -*-
l = ['赵', '钱', '孙','李']
for i, v in enumerate(l):
print(i, v)
''' 输出结果
0 赵
1 钱
2 孙
2 李
'''
2
3
4
5
6
7
8
9
10
11
12
哎,上例怎么越看越像一个 字典(Dict)?没错,说明你已经有点 融汇贯通 的意思了。字典(Dict) 中的例子,函数就是 items() :这个我们在学习 for 循环 和 迭代的时候都见过的嘛。
# -*- coding: UTF-8 -*-
h = {'东': '青龙', '西': '白虎','北': '朱雀', '南': '玄武'}
for k, v in h.items():
print(k, v)
''' 输出结果
东 青龙
西 白虎
北 朱雀
南 玄武
'''
2
3
4
5
6
7
8
9
10
11
12
上面这2例太简单了,加点难度的来,整一个小学三年级往上的!
有2个列表、让它们包括的元素逐一对应匹配:
# -*- coding: UTF-8 -*-
fn = ['赵','钱', '孙', '李','周', '吴', '郑', '王']
sn = ['大', '二', '三', '四','五', '六', '七', '麻子']
for f, s in zip(fn,sn):
print("你贵姓? {0}, 名字是 {1}。 ".format(f,s))
''' 输出结果
你贵姓? 赵, 名字是 大。
你贵姓? 钱, 名字是 二。
你贵姓? 孙, 名字是 三。
你贵姓? 李, 名字是 四。
你贵姓? 周, 名字是 五。
你贵姓? 吴, 名字是 六。
你贵姓? 郑, 名字是 七。
你贵姓? 王, 名字是 麻子。
'''
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
就这?就这?小学三年级以上的有没有?
好吧,我们来看看经常会用到的 排序 的例子
# -*- coding: UTF-8 -*-
basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
for i in sorted(basket):
print(i)
2
3
4
5
6
上例是把列表 basket 中的元素按字母排序的例子。
然后,发现其中有重复的元素 apple , orange,我们不要这样,我们想要一个元素只在列表中出现一次,我们用什么啊?
# -*- coding: UTF-8 -*-
basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
for f in sorted(set(basket)):
print(f)
2
3
4
5
6
对了,用 集合(Set) 就解决了,因为 集合中是不允许有重复的元素的。
如果我们想 反方向 排个序呢?就需要用到 reversed() 函数:
# -*- coding: UTF-8 -*-
for i in reversed(range(1, 10, 2)):
print(i)
# 请自已写出运行结果吧
2
3
4
5
6
(你是不是秀逗了?要你整点有难度的,咋还越来越智障了呢?直接上初中级别的来一个!)
需要注意的是,我们在花式玩 列表(List) 时,一般来说,把结果放到一个新建的 列表 中,是安全又明智的作法:
# -*- coding: UTF-8 -*-
import math
raw_data = [56.2, float('NaN'), 51.7, 55.3, 52.5, float('NaN'), 47.8]
filtered_data = []
for value in raw_data:
if not math.isnan(value):
filtered_data.append(value)
print(filtered_data)
2
3
4
5
6
7
8
9
10
11
怎么样?满足了吧?这个例子够初中级别了吧?请自行逐行解释这个例子中的每一条指令,它们表达了什么意思?并写出运行结果。
# 5.11、 深入理解真和假
讨论了 for 循环,顺带也得复习一下 while 和 if 吧。其实就要说明白一个事儿,这些 条件控制语句 后面,不只限于使用 比较(关系)运算符 进行比较,其实也可以使用任意运算符。因为在计算机的世界里,0 表示 false(假) ,而所有的 非0 都表示 true(真)。并不是只有 1 表示 真!所以,只要是 运算符 都会有一个结果,如果为 0 ,那么 while 和 if 就认定为 false(假),如果为 非0 ,那么 while 和 if 就认定为 true(真)。比如: 1-1=0 这就是 假, 1+2=3 这是非0, 这就是 真。
比较运算符 in 和 not in 校验序列里是否存在某个值。
运算符 is 和 is not 比较两个对象是否为同一个对象。
所有比较运算符的优先级都一样,且低于数值运算符。
比较操作支持链式操作。例如:
a < b == c
表示 比较 a 是否小于 b,并且 b 是否等于 c。
比较操作可以用布尔运算符 and 和 or 组合,并且,比较操作(或其他布尔运算)的结果都可以用 not 取反。
这些操作符的优先级低于比较操作符;
not 的优先级最高,
or 的优先级最低,
因此,
A and not B or C
# 等价于
(A and (not B)) or C
2
3
4
5
与其他运算符操作一样,此处也可以用 圆括号 来表达想要的组合。
布尔运算符 and 和 or 也称为 短路 运算符:其参数从左至右解析,一旦可以确定结果,解析就会停止。
例如,如果 A 和 C 为真,B 为假,那么 A and B and C 不会解析 C。用作普通值而不是布尔值时,短路操作符返回的值通常是最后一个变量。
还可以把比较操作或逻辑表达式的结果赋值给变量,例如:
# -*- coding: UTF-8 -*-
string1, string2, string3 = '', 'Trondheim', 'Hammer Dance'
non_null = string1 or string2 or string3
print(non_null)
# 打印输出的结果 Trondheim
2
3
4
5
6
7
8
9
注意,Python 与 C 不同,在表达式内部赋值必须显式使用 海象运算符 :=。
这避免了 C 程序中常见的问题:要在表达式中写 == 时,却写成了 = 。
# 5.12、 列表的比较
现在脑洞了来了,既然在计算机的世界里,0 表示 false(假) ,而所有的 非0 都表示 true(真),并且只要是一个表达式,肯定都会有一个结果值,这个值要么是 0,要么是 非0。所以结论就是:所有的表达式其实都 非真即假
那么,在 Python 中的特有的数据类型 列表(List),有没有真假呢?可不可以比较呢?答案是:当然有!请看下面的例子:
# -*- coding: UTF-8 -*-
print((1, 2, 3) < (1, 2, 4)) # 比较 2个 元组(Tuple)
print([1, 2, 3] < [1, 2, 4]) # 比较 2个 列表(List)
print('ABC' < 'C' < 'Pascal' < 'Python') # 比较 字符串
print((1, 2, 3, 4) < (1, 2, 4)) # 比较 2个 元组(Tuple) ,前一个元组拥有多一个元素
print((1, 2) < (1, 2, -1)) # 比较 2个 元组(Tuple) ,前一个元组拥有少一个元素
print((1, 2, 3) == (1.0, 2.0, 3.0)) # 比较 2个 元组(Tuple) 是否相等
print((1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)) # 比较 2个 元组(Tuple) ,元组有嵌套。
2
3
4
5
6
7
8
9
(这个够给力吧,请自己逐一写出每一行所表达的意思和运行的结果吧。)
# 本篇小节
一、我们复习了一下 列表(List) 的 切片 ,其实就是按 自带的索引编号 来取数据。列表(List)当然不止 切片 这一种玩法,增、删、改、查这种基本操作必须有啊,还有排序、反向排序、统计数量、复制一份、获取索引编号等等,都已经有相应的内置函数(方法)可以直接调用,多么方便;
二、我们学习了2个最常见、也是最常用的 数据结构 ———— 堆栈 和 队列,并且用对应的 列表(List) 方法实现了它们的特性,也就是一个 先进后出,一个是 先进先出;
三、我们又复习了下 迭代 的概念。就是用循环来遍历一个序列数据中的全部元素。这里就体现了 Python 语言中 for 循环的特别之处,与其它语言中的 for 循环不同, Python 中的 for ... in 语句就是用来 迭代 的,表达的就是从List(列表)、Tuple(元组)、Dictionary(字典)、Set(集合)这种类型的数据中一次取一个元素,直到取完为止;
四、我们从之前用过的 range() 函数开始,学习了 列表推导式(列表生成式)。简单说就是我们想要一个 列表(List),但不想一个一个的写元素,那多累啊。如果这些元素可以用一个计算公式算出来,那我们就只用写出这个 公式的表达式 就好了。这就是 列表推导式(列表生成式 List Comprehensions) ,首先是一个 表达式,它必须表达的是 元素 的计算公式,必须有一个结果。紧接着的是 for 循环,表达重复计算前面那个表达式,把结果一个接一个的计算出来,放在列表中,后面还可以用上 if 是为了进一步筛选出符合条件的 元素;同理,Dictionary(字典)和 Set(集合)也是可以用 推导式 来生呈的。
五、理解了 列表推导式,那么 生成器 就呼之欲出了。
简单的把 列表的方括号([])改成圆括号(),就创建了一个 生成器(generator)。列表推导式 保存的是结果,生成器 保存的是计算方式。所以想要访问 生成器 中的元素,就需要用到 next() 函数,或 for 循环。实际运用中,其实就是用 for 循环,很少用 next() 函数。
创建 生成器(generator) 的另一个方法,就是在一个 函数 中,加上 yield 语句。换句话说,如果一个函数中包含这个 yield 语句,那么这就不是一个函数了,这就是一个 生成器(generator)。自定义函数 和 生成器(generator) 还真的很容易弄混。关键字就是 yield 。所以 生成器(generator)可以用更复杂的 函数 来描述需要生呈的元素,而前面讨论的 推导式(Comprehensions) 只能用简单的表达式 + for 循环,最多再加上 if来生呈元素,并且元素的数量还必须是有限的。
六、认识了前面的 生成器(generator) 之后,自然就要认识 迭代器(Iterators) 了。所有的 生成器(generator) 肯定同时也是一个 迭代器(Iterators)。换句话说就是:迭代器(Iterators) 就是一个自带了 __iter__() 和 __next__() 方法的 列表(List)
说来说去,就是各种花式玩转 列表(List) 的操作,内容确实不少。
七、用 del 语句删除元素。
八、复习 元组(Tuple)。需要记住的是:在实际运用中,元组(Tuple)通常用来存储 一些不同类型的元素,比如函数的形式参数列表;而 列表(List)通常用来存储 相同类型的元素,就像 数组一样。我谢谢你好好写 元组(Tuple)的 圆括号。
九、复习 集合(Set)。实际运用中,最常见的就是检测是否有重复的元素。集合也支持 推导式(Comprehensions)
十、复习了 集合(Set) 那必须也要复习 字典(Dict) 啊。可以把 字典 理解为 键-值(key-value) 对 的集合,但字典的键必须是唯一的。字典的主要用途就是通过 关键字(Key) 存储、提取 值(value)。用 del 可以删除键值对。字典也支持推导式(Comprehensions)
十一、把 Python 中的数据类型又重新复习了一遍之后,再结合循环,讨论了一下各种花式玩法,还学习了几个新函数:比如 items() 、 enumerate() 、 zip() 、 reversed() 、 sorted()、 set() 等等;
十二、 复习一下 while if in 和 not in 的用法;
十三、 序列 也可以用 关系运算符来比较;意即,列表可以和列表比较,集合可以和集合比较;注意:不同的数据类型的值 进行比较时,有时会触发 TypeError 异常。
(虽然是复习,但不得不说这一章的内容可真够多的!厉害了!)
# 第六章 初识模块
在前面的例子,细心的朋友一定已经注意到了 import 这个关键字。当时只是简单的提了一句,这是用来导入 模块(Module) 的, 然后就略过了。说到 模块(Module) ,用人话解释就是:有很多前辈,已经写好了一些代码(以前被称为 子程序 )用来解决一些开发需求。为了方便后学的同学们,就把这些代码都打包保存起来,并且还公开免费的让任何人都可以运用(你还是要学会用啊)。这些前辈们打包好的代码文件,就是模块,有的地方也叫 标准库(Library)。随着学习的深入,了解掌握的模块越多,应对实际开发需求就越来越得心应手,这就是模块的好处。
Python 之所以能火起来,一时名声雀起,风光无两,就是因为它提供了很多好用的模块,并且像“语言胶水”一样,可以灵活的把以前学习不同计算机语言的人都“粘”在一起,协同工作。
理论那么多,不如实践走一圈,先来一个前面见过一次的,关于操作系统获取文件夹名称的例子,还有印象吗?
# 6.1、 导入模块 import
# -*- coding: UTF-8 -*-
import os # 导入 os 模块
for d in os.listdir('.'): # os.listdir可以列出文件和目录
print("当前路径下的文件和文件夹",d)
2
3
4
5
第一行 不解释了,因为解释了很多次了;
第二行 就是今天要介绍的导入模块的语句 import,Python 本身就内置了很多非常有用的模块,需要用的时候,提前用这个语句导入就好。有个前提是你要在操作系统中用 pip 指令先安装好啊,否则导入时会报错,没有找到你要的模块啊。
TIP
这就是为什么,在一开始的时候,要从安装 AnaConda 环境开始的原因了,因为有了这个环境之后,常用的模块都已经安装好了,随取随用,方便。
什么,你就喜欢硬核的?偏要手动一个一个的用 pip 指令安装,好吧。大神请随意,开心就好。
在 import后面,就是具体的要导入的模块的名称了。本例中是要获取有关 文件夹 的名称,这和 操作系统 有关,因此导入的模块是 os 。
执行了这个导入语句之后,我们就等同于有了一个变量 os 指向该模块,现在用 os 这个变量,就可以访问 os 模块的所有功能了。
第四行 for 循环和 成员运算符 in 也不啰嗦了,应该都很熟悉了。 os.listdir() 这个就是获取 文件/目录的方法,因为我们已经导入了,所以就可以直接调用这个 方法(函数) 了。圆括号中可以传入一个参数,用来表示指定的路径,'.' 表示当前的路径。
WARNING
注意,如果有 中文 文件夹/文件名 可能需要先用转码函数 unicode(),才能正常显示中文字符。
第五行 就是打印输出结果了。
看,使用模块(Module)就是如此简单。想要了解 Python 中倒底有多少内置的模块,可以参考 Python 标准库。相信我,那是非常庞大的内容,涉及范围十分广泛。在这个标准库以外还存在成千上万并且不断增加的其它组件,被称为第三方包(Package)。(打住打住,脑仁又开始疼了。)
如果你安装的是单纯的 Python 3.11 版,那么内置的 模块(Module)大约有如下这些:
array、atexit、audioop、binascii、builtins、cmath、errno、faulthandler、gc、itertools、marshal、math、mmap、msvcrt、nt、sys、time、winreg、xxsubtype、zlib;
同时,也安装好了如下一些 标准库(Lib),算了,就不拿出来吓唬人了。(可以用 help("modules") 来查看已安装的全部模块。)
我们初学者先掌握基本的、常用的模块就好。以后实际工作中要用到了,具体根据需求、再去查阅相应的模块(Module)、包(Package)就可以了。没有必要死记硬背、贪多嚼不烂,还把自己搞得很混乱。
关于 import 语句的语法,具体如下:
import module1[, module2[,... moduleN]
可见后面的参数是可以写多个 模块名称 的,也就是说一个 import 语句可以一次导入多个模块的,模块名称之间用 逗号(,) 分隔就可以了。一个模块只会被导入一次,所以不用担心名称写重复了,模块也不会被一遍又一遍导入的。(当然,你最好写的时候仔细点,为啥会把一个模块名称写 2 遍以上呢?脑子卡壳?还是掉线了?)
import 语句一定要写在整个程序代码的开头部分的,一般情况都是在顶部,紧接着
# -*- coding: UTF-8 -*-
第二行就开始书写导入模块的语句。(我就没见过程序中间写个 import 语句的)
当 Python 的解释器遇到 import 语句时,就去查找对应的模块名称,找到了就读取其中的内容,包括其中的函数(方法)啊、属性(变量)啊、类啊等等......然后就可以随时调用了。如果在当前的路径中没找着,就会去找 环境变量 中包含的路径文件夹中去找,现在知道 环境变量 的作用了吧?如果还没找着,那就要报错了。
那么问题来了,我怎么知道一个模块(Module)里都包含了哪些函数(方法)、属性(变量)和类呢,简单说,这个模块里倒底有啥?我咋知道啊?
方法一:去查手册;(费劲,累,不想动)
方法二:用 dir() 函数来获取,然后打印输出;(早说不结了?)
# -*- coding: UTF-8 -*-
import os # 导入 os 模块
import math # 导入 math 模块
print("模块 os 中包含的内容",dir(os))
print("模块 math 中包含的内容",dir(math))
2
3
4
5
6
7
8
打印输出的内容也很多吧,哈哈。还是得查手册啊,好歹可以参考 dir()的输出再去查手册了嘛。
那么下一个问题又来了,我只想导入这个模块中的一部分,不想全部导入,我就是这么有洁癖,我是处女座。好吧,满足你,用下面的语句就可以了:
# -*- coding: UTF-8 -*-
from os import listdir # 导入 os 模块中的 listdir 这个方法(函数)
print("当前路径下的文件和文件夹",listdir()) # 调用时直接用函数名就好了,都不用前缀 os.
2
3
4
from ...... import ...... 语句 就是用来从一个模块(Module)中导入指定的 函数(方法)、属性(变量)和类的指令,可能你是想节约空间、提高效率,精准的把控自己的程序。当然,你也可以写
from os import *
这样写会把 模块os中的全部函数(方法)、属性(变量)和类都导入进来,并且直接调用。然而不推荐使用这种方式。最好还是用以下的方式
import os
需要的时候用前缀 os. 来调用,更安全、更简单、更清晰。
好了,既然聊到这里了,我们需要进一步学习一些基本概念(专业术语):命名空间、作用域、闭包
# 6.2、 命名空间
A namespace is a mapping from names to objects.Most namespaces are currently implemented as Python dictionaries。 命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 python 字典来实现的。———— 这是 官方文档原文(简直不是人话)
人话版:就是在写程序时,给一个变量(或者 对象)定义一个名称(起一个名字),这个名称的 可见(有效)范围,被称为 命名空间。例如:你写一个文件,保存时写的文件名是 ABC,我写一个文件,保存时写的文件名也用 ABC。那么我的文件就会把你的文件给替换了。如果你这个文件保存在C盘,我的文件保存在D盘。那么你的文件ABC的 命名空间 就是C盘,因为C盘是你的文件ABC的 可见(有效)范围。我的文件ABC的 命名空间 就是D盘。这样我们的文件都可以保存下来了,并且名称是一样的,都是 ABC。只是一个在C盘,一个在D盘。命名空间不一样,也就是可见(有效)范围不一样。
在计算机程序语言的世界里,一般有三种命名空间:
内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。(也被称为 保留字)
全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的形式参数和函数内定义的变量。(声明 类 时,定义的变量也是局部名称)
命名空间查找顺序:
当我们要使用一个变量(或者 对象)时,python 的查找顺序为:
- 第一步,先在 局部的命名空间中 去找
- 第二步,在 全局命名空间 中去找
- 第三步,在内置命名空间 中去找
如果经历了以上三步都没找着,就会发出一个错误消息:
NameError: name 'xxx' is not defined。
意即: xxx 这个名称未定义,没找着。
命名空间的生命周期:
命名空间的生命周期取决于对象的 作用域 ,如果对象执行完成,则该命名空间的生命周期就结束。
因此,我们无法从 外部命名空间 访问 内部命名空间 的对象。我们再来看一个例子:
# -*- coding: UTF-8 -*-
a = 5 # 这是一个全局变量,它在程序中任何地方都可以看到
def some_func():
b = 6 # 这是一个局部变量,它只在 函数 some_func 中可以看到
print("全局变量a = ",a) # 这里输出 a,是可以看到的。
def some_inner_func():
c = 7 # 这是一个 嵌套在函数内的 更深的一个局部变,它只在 some_inner_func 函数中可见
print("全局变量a = ",a) # 这里输出 a,还是可以看到的。
print("函数中的变量b = ",b) # 这里输出 b,还是可以看到的。
return c
y = some_inner_func()
print("从函数中返回出来的c = ",y) # 只有调用了一次 some_inner_func,并且把 c 的值传递给 y。直接输出 c 是会出错的。因为看不到 c
return b
print("全局变量a =",a) # 这里输出 a,是可以看到的。
x = some_func() # 调用了一次 some_func 函数,并且把 b 的值 传递回来给 x。因为在这里是看不到 b 的,更看不到 c
print("从函数中返回出来的b =",x)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
上例中,可以看到,在整个程序运行期间,变量 a 是随时都可以看到的,随时可以打印输出。而 变量 b ,必须是在调用函数 some_func() 时,才可以看到,才可以打印输出的。如果 函数 some_func() 没有被调用,那么 b 是不存在的,也就是不能打印输出的。 变量 c 更是如此,因为 c 在 嵌入函数 some_inner_func() 中,意即,c 在更深的位置。因此,如果没有调用函数 some_inner_func() 的时候,变量 c 是不存在的,更不可能打印输出了。
现在,我们来稍稍修改一下上例中的代码,让函数some_func()返回时,不是返回一个变量,而是返回一个函数。
# -*- coding: UTF-8 -*-
a = 5 # 这是一个全局变量,它在这个程序中任何地方都可以看到
def some_func():
b = 6 # 这是一个局部变量,它只在 函数 some_func 中可以看到
print("全局变量a = ",a) # 这里输出 a,是可以看到的。
def some_inner_func():
c = 7 # 这是一个 嵌套在函数内的 更深的一个局部变量,它只在 some_inner_func 函数中可见
print("全局变量a = ",a) # 这里输出 a,还是可以看到的。
print("这是函数外部的b = ",b) # 这里输出 b,还是可以看到的。
return c
y = some_inner_func()
print("从函数中返回出来的c = ",y) # 只有调用了一次 some_inner_func,并且把 c 的值传递给 y。直接输出 c 是会出错的。因为看不到 c
return some_inner_func #注意这里,我们返回的是一个 函数。
print("全局变量a =",a) # 这里输出 a,是可以看到的。
x = some_func() # 调用了一次 some_func 函数,返回的是 函数 some_inner_func()。
# 这样就把 整个函数 some_inner_func(),包括 函数中的 c 也传递了出来。
# 这种把整个 函数 返回 给 调用者,这就是 闭包。
print("从最里面的函数中返回出来的c =",x()) # 这时,我们打印输出 c 的值 ,就可以看到了。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 6.3、 作用域
A scope is a textual region of a Python program where a namespace is directly accessible. "Directly accessible" here means that an unqualified reference to a name attempts to find the name in the namespace. 作用域是python程序的一个文本区域,在这个区域中可以直接访问命名空间。这里的 “直接访问”是指对一个名称的无条件引用会试图在命名空间中找到这个名称。—— (同样的是非人话版)
人话版:python 在找一个 对象 时,肯定是用 名称 来找的,无论是一个变量,还是一个函数、类,肯定得有一个名称。就好比 点名,然后在场的人就答:“到!”。那点名的时候用的《花名册》,就是 作用域,《花名册》上写的全是人名,作用域 就是一个包含 对象名称 的《花名册》本子(文本区域),里面全是对应那些 对象 名称的字符文本。
一个班有一个《班级花名册》,全年级有一个《年级花名册》,全校有一个《全校学生花名册》。这时你就明白了,你的名字,出现在哪本《花名册》上,就决定了 点名 的时候能不能找到你。如果在 《班级花名册》中点不到你,当然要去《年级花名册》上去找,如果还没找到就得去找《全校学生花名册》。
python 中一共有四种作用域(《花名册》本子):
L(Local):最内层,包含局部变量,比如一个 函数/方法 内部的《花名册》本子。
E(Enclosing):这一本《花名册》比较特殊,其中包含的是 非局部(non-local) 同时 也非全局(non-global)的变量名称。比如两个嵌套函数,一个函数A 里面又包含了一个函数 B ,那么对于 B 中的局部变量的名称来说, A 中的作用域就为 nonlocal。翻译一下就是,1班临时把2班的《花名册》借用下,这样在1班点名时,也可以暂时找到2班的同学。(把2班的《花名册》暂时借给1班用用,这样的操作,就叫 闭包。)
G(Global):当前程序最外层的一个《花名册》,比如 全局变量。
B(Built-in): 包含了内建的 变量/关键字 等。
查找顺序(点名的顺序): L –> E –> G –> B。

现在,理解了 命名空间、作用域。那么 全局变量、局部变量。应该很容易就理解了。 你上学的时候,被分到了1班,你就是 1班 的局部变量了。你成为年级长,你就是全年级的全局变量了。
# 6.4、 闭包(Closure)
理解了 作用域,看懂了 命名空间 中例子,我们才能开始讨论 闭包 这个概念。很多人说 闭包 这个概念很难解释,貌似很啰嗦的样子。其实要说简单也很简单,就是一句话:当一个 内嵌函数(就是 自定义函数里面又自定义了函数) 想要引用其外部 作用域 的变量时,我们就会用到一个闭包。
TIP
我来表达一下:闭包 就是在一个 自定义函数中,用 return 语句返回一个 内嵌的自定义函数。如此一来就把 内嵌函数 整个都 传递到了外部,这就像打了一个包,全传出去了,这就是 闭包。
把几个前提条件捋明白了就清楚了:
- 必须有内嵌函数;意即 自定义函数 里面又有 自定义函数 的情况;
- 内嵌函数 想要引用 外部函数中的变量;
- 外部函数的返回语句,返回的是 内嵌函数;
毕竟 闭包(Closure) 是函数式编程的重要的语法结构,面向函数编程的程序猿应该很容易理解。还是来看前面的例子:(幸好这是在线文档,不是印在纸上的,不然重复前面一模一样的例子,真是浪费纸张啊,有罪。)
# -*- coding: UTF-8 -*-
a = 5 # 这是一个全局变量,它在这个程序中任何地方都可以看到
def first_func(): # 这是一个自定义函数
b = 6 # 这是 first_func 函数中的 局部变量,它在函数 first_func 中可以看到
def inner_func(): # 这是一个 内嵌函数
c = 7 # 这是一个 内嵌函数 中的局部变量,它只在 inner_func 函数中可见
return c # 这是返回的是一个具体的变量 c 的值
return inner_func #注意这里,first_func()返回的是 内嵌函数 inner_func。
print("全局变量a =",a) # 这里输出 a,是可以看到的。
x = first_func() # 调用了一次 first_func 函数,返回的是 函数 inner_func()。
# 这样就把 整个函数 inner_func(),包括 函数中的 c 也传递了出来。
# 这种把整个 函数 返回 给 调用者,这就是 闭包。
print("从最里面的函数中返回出来的c =",x()) # 这时,我们打印输出 c 的值 ,就可以看到了。
# x() 其实等同于 first_func()() 值得注意的是,函数必须带上 圆括号 才表示 运行一次。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在这个例子中,其实已经看到了 返回函数 这种操作,这又涉及到一些新的概念(专业术语),比如:高阶函数、装饰器、偏函数 等等。(好了,打住,脑仁深处隐约传来一丝刺痛,我必须要保护我的大脑。)那么我们以后复习函数的时候再详细讨论。
那么留一个作业,请问用 print(b) 能正确打印输出变量 b 的值吗?
TIP
实践写程序时,用得多的,还是 局部变量。自己要用的变量,在自己的函数中,尽可能的不和外部去打混,否则搅得自己头晕,何苦呢。
需要用全局变量的时候,就得小心使用。记得赋初值、记得哪里修改过,还要记得还原……总之,小心谨慎,不然一不小心就弄混了。
至于 闭包 也好,修饰指令临时改变一个变量的作用域也好,更像是在炫技、实用功能不大。
# 6.1、 包
现在我们已经知道了模块,那么为了更好地管理多个模块源文件,Python 提供了 包 的概念。
从物理上看,包就是一个文件夹,在该文件夹下包含了一个名为 __init__.py 文件,该文件夹可用于包含多个模块源文件;
从逻辑上看,包的本质依然是模块。
包 的作用是包含多个模块,但包的本质依然是模块,因此 包 也可以包含 包。典型地,当我们为 Python 安装了 numpy 模块之后,可以在 Python 安装目录的 Lib\site-packages 目录下找到一个 numpy 文件夹,它就是前面安装的 numpy 模块(其实是一个包)。
既然 包 其实就是一个 文件夹,其中就是有一个名称为 __init__.py 的文件,那么我们也可以自己创建一个 包
- 创建一个文件夹,该文件夹的名字就是 包 的名称;
- 在该文件夹内添加一个
__init__.py文件即可;
说干就干。先新建一个 first_package 文件夹,然后在该文件夹中添加一个 __init__.py文件,该文件内容如下:
'''
这是学习包的第一个示例
'''
print('this is first_package')
2
3
4
这个源文件非常简单吧
然后,我们就在程序中也导入,调用这个 包 啰。
# -*- coding: UTF-8 -*-
# 导入 first_package 包(模块)
import first_package
print('==========')
print(first_package.__doc__)
print(type(first_package))
print(first_package)
2
3
4
5
6
7
8
9
动手试试运行一下这个例子,看看结果吧。
再次强调,包的本质就是模块,因此导入包和导入模块的语法完全相同。
与模块类似的是,包被导入之后,会在包目录下生成一个 __pycache__ 文件夹,并在该文件夹内为包生成一个 __init__.cpython-36.pyc 文件。
导入 包 就相当于导入该 包 对应的文件夹下的 __init__.py 文件,因此我们完全可以在 _init__.py 文件中定义变量、函数、类等程序单元,但实际上往往并不会这么做。原因是 包 的主要作用是用来管理多个模块,因此 __init__.py 文件的主要作用就是导入该 包 内的其它模块。
我们初学者就先好好享受 Anaconda 为我们带来的便利吧,关于 模块、包之类的这些事情就放心交给它来代管吧。以后我们的经验和水平都达到一定的厉害程度了,再自己构架自己的包、模块的管理系统吧。(什么?你现在就要起飞,包、模块、每一个源码文件、每一行源码你都要整得清清楚楚、明明白白,不然不爽!———— 敢问大神,你为何如此牛逼?!)
# 本篇小节
导入模块其实就是把前辈们写好的一些 方法(函数)、属性(变量)、类、对象等等这些东东,引入到我们自己写的程序中来。说专业点就是 引用到我们的 命名空间 中,扩展了 作用域,这个过程中我们还了解了 闭包 的概念,说白了就是为了调用变量的时候更加方便快捷。(但也容易混乱,啥啥都堆在眼前,貌似伸手可取,其实也是缺乏整理,没有规范的表现。)所以,学习了解更多的模块、就能让我们程序写的飞起、效率更高、开发过程更快捷。如果只知道基本的语句、那确实写不出什么有用的程序。
当然,遇到具体需求时、再去查找引入相应的模块,才是明智之举。把所有的模块都装在自己的大脑里,一不切实际、二也没有必要。熟悉常用的模块、并能结合实际需求来引入调用、才是正确的编程思维。在纷扰杂乱的问题中找到最优解,才是程序员的能力体现,加油吧。
关于模块这一篇就到这里吧。
# 第七章 输入与输出(IO)
学习计算机编程,就是和电脑说话,教这台机器听懂我们的话,照我们说的去做。这个过程就是 “人机对话”。既然是对话,自然就有听(输入)和说(输出)。就目前的科技而言,我们直接说,电脑是听不懂的。所以要把我们想说的话翻译成计算机语言————也就是写成程序代码,交给电脑。电脑能理解程序代码,于是就可以按我们的要求去干活了————这就是 执行程序。执行完成了得回来报告一下啊。目前电脑也还没学会直接说出来给我们听(如果电脑都要开口说话了,那这个世界太吵了。),所以最常用的是用 print 语句输出一些文本信息,让我们用眼睛去阅读,看到电脑执行的结果。这就是最简单的输入与输出。
在计算机中,IO就是 Input/Output,也就是 输入 和 输出。举个例子:你在键盘上打字,这就是对电脑的 输入,眼睛看到屏幕上显示出来的字符,这就是电脑的 输出。当然,电脑很强大的,不仅只能用键盘输入,还有鼠标啊,硬盘上的文件啊,网络上的页面啊......另一方面,输出也不仅是字符啊,比如图片啊、动画啊、声音啊、还有保存到硬盘上的文件啊。这么说就好理解多了吧?
输入输出这个过程中,有一个重要的概念就是 Stream(流),不是你那个游戏STEAM!看清楚点。Stream(流)就好比是水管,你可以想像一下家里的进水管和排水管,输入就是进水管,输出就是排水管,数据就是水管里流动的水。所以,说到IO,就至少需要 2 根水管,用来接收和发送数据。
IO这个过程中还有一点需要注意的是速度,因为有的水管粗,有的水管细啊,水压也不一样,对吧。在计算机的世界是,速度最快的,当然是 CPU 了,它和 内存 之间的速度最快。如果程序想把100M的数据,从 CPU 输出到 内存,那估计 0.01 秒都不用,嗖一下就过去了。但 内存 到 硬盘 的速度就慢好多,同样是 100M 的数据,估计得 10秒左右,这一下速度差了 100倍。所以 CPU 不喜欢硬盘,更喜欢内存。
这种快慢速度不匹配的情况,只有两种方式解决: 一种就是快的设备等着慢的设备,CPU 就得等着 硬盘,这叫 同步IO; 另一种就是,快的设备先干点别的事儿,等慢的设备整好了,再执行下一步,这就叫 异步IO;
肉眼可见,异步效率高,充分发挥了速度不同的设备的效率,但也意味着编程过程中要考虑的事儿更多,操作更复杂。同步IO虽然慢点吧,但简单明了啊,出错的概率也小一点。所以,我们初学者,先玩好同步IO吧。
在 “第三篇 走向编程的第一步” 中,我们就用到了 input 和 print 这2个语句,展示了一个最简单的输入和输出的例子。现在这一篇中,我们来学点更高级点的 输入与输出。本篇主要介绍打印输出字符串时会用到的各种方法以及文件的读写操作,具体就是 print() , format() 和 open() , close() , read() , write() 这些函数的用法。
# 7.1、 打印输出 字符串
print() 这个函数,我们已经用得很熟了。在前面的示例中,我们几乎都要用到这个语句来打印出程序运行的结果,来检查一下是否正确————哎,这也是 debug(找错误)的方法。
print() 圆括号中的内容就是要打印输入出的内容了,绝大多数情况下都是一个字符串(string)。众所周知 Python 中是没有那么明确的数据类型的,所以说 print() 就可以打印输出任何对象,也就是圆括号里有啥就打印啥。但新手在打印输出前,把想要打印的对象转换成 字符串(string),这是一个好习惯。可以用到 str() 或 repr() 函数。
str() 适用于可打印字符串,比如中英文字符、数字等,适合人阅读。不适用打印程序源码等,比如 转义符、ASCII中不可打印的字符等。
repr() 适用于任何对象,包括 ASCII 中的所有字符,更适用于打印计算机语言的源代码,可以交给电脑执行的那种。
看几个例子就明白了:
# -*- coding: UTF-8 -*-
s = 'Hello, Runoob'
print(str(s))
print(repr(s))
print(str(1/7))
x = 10 * 3.25
y = 200 * 200
s = 'x 的值为: ' + repr(x) + ', y 的值为:' + repr(y) + '...'
print(s)
# repr() 函数可以转义字符串中的特殊字符
hello = 'hello, runoob\n'
hellos = repr(hello)
print(hellos)
# 输出结果 'hello, runoob\n'
# repr() 的参数可以是 Python 的任何对象
print(repr((x, y, ('Google', 'Runoob'))))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
在 debug 调试程序时,不需要花哨的输出,只想迅速地显示变量的值,就会经常用到 repr() 或 str()函数输出字符串。
让我们好好看看这个 print() 的本体,完整的语法是:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
看到了吧,其实这个函数是很强大的,它带有几个默认参数的。我们之前用到的时候,就是把想要打印输出的东西传给它,它就忠始的照原样打印出来了。而后面的参数,我们其实很少用到,借此机会捋捋吧。
spe ———— 表示打印输出的时候,每个元素之间用什么来间隔,默认是空格。这里你可以写个逗号(,)啊,或者是制表符(|)试试啊。
end ———— 表示打印输出完一行之后,末尾用什么字符结束。默认是'\n',表示回车符。如果把它换成别的字符,就不会有回车换行的效果了。
file ———— 表示打印输出的结果写到文件中。当然,前提是,要先用 open() 语句打开文件,并且带上写入标志 'w+'。关于文件的输入输出在本篇中我们马上就要讨论了。
flush ———— 是个 布尔值,非真即假,默认为假。意即表示打印输出的结果 是/否 立即直接写到文件中,不缓存。默认为假就是 不要立即写入,先缓存着,等文件关闭的时候再一次性写入。
看看例子就更明白了:
# -*- coding: UTF-8 -*-
print("aaa","bbb","ccc") # 默认的分隔符就是一个 空格
print("aaa","bbb","ccc",sep='@') # 分隔符用 @
print("aaa","bbb","ccc",end='这一行结束不用 回车符,不换行。') # 一行结尾时,用 end 指定的字符
print("我看看有没有换行")
2
3
4
5
6
7
8
请你自己写出例子的运行结果吧。关于文件的输入输出,请参考后面的例子。
# 7.2、 f-字符串
那么什么是 花哨 的输出呢? 如果学过 C 语言的朋友一定记得 printf() 这个函数,它一般被叫作格式化输出,就是打印字符串的时候带着各种样式,比如: 换个行啊(\n),必须占多少格啊,必须是10进制数/2进制数/16进制数啊......之类的控制格式。那么在 Python 中有没有对应的方法呢?当然有了,而且更简单了,直接在字符串前面写个 f ,大写 F 也行,就可以达到格式化输出字符串的效果了,看下面的例子:
# -*- coding: UTF-8 -*-
year = 2008
event = '申奥成功'
print(f'大事记 {year} {event}')
# 输出结果为:大事记 2008 申奥成功
2
3
4
5
6
7
第三行声明了一个变量,是个整数型;
第四行声明了一个变量,是个字符串;
第六 行用我们熟悉的 print() 打印输出了,稍有不同的是,在圆括号中的字符串前面有个字符 f ,同时在字符串中出现了花括号({}),在花括号中是变量名。
运行的结果显示,打印输出的内容为,字符串中的字符正常打印了,而花括号中的变量,就是获取了值之后才打印输出的。这就是 Python 中的 格式化字符串字面值 (简称为 f-字符串)。即:在字符串前加上前缀 f 或 F,通过带花括号的表达式({expression}),把 表达式的值 添加到字符串内。
# 7.2.1 format() 格式化输出
上一节,我们认识了 f-字符串 ,那么接下来自然就要聊一下 format() 。实际运用中 format() 几乎和 print() 一样常见。直接看例子吧:
# -*- coding: UTF-8 -*-
year = 2008
event = '申奥成功'
print(f'大事记 {year} {event}')
print('大事记 {} {}'.format(year,event))
2
3
4
5
6
7
例子中可以看到 format() 的用法。就是直接在 字符串 中写上花括号({ }),表示这个花括号的位置会填上相应的变量,然后在字符串的末尾写上一个英文句点(.),这表示引用对象的方法,这个方法就是 format(),(关于类、对象、方法、属性 在“面向对象编程”的章节里会有更详细的讨论)对象中的方法就是函数了,圆括号中的内容就是函数的参数啰,很明显,这里需要2个参数对应前面的2个花括号,中间用英文逗号(,)分隔。
当然 format() 的功能远不止如此。格式化输出的玩法可多了,但说白了就是花样玩耍字符串呗。请看下面的例子:
# -*- coding: UTF-8 -*-
# 按位置访问参数
print('{0}, {1}, {2}'.format('a', 'b', 'c'))
print('{}, {}, {}'.format('a', 'b', 'c'))
print('{2}, {1}, {0}'.format('a', 'b', 'c'))
print('{2}, {1}, {0}'.format(*'abc'))
print('{0}{1}{0}'.format('abra', 'cad'))
# 按名称访问参数
print('Coordinates: {latitude}, {longitude}'.format(latitude='37.24N', longitude='-115.81W'))
coord = {'latitude': '37.24N', 'longitude': '-115.81W'}
print('Coordinates: {latitude}, {longitude}'.format(**coord))
# 指定占位宽度,对齐文本
print('{:<30}'.format('左对齐'))
print('{:>30}'.format('右对齐'))
print('{:^30}'.format('居中对齐'))
print('{:*^30}'.format('居中对齐')) # 用 * 号填充空格
# 显示不同进位制的数值
print("十进制int: {0:d}; 十六进制hex: {0:x}; 八进制oct: {0:o}; 二进制bin: {0:b}".format(42))
# 使用逗号作为千位分隔符:
print('{:,}'.format(1234567890))
#表示为百分数:
points = 19
total = 22
print('显示百分比为Correct answers: {:.2%}'.format(points/total))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
把上例手动敲一遍代码,然后运行一下看看结果吧。
以上各种花式玩法了解就好。实际运用中,规规矩矩的按位置访问参数就好,足够用了。
# 7.2.2 手动格式化字符串
打印输出一个表格,从1到10的 平方 和 立方。这是最常用的考题:(虽然在实际运用中没用上过)
# -*- coding: UTF-8 -*-
for x in range(1, 11):
print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
# 注意上一行的 print() 用了 end 参数,表示 不换行
print(repr(x*x*x).rjust(4))
""" 运行结果如下:
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
第三行,我们用到了 for in 循环语句,用 range() 生成了一个从 1 到 10 的列表,这些我们都很熟悉了。
第四行,进入了循环体,用 print() 打印输出,repr(x)前面刚刚学习过,表示把 x 转换成一个 ASCII 字符打印输出,后面还有个 rjust(2)呢,这个函数(方法)表示,这个字符串靠右对齐,并且宽度为2个字符。后面的同理,就不重复解释了。最后的 end=' ' 是 print() 的参数,表示这一行的结尾不用回车符,而是用 空格 。
第五行,还是在循环体中,还是用 print() 打印输出,repr(x*x*x) 和 rjust(4) 就不用解释了吧?值得一提的是,打印输出这一行与上一行是在同一行中,不会换行。因为上一行的 print() 用了 end 参数。
关于 str.rjust() 方法,相信聪明如你,应该马上就想到了:既然有 右对齐,那当然也有 左对齐、居中对齐啊。没错,str.ljust() str.center() 必须有。看下例就一目了然了:
# -*- coding: UTF-8 -*-
str = "abcdefg"
print(str.ljust(10, '0'))
print(str.center(10, '0'))
print(str.rjust(10, '0'))
print(str.center(5, '0'))
"""
运行结果为:
000abcdefg
abcdefg000
0abcdefg00
abcdefg
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
例子中,第四到六行,展示了 str.rjust() str.ljust() str.center() 的用法,分别对应字符串左、中、右对齐的方式。例中的字符串长度为 7 个字符,指定的宽度为10个字符,不足的位置用 0 填充了。
值得注意的是第八行,特意将宽度指定为 5, 小于原字符串的长度。会发现什么呢?你会发现,这 3个函数,都不会截断字符串,而是原样返回,不会做任何修改。(如果想要截断字符串,请用 切片 操作)
顺带的,再多认识一个方法(函数)吧:str.zfill(),它可以在数字字符串左边填充零,并且还能识别正负号,所以如果用在数字上的时候,用它就对了。请看下面的例子:
# -*- coding: UTF-8 -*-
a ='12'
b ='-3.14'
c='3.14159265359'
print(a.zfill(5))
print(b.zfill(7))
print(c.zfill(5))
"""
'00012'
'-003.14'
'3.14159265359'
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如前面所描述的,zfill() 函数用在数字字符串上正好。可以填充0来占位,保留了正负号(+-),也不会截断数字。
# 7.2.3 字符串插值 —— %
以前学过 C 语言的同学,应该还记得用 printf() 输出字符串中,有时会包含百分号(%)。出现在字符串中的这个百分号并不是表示取模返回除法余数的意思 。它是用来格式化字符串的,表示这个位置,应该有一个元素来替换。此操作被称为 字符串插值。来看例子:
printf("%f ", 199.80); // 这是 C 语言中的例子,%f 是输出控制符,f 表示十进制浮点数
在 Python 中这种旧式的打印输出格式控制符,仍然被保留下来,但用得很少了。
# -*- coding: UTF-8 -*-
print("%f" % 199.80) # %f 仍然是有效的,f 表示十进制浮点数
2
3
常见的格式控制符如下表:
| 控制符 | 说明 |
|---|---|
| %d | 按十进制整型数据的实际长度输出。 |
| %ld | 输出长整型数据。 |
| %md | m 为指定的输出字段的宽度。如果数据的位数小于 m,则左端补以空格,若大于 m,则按实际位数输出。 |
| %u | 输出无符号整型(unsigned)。输出无符号整型时也可以用 %d,这时是将无符号转换成有符号数,然后输出。但编程的时候最好不要这么写,因为这样要进行一次转换,使 CPU 多做一次无用功。 |
| %c | 用来输出一个字符。 |
| %f | 用来输出实数,包括单精度和双精度,以小数形式输出。不指定字段宽度,由系统自动指定,整数部分全部输出,小数部分输出 6 位,超过 6 位的四舍五入。 |
| %.mf | 输出实数时小数点后保留 m 位,注意 m 前面有个点。 |
| %o | 以八进制整数形式输出,这个就用得很少了,了解一下就行了。 |
| %s | 用来输出字符串。用 %s 输出字符串同前面直接输出字符串是一样的。但是此时要先定义字符数组或字符指针存储或指向字符串,这个稍后再讲。 |
| %x(或 %X 或 %#x 或 %#X) | 以十六进制形式输出整数,这个很重要。 |
好吧,这种方式真的已经过气了,用得很少了。了解就好。
# 7.3、 读写文件
终于我们来到了文件操作的章节了。要知道,只有掌握了文件的读写操作,才能真正的保存/加载数据。之前的所有操作都是在计算机的内存里捣鼓,也就是说只要一断电,就全没了。会读写文件了,就不怕断电了,下次开机的时候,可以接着弄,效率也会大大的提高。
文件操作通常都分三步: 一、打开文件,告诉电脑是想读取还是写入; 二、把数据放在缓存中,读取就是从文件中取出放到缓存中,写入就是把数据放到缓存中,准备写入到文件; 三、关闭文件。如果是写入操作,会在关闭前一次性把缓存中的数据写入到文件中之后,再关闭;
是不是就和把大象放进冰箱里一样简单?1. 打开冰箱;2. 把大象放进去;3. 把冰箱关上; over
# 7.3.1 文件的打开和关闭
我们来看看 Python 中具体的指令。
open()
这是打开文件的语句, open 就是字面意思。它有 2 个最常用的参数:
workfile ———— 表示文件名,意即要操作的文件名称;
mode ———— 表示操作的动作,比如 读取(r)、写入(w)、追加写入(a)等;
一般情况下,我们在程序中用到的文件都是 文本文件(text mode),并且现在基本都是国际统一标准的编码方式 UTF-8,大名鼎鼎吧。偶尔会用到 二进制文件,比如图片jpg啊,或者执行文件exe啊。
我们新手小白能用好文本文件就行了,大神请飞得更高点。文件中的数据都是一行一行的文本,每一行都有一个结束符,对了就是 (\n)
有 open 自然就有 close 了,打开了一个文件之后,记得要用 f.close() 语句关闭;但在实际运用中,用得最多的方式是 with 语句,如下例:
with open('workfile') as f:
用 with 语句的好处就是会自动关闭文件,以防丢三落四的马大哈朋友,总是会忘了关闭文件。就像生活中忘了随手关灯一样。
# 7.3.2 文件的读取和写入
上一节中,我们已经学会了打开(open())和关闭 (close()) 文件。现在我们来学习读取和写入。
f.read(size) 即可读取文件中的内容,参数 size 表示一次读取多少字节的数据。如果不写这个参数,会一次性把文件中的内容全部读取出来放在内存中。想象一下,你一下要读取一个大小为100G的文件,会发生什么?!你的内存够大吗?会死机的,笨蛋!所以如果文件比较小还好,大文件你就得小心了。我们新手小白一般读点文本文件得了,你要干啥啊?读取世界百科全书吗?
多说不如多练,我们来看例子。请先准备一个简单的文本文件,比如名称为 “test.txt”,在其中随意写上几行文本,保存好。
这是个文本文件。
这是第一行;
这是第二行;
这是第三行;
这是第五行,第四行是空的。
OVER了,这是最后一行。
2
3
4
5
6
7
我们来写个程序,读取这个文本文件,打印输出读取到的内容,最后关闭这个文件。
# -*- coding: UTF-8 -*-
f = open('test.txt', 'r') # 打开一个文件, test.txt 是文件名称,标示符'r'表示读取。
print(f.read()) # 打印输出读取到的文件中的全部内容
f.close() # 关闭文件,这一步很重要!
2
3
4
5
第三行开始,我们用 open() 语句打开了文本文件 test.txt, r 表示我们想读取其中的内容 第四行,打印输出 用 read() 读取到的文件的全部内容 第五行,关闭文件。
是不是和把大象放进冰箱一样简单?
实际运用中,用得最多的是用 with 语句来写的,请看示例:
# -*- coding: UTF-8 -*-
with open('test.txt','r') as f: # 打开文件,前面用了 with 语句
print(f.read()) # 打印输出读取到的文件内容
print(f.closed) # 验证文件是否已关闭
# True 表示已成功关闭
2
3
4
5
6
7
还有一个更安全更保险的写法,确实够教授范儿了。我们也瞅一眼呗。
# -*- coding: UTF-8 -*-
try:
f = open('test', 'r')
print(f.read())
finally:
if f:
f.close()
2
3
4
5
6
7
8
用 try ... finally 这种写法,是为了防止:文件读写时一旦出错,产生了 IOError 错误消息,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,就用这种万全之策的写法。这其实 Python 中的关于 “错误和异常” 的处理方式,后面的篇章中,我们还会详细讨论。
除了 read() 还有一个语句 readline() 也是用来读取文件的。字面意思就是一次读取一行,遇到换行符(\n)了,就表示一行结束了。如果到文件结尾了,就会遇到空字符串('')。因此可以用循环遍历整个文件,请看下面的例子:
# -*- coding: UTF-8 -*-
f = open('test.txt', 'r')
line_content = f.readline()
while line_content != '':
print(line_content,end='')
line_content = f.readline()
f.close()
2
3
4
5
6
7
8
9
第三行开始,打开文件 test.txt ,标志 'r' 表示要读取这个文件;
第四行,先用 readline() 读取一行,保存到变量 line_content 中;
第五行,用 while 循环来一行一行的读取文件的内容。如果遇到文件结尾的结束符(''),就结束循环;
第六行,while 循环体中,打印输出读取到的一行内容;
第七行,while 循环体中的读取一行 readline 语句;
想一想,第六行中 print() 语句中,为什么要用 end 参数?
当然,我们也可以用 for in语句来实现这个循环,看上去更简洁明了。
# -*- coding: UTF-8 -*-
f = open('test.txt', 'r') # 打开一个文件, test.txt 是文件名称,标示符'r'表示读取。
for line in f:
print(line, end='')
f.close()
2
3
4
5
6
7
这种操作能高效利用内存,快速,代码是不是也更简单呢?
现在,你应该已经清晰的理解了,读取文件的前提是,必须先打开(open)文件,那么让我们来看看open()的完整体吧:
open(file,
mode='r',
buffering=-1,
encoding=None,
errors=None,
newline=None,
closefd=True,
opener=None
)
2
3
4
5
6
7
8
9
参数说明:
file ———— 文件名称,包含文件路径(相对或者绝对路径),必须是一个字符串;
mode———— 可选,文件打开模式。默认是 r 表示读取;
DETAILS
| 实参符号 | 说明 |
|---|---|
| 'r' | 读取模式。文件必须存在。 |
| 'r+' | 可读可写。写入的内容在文件末尾。 |
| 'rb' | 表示以二进制读方式打开。 |
| 'w' | 写入模式。会创建新文件,如果已有同名文件会被覆蓋。 |
| 'wb' | 表示以二进制写方式打开。 |
| 'a' | 追加模式,写入的新内容在文件末尾。 |
| 'a+' | 追加读写。可以读。 |
buffering———— 设置缓冲,取值为 0 ,1 或大于1的数值,
DETAILS
0表示无缓冲区,仅用于二进制文件;
1表示有缓冲区,对就文本文件;
大于1的数值即缓冲区的大小;
encoding———— 文本文件的编码方式,国际惯例使用 utf-8,只在文本模式下使用
errors———— 可选参数,指定如何处理编码或解码错误,不能在二进制模式下使用。以下为一些标准错误的处理程序:
DETAILS
'strict' :编码出错抛出异常ValueError,默认值None具有相同的效果。
'ignore' :忽略错误。请注意,此选项可能会导致数据丢失。
'replace':使用某字符进行替代模式,(例如'?')插入到存在格式错误的数据的位置。
'surrogateescape' :将表示任何不正确的字节,作为从U DC80到U DCFF范围内的Unicode私人使用区域中的代码点。当写入数据时使用surrogateescape错误处理程序时,这些专用代码点将被转回相同的字节。这对于处理未知编码中的文件很有用。
'xmlcharrefreplace':编码不支持的字符将替换为相应的XML字符引用。此选项仅当写入文件时,才有效。
'backslashreplace' : 通过反斜杠转义序列替换格式错误的数据。
'namereplace': 仅在写入时有效,用\ N {...}转义序列替换不支持的字符。
newline———— 用来控制文本模式之下,一行的结束字符。可以是None,’’,\n,\r,\r\n等
closefd———— 如果closefd是False并且给出了文件描述器而不是文件名,则当文件关闭时,基本文件描述器将保持打开。如果给定文件名,则closefd必须为True(默认值),否则将产生错误。
opener———— 用来实现自己定义打开文件方式。
接下来,我们来写入文件吧。当然就是用 write() 语句啰。看例子:
# -*- coding: UTF-8 -*-
f = open('test2.txt', 'w') # 打开一个文件, test.txt 是文件名称,标示符'w'表示写入。
f.write('我来写个Hello, world!') # 向文件中写入一个字符串
f.close() # 关闭文件,这一步很重要!
2
3
4
5
这个例子简单到用脚都可以看懂了,就不啰嗦解释了。把对象都转换成字符串,再写入到文本文件中,是一个好习惯。
但在实际运用中,用得最多的还是用 with 语句,请看示例:
# -*- coding: UTF-8 -*-
with open('test2.txt', 'w') as f: # 打开一个文件, test.txt 是文件名称,标示符'w'表示写入。
f.write('我来写个Hello, world!') # 向文件中写入一个字符串
2
3
4
5
with语句是不是看上去又简单,又保险。
WARNING
需要特别注意 调用 f.write() 进行写入文件时,如果未使用 with关键字,或未调用f.close(),即使程序正常退出,也 可能 导致数据没有完全写入磁盘。因此 关闭文件 是一件很重要的事情!!!
现在我们需要认识一下文件指针的概念了。
一个文件刚刚打开时,我们对它的操作自然的是从头开始的,这个头就是第一个位置的意思,也就是说有个文件的指针,指向文件开头的位置。接下来,假设我们用 readline() 读取了一行,那么这个文件指针现在指向了哪里呢?答案是 第二行的开头。如何验证呢?用f.tell()函数,请看例子:
# -*- coding: UTF-8 -*-
f = open('test.txt', 'r')
print("文件刚刚打开,指针的位置是: ",f.tell())
line_1 = f.readline()
print("读取了一行之后,指针的位置是: ",f.tell())
f.close()
"""
运行结果为:
文件刚刚打开,指针的位置是: 0
读取了一行之后,指针的位置是: 18
"""
2
3
4
5
6
7
8
9
10
11
12
13
这例子一看就懂吧。那么问题来了,我想控制一下这个指针,可不可以?
当然可以了,我是人,电脑是机器,得听人的话!控制文件指针位置的方法(函数)是:
seek(offset,whence)
参数说明:
offset ———— 表示偏移量,意即移动几个字符;
whence ———— 表示从哪儿开始;0表示从文件开头;1表示从当前位置开始,2表示从文件的结尾开始。
参考示例:
# -*- coding: UTF-8 -*-
f = open('test.txt', 'rb')
f.seek(0,2) # 把文件指针,移动到 文件末尾
print("文件末尾的指针位置是: ",f.tell())
f.seek(7,0) # 把文件指针,移动到 从文件开头,向右移动 7 个单位
print("f.seek(7,0)之后,指针的位置是: ",f.tell())
f.seek(2,1) # 把文件指针,移动到 从当前位置开始,向右移动 2 个单位
print("f.seek(2,1)之后,指针的位置是: ",f.tell())
f.seek(-5,2) # 把文件指针,移动到 从文件末尾开始,向左移动 5 个单位
print("f.seek(-5,2)之后,指针的位置是: ",f.tell())
f.close() # 记得关闭文件,是个好习惯。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
看了例子之后,是不是感觉到了一点列表切片的味道?对了,文件中的指针,就类似 列表(List)中的 索引编号。需要注意的是,如果想用 seek() 方法,那么在打开文件的时候,最好用 'rb' 模式打开,避免出错。
WARNING
如果打开模式只是 'r'意即 文本文件(text mode),那么 seek() 方法仅支持从文件开头移指针,请注意这一点。
关于文件操作还有其它一些方法(函数),但实际用得不多,所以本节就到这里吧。
# 7.3.3 os 和文件夹
即然用到了文件了,那必然要和 操作系统 打交道。因为文件系统都是由 操作系统 管理的嘛。导入 os 模块是常规操作:
import os
同时,你也可能见到过 os.path 这个模块,它和 os 的分工大致可以理解为:os 用于 文件或目录(文件夹)的增、删、改、查等处理,而os.path 更多的用于有关文件属性、路径信息的相关操作(主要是和 / 或 \ 相关的路径操作 )。
我们看几个简单的例子吧:
# -*- coding: UTF-8 -*-
import os
print(os.name) # 操作系统的 文件分区表类型
# 'posix' 是 Linux 或 Mac OS 的文件分区表, Windwos 的是 'nt'
# 不会吧,不会吧,都2021年了,还有人用 fat32 吗?
print(os.uname()) # 更详细的操作系统的信息,注意 Windows 没有此函数
print(os.environ) # 操作系统的环境变量
print(os.environ.get('PATH')) # 操作系统的环境变量 PATH 的值
print(os.path.abspath('.')) # 打印输出当前的绝对路径
# 列出当前目录下的所有文件夹目录的名称,只需要一行代码:
print([x for x in os.listdir('.') if os.path.isdir(x)])
# 列出所有后缀名为 .py 的文件:
print([x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py'])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 7.3.4 使用 json 保存结构化数据
到这里为止,我们已经掌握了 Python 中读写文件的基本操作、文本文件(text mode) 模式已经足以应付实际工作中大多数的情况了。
但是......
文本文件(text mode) 这种模式真的就只对 字符串 友好。如果想用文件操作读写 数字,则稍显麻烦。因为 read()方法只返回字符串,数字就需要转换一下,比如用 int()这样的函数。如果想用到列表(List)、字典(Dict)那就更复杂了,手动解析这些数据类型令人头疼,怎么破?
这就要用上 json 文件了。
JSON 文件,在互联网上几乎随处可见,全称为:JavaScript Object Notation(JavaScript 对象表示法)。是用来存储和交换文本信息的语法,类似 XML,但 JSON 比 XML 更小、更快,更易解析。
JSON 语法是 JavaScript 语法的子集。一个 json 文件看上去的特征就是:
- 数据保存的形式是 键:值 (key:value)对 // 这不就是 字典(Dict) 吗?
- 数据之间由逗号分隔 // 妥妥的就是 字典(Dict)啊
- 大括号 { } 保存对象 // 这必须是 字典(Dict)
- 中括号 [ ] 保存数组,数组可以包含多个对象 // 这不就是 列表(List)里面放 字典(Dict)吗?
例如:
{
"name" : "王小二",
"age" : 25,
"birthday" : "1990-01-01",
"school" : "蓝翔",
"major" : ["理发","挖掘机"],
"has_girlfriend":false,
"car":null,
"house":null,
"comment":"这是一个注释"
}
2
3
4
5
6
7
8
9
10
11
这是 json 数据?这明显这就是一个 字典(Dict)啊。每一个数据都是 键值对(key:value)的形式,它们都是用逗号(,)分隔。值的数据类型可以是数字(整数或浮点数)、字符串(在双引号中)、布尔(逻辑)值(true 或 false),甚至是 数组(在方括号 [ ]中,就是 列表(List)嘛 )、对象(在花括号 { }中,就是字典(Dict)嵌套嘛)。这确实就是一个典型的 json 数据。
在 Python 中,把想要保存的数据,比如列表(List)、字典(Dict)啊,转换成字符串的形式,保存为 json 数据文件,这个过程称为 serializing(序列化)。从 json 文件中读取数据字符串,然后还原(重建)为 Python 中适用的数据类型,这个过程称为 deserializing (解序化)。在 序列化 和 解序化 之间,这些字符串,就可以存储在 json 文件 或 适当的数据类型中,便于计算或传输。
TIP
JSON 格式的数据字符串通常用于现代应用程序的数据交换。程序员早已对它耳熟能详,可谓是交互操作的不二之选。
在 Python 中处理 json 文件,通常都是使用 json 模块,它主要提供了四个方法(函数):dump() 、dumps()、load() 、loads() 。
- dump()
先看例子:
# -*- coding: UTF-8 -*-
import json
json1 = {
"name" : "王小二",
"age" : 25,
"birthday" : "1990-01-01",
"school" : "蓝翔",
"major" : ["理发","挖掘机"],
"has_girlfriend":False,
"car":None,
"house":None,
"comment":"这是一个注释"
}
with open('test3.json', 'w',encoding='utf-8') as f:
json.dump(json1,f,indent=4,ensure_ascii=False) # 把 json1 写到 文件f中
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
快看看有没有一个 test3.json 的文件,其中的内容是啥?

细心的同学肯定已经发现了,json 文件中有些数据的表达式还是和 Python 中的不一样的,比如在 Python 中 False 首字母是大写,写入 json 文件中之后全是小写了 false 了;还有 None,变成了 null。(果然是细心的同学才注意到,厉害了!点赞!)
所以,在 Python 中使用 json 文件时,请注意下表中一些细节变化:
| JSON | Python | 备注 |
|---|---|---|
| object | dict | 字典(Dict)简直就是为 json 对象而设计的,绝配! 都一样用花括号 { } |
| array | list | 列表(List)配 数组,正好! 一样用 方括号 [ ] |
| string | unicode | 字符串没啥说的 |
| number (int) | int, long | 整数 |
| number(real) | float | 浮点数 |
| true | True | 注意首字母大写 |
| false | False | 注意首字母大写 |
| null | None | 意思一样,但要注意单词不一样 |
现在,让我们看看 dump() 方法的完整体吧:
json.dump(
obj,
fp,
*,
skipkeys=False,
ensure_ascii=True,
check_circular=True,
allow_nan=True,
cls=None,
indent=None,
separators=None,
default=None,
sort_keys=False,
**kw)
2
3
4
5
6
7
8
9
10
11
12
13
14
参数说明如下:
obj ———— 表示想要 序列化 并写到文件中去的的数据对象,通常是一个 字典(Dict);
fp ———— 表示要写入的文件。注意 json模块只能用 文本文件(text mode) 模式,因此在打开这个文件的时候请不要用 二进制模式('b');
skipkeys ———— 默认为 False。如果设为 True,将会跳过 字典(Dict) 中不是基本类型(str,int,float,bool,None)的 键,不会引发 TypeError(类型错误);
ensure_ascii ———— 默认值为 True,能将所有传入的非ASCII字符转义输出。如果设为 False,则这些字符将按原样输出。
check_circular ———— 默认值为 True。如果设为 False,则将跳过对容器类型的循环引用检查,循环引用将导致OverflowError。
allow_nan ———— 默认值为 True。如果设为 False,则严格遵守 JSON 规范,序列化超出范围的浮点值(nan,inf,-inf)会引发ValueError。 默认 True 表示将使用它们的 JavaScript 等效项(NaN,Infinity,-Infinity)。
indent ———— 设置缩进格式,默认值为 None,表示是最紧凑的格式。如果设为一个正整数,那么 JSON 文件会按指定的数值缩进空格;如果设为 0、负数 或 空字符串(""),则在 JSON 文件中仅插入换行符;如果设为一个字符串(例如 "\t"),则该字符串将会用于缩进的每个空格的位置。
separators ———— 去除分隔符后面的空格,默认值为 None 。如果指定,则分隔符应为(item_separator,key_separator)元组。如果缩进为None,则默认为(’,’,’:’);要获得最紧凑的JSON表示,可以指定(’,’,’:’)以消除空格。
default ———— 默认值为 None 。如果指定,则default应该是为无法以其他方式序列化的对象调用的函数。它应返回对象的 JSON 可编码版本或引发 TypeError。如果未指定,则引发TypeError。
sort_keys ———— 默认值为 False。 如果设为 True,则字典的输出将按键值排序。
- dumps()
除了不需要传文件描述符,其他的参数和 dump() 函数一样。意即,暂时不想写入到文件中,先把数据转换成 json 数据字符串格式,瞅瞅先。
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
请看下面的例子:
# -*- coding: UTF-8 -*-
import json
json1 = {
"name" : "王小二",
"age" : 25,
"birthday" : "1990-01-01",
"school" : "蓝翔",
"major" : ["理发","挖掘机"],
"has_girlfriend":False,
"car":None,
"house":None,
"comment":"这是一个注释"
}
json2 = json.dumps(json1,indent=2,ensure_ascii=False) # 把 json1 转换成 json 字符串,但不写入文件
print(json2)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- load()
前面认识了写入到文件的操作,当然也要学习下如何从文件中读取(加载)嘛。(有玩游戏的感觉了哈,S/L大法(save/load)。)说专业点就是:把 json 数据 deserializing (解序化)为 Python 中适用的数据类型。
json.load(
fp,
*,
cls=None,
object_hook=None,
parse_float=None,
parse_int=None,
parse_constant=None,
object_pairs_hook=None,
**kw
)
2
3
4
5
6
7
8
9
10
11
参数说明如下:
fp ———— 文件名称,通常是一个 JSON 文件,可以用二进制文件,解序化成为一个 Python 对象。如果不是一个有效的 JSON文档,将会引发 JSONDecodeError异常
object_hook ———— 默认值为 None。此参数是一个可选函数,用于实现自定义解码器。意即指定一个函数,负责把 解序化 之后的基本类型对象转换成自定义类型的对象。
parse_float ———— 默认值为 None。只在需要用另一种数据类型或解析器来对 JSON float字符串进行解码时,才使用此参数。
parse_int ———— 默认值为 None。只在需要用另一种数据类型或解析器来对JSON int字符串进行解码时,才使用此参数。
parse_constant ———— 默认值为 None。如果指定此参数,对-Infinity,Infinity,NaN字符串进行调用。如果遇到了无效的JSON符号,会引发异常。
就用我们在前面的例子中刚刚写入的那个 test3.json 来试试呗,这次把它加载起来。
# -*- coding: UTF-8 -*-
import json
with open('test3.json', 'r',encoding='utf-8') as f:
d = json.load(f) # 读取文件,保存到变量 d 中
print(d)
2
3
4
5
6
7
8
是不是 so easy,这简直猩猩都会。
- loads()
loads 和 load 唯一的区别是,接收的数据源不同。 loads 是从 字符串 来 deserializing (解序化),这个 s 就是 字符串(string)的意思。
其他的参数都是相同的,返回的结果类型也相同。
TIP
如果非要用 loads() 来接收文件的话,需要先用 read() 来读取一下,请见下例:
# -*- coding: UTF-8 -*-
import json
with open('test3.json', 'r',encoding='utf-8') as f:
l = f.read() # loads() 前面需要先用 read() 读取文件
d = json.loads(l) # 其实还是从 变量 中加载的数据,而不是直接从文件中加载的
print(d)
2
3
4
5
6
7
8
9
# 本篇小节
print() 语句不用说了,这个从 Hello World 都知道了;实际运用中最常见的是带上 format() 方法;至于那些花里呼哨的格式修饰,真的用得不多。但架不住遇上喜欢装X的考官,就是要秀一秀刁钻的脑回路,搬出参数 spe啊、end啊、flush啊,来考你,还有什么 f-字符串啊、%百分号字符串插值啊;还有更变态的,各种方法(函数):
str() # 转换成字符串,便于打印
repr() # 转换成源码格式的字符串,便于程序解释器阅读
str.rjust() # 字符串 右对齐
str.ljust() # 字符串 左对齐
str.center() # 字符串 居中对齐
str.zfill() # 适用于数字转换成字符串,能填充0,保留正负号
2
3
4
5
6
要你现场打印个乘法表、杨辉三角啥啥的,那就自求多福吧。
打开文件 open() 是非常重要的一个语句。尤其它的参数 打开模式(mode) 决定了之后的操作,看似繁杂,归纳一下也就是 读('r')、写('w')、追加写('a'),初学者用好 文本文件(text mode) 就好,注意编码参数 encoding,国际惯例都是 UTF-8 了。以后熟悉了再玩转二进制模式,掌握文件指针 f.seek() 吧
只要是用到了文件(文件夹),请导入import os 模块。这是常规操作。
实际运用中 json 文件那是必须的。在 Python 中就 serializing(序列化)和 deserializing (解序化)的过程。名词挺专业的、怪唬人的。操作起来其实很简单,就是先导入模块 import json,然后调用方法(函数)dump() 、load() 就OK了,就这么简单。
本章就到这里吧,记得多多练习哦。
# 第八章 错误和异常
初学编程总会出点错的,就像刚开始学写字一样,你一动笔就是书法大师啊?所以,排查错误、也就是程序员的日常Debug。如果前面你手动敲过例子中的代码,应该已经遇到过一些错误信息,比如敲错了几个字符啊,少敲了一个 冒号(:)啊,空格的数量不对啊。这些都叫作 句法错误 ,还有一种错误叫作 异常。比如写文件的时候发现磁盘满了写不进去,做除法的时候用 0 当除数(分母)。
# 8.1、 句法错误
敲代码时敲错了,这是常有的事。这个时候就体现出 IDE(集成开发环境)的强大之处了。通常都会很直观的显示出错误的位置,比如在 微软的 Visual Studio Code 中,就会用 波浪线啊、红色的字符啊,来提示你,如下图:

不同的 IDE 有不同的提示方式。甚至还有一些插件帮助我们自动修正这些句法错误。初学的朋友还是先老实手敲为妙。 句法错误是必须要修改好的,不然程序无法运行啊。电脑看不懂你写的啥啊。
# 8.2、异常
异常这种状况,IDE 可能就处理不了了,而是显示一些错误信息,有些同学一看到下图都蒙圈了。这时候就体现出懂英文的重要性了吧,因为提示消息都很清楚了。
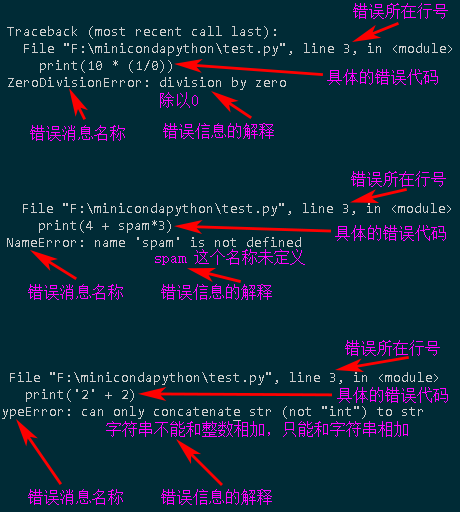
是不是后悔自己没学好英文吧?学个编程就遇上了拦路虎!(又来劝退了————哈哈哈!)
# 8.3、异常的处理(容错机制)
出现 异常 其实是很常见的,尤其是在用户交互界面中特别突出。还记得开篇中那三只猫的图片吗?用户行为真的不可预测。所以,在编程的时候,有时也要考虑到处理异常的情况,有的书上称之为:容错机制。
请看下面的例子,要求用户必须输入有效的整数,否则就要循环输入这个过程。但允许用户中断程序(使用 Control-C );注意,用户中断程序会触发 KeyboardInterrupt 异常。
# -*- coding: UTF-8 -*-
while True:
try:
x = int(input("Please enter a number请输入一个整数: "))
break
except ValueError:
print("Oops! That was no valid number. Try again...哦,错了,请再试一次")
2
3
4
5
6
7
8
对了,这里就用到了 try 语句,在前面的章节中我们也曾看到过,当时一掠而过了。现在我们来仔细看看。
第三行,是一个 while 循环,而且还是个 死循环,因为一直是 Ture;
第四行,就是 try 语句,就是字面意思,“来试试”,注意末尾以冒号(:)结束,表示它后面还有可执行的代码块;
第五行,用 input() 函数提示用户输入一个整数,然后用int()函数转换,保存到变量 x 中;
第六行,一切正常的话就执行 break 退出循环;
第七行,except是try的子语句,意即试过了 try 之后的语句之后,如果出现错误,就看这里,如果错误是 ValueError 那么就执行这后面的语句,注意末尾也是以冒号(:)结束,后面还有可执行的代码块;
第八行, 意即出现了错误之后,打印输出一行提示消息,告诉用户输错了数字,请再试一次。
是不有点 if ... else 的感觉,只不过 try ... except 专门用来处理异常错误消息的。也就是说,必须得有对应的错误消息名称,才会执行 except 后面的语句。并且 except 可以写不止一个,这样就可以对应多个错误消息名称了。比如:
try:
...
except NameError as e:
print('出现错误 NameError---->', e)
except IndexError as e:
print('出现错误 IndexError---->', e)
except KeyError as e:
print('出现错误 KeyError---->', e)
except Exception as e:
print('出现错误 Exception---->', e)
2
3
4
5
6
7
8
9
10
11
12
实际运用中 except通常都会用 as 关联一个变量,如例子中的 e,方便 print() 打印错误信息。
常见的错误消息名称如下:
| 错误消息名称 | 解释 |
|---|---|
| AttributeError | 尝试访问一个未定义的对象属性时,或对 None 进行属性操作的时候,引发此异常 |
| ImportError | 用 import 导入模块时,未找到指定的模块名称。 |
| IndexError | 尝试从序列(如列表或元组)中检索索引,但是找不到对应的索引编号。注意索引编号是从0 开始的 |
| KeyError | 与 IndexError 类似,尝试访问不存在的 键(key) 时,就会引发此错误 |
| NameError | 尝试使用一个还没声明定义的变量名 |
| SyntaxError | 敲错代码时敲错了,比如少了一个冒号啊,括号没配对啊 |
| TypeError | 数据类型出错,例如将字符串和整数相加就会出错 或 给尝试给元组(Tuple)添加元素 |
| ValueError | 当对象的值不正确时就会引发此错误 |
| ZeroDivisionError | 除数(分母)为 0 |
| IOError | 输入输出错误(比如读取文件不存在路径中) |
更详细的 异常错误消息 请参数官方手册中的 内置异常 部分:
https://docs.python.org/zh-cn/3/library/exceptions.html
看到多个 except 是不是有多路选择的感觉了?在 Python 中是没有 do case 或 switch 类似的语句的,所以在之前,有此程序猿会用 try ... except 来实现类似的功能,来代替 if ... elif ...。好消息是在 Python 3.10 之后的版本中,添加了一个 match 语句,用来实现多路选择的功能。
聪明如你肯定已经想到了,没错! except 也有 else 子句。else 子句必须放在所有 except子句的后面。通常用于没有引发异常但又必须要执行的代码。请看下例:
# -*- coding: UTF-8 -*-
s = input('请输入除数:')
try:
result = 20 / int(s)
print('20除以%s的结果是: %g' % (s , result))
except ValueError:
print('值错误,您必须输入数值')
except ArithmeticError:
print('算术错误,您不能输入0')
else:
print('没有出现异常')
2
3
4
5
6
7
8
9
10
11
12
自己尝试一下运行这个程序吧,并逐行写出每一个语句的意思吧。
# 8.4、 主动捕获异常
try 的子语句 raise,就是用来主动的发出一个异常错误消息,让 try 知道,检查一下出现了啥情况?请参考下面的例子:
# -*- coding: UTF-8 -*-
try:
s = input('请输入除数:')
result = 20 / int(s)
if( s == 0 ):
raise ZeroDivisionError("不能输入0用来做除数")
except ZeroDivisionError as e:
print(e,'算术错误,您不能输入0')
else :
print('20除以%s的结果是: %g' % (s , result))
2
3
4
5
6
7
8
9
10
11
从这个例子中可以看到,当用户输入的数字为 0 时,程序会进入 if 判断语句,并执行 raise 主动抛出 ZeroDivisionError 异常。由于这个异常在 try 的代码块中,因此会被 try 捕获到,并交给 except去处理,打印输出 “算术错误,您不能输入0 ”。如果输入的数字不为 0,就不会有异常发生,就会执行 else 代码块中的指令,打印输出计算结果。
# 8.5、 异常链
“异常链” 这个词儿挺唬人的,第一反应真不知道是个啥。翻译翻译,说人话就是:上面的异常直接导致下面的异常错误。
raise 还有子语句 from ,就是用于处理这种链式异常错误的。 有了这个 from 子句之后,会为异常对象设置一个名称为 __cause__ 的属性,这个属性表示,当前这个异常的是由谁直接引起的,就能指出新异常是因哪个旧异常直接引起的。这样的异常之间的关联有助于后续的分析和排查。
from 子语句后面的表达式必须是另一个异常类或实例。请看例子:
# -*- coding: UTF-8 -*-
try:
print(1/0) # 这明显是一个 除数 为 0 的错误
except ZeroDivisionError as e:
raise ValueError('分母为 0') from e
2
3
4
5
6
运行结果如下

可以看到,使用了 raise 子语句之后,就把异常错误 “ZeroDivisionError” 和 “ValueError” 链接起来了。输出的信息中也包含了一句:“The above exception was the direct cause of the following exception:(上面的异常直接导致了下面的异常错误)”
raise 后面如果写一个 None 那就表示这个忽略上一个异常,不要报告。只报告当前这个异常的错误消息。
# 8.6、 用户自定义异常
除了 Python 内置的异常错误消息之外,用户也可以自已来定义异常错误,显示自己想要的提示消息。异常都应该从 类Exception派生出来 (关于 类、对象、继承(派生)我们还没学呢,后面会详细讨论)。
大多数异常命名都以 “Error” 结尾,类似标准异常的命名。异常类和其他类一样,可以执行任何操作。但通常只用来提供一些输出错误信息的属性就好,别没事找事花样炫技,玩不好玩砸了自己折腾自己。 (在没有学习 “面向对象” 之前,还是先跳过吧)
# 8.7、 定义清理操作 —— finally
try 语句最后一个子语句 finally ,表达的意思也是:try 语句结束前执行的最后一项任务。意即不论有没有异常发生,都会执行 finally 语句块的内容,而且还可以用 break、continue或 return。 (真的好像 do case/swich 中的 deafult 了。好吧,记住 Python 3.10 已经有 match语句了),请参考以下的例子:
# -*- coding: UTF-8 -*-
try:
s = input('请输入除数:')
result = 20 / int(s)
if( s == 0 ):
raise ZeroDivisionError("不能输入0用来做除数")
except ZeroDivisionError as e:
print(e,'算术错误,您不能输入0')
else :
print('20除以%s的结果是: %g' % (s , result))
finally:
print('程序结束。再见')
2
3
4
5
6
7
8
9
10
11
12
13
这个例子中,程序最终总会打印输出一行“程序结束。再见”的文本消息,多有礼貌啊。
# 8.8、 预定义的清理操作
有些语句是自己会完成收尾工作的,比如我们前面用到的 with ,用它打开一个文件之后,它会自动做一个关闭文件的动作,不需要用 close()。同理,也不需要用到 finally 来结束。实际运用中记得自己多多检查,有开有关、有始有终才是正解!
# 本篇小结
本篇讨论的真的是程序员的日常————debug。敲代码哪有不出错的?所以看到程序卡壳了、显示错误消息了,不要慌乱,小事小事。仔细看看错误消息,找到对应的行号、读懂异常错误消息就好了。再加上强大的 IDE 功能,拼写错误一般都很容易发现和处理的。
为了在程序中加上容错机制,就是让程序自动处理一些可能出现的错误,通常用 try 语句,这个功能很强大哦。简单说就是:假设有一段代码可能会出错,就把它放到 try 后面的语句块中,然后用一些 子语句 来分支处理,比如:
| 语句 | 文字描述 |
|---|---|
try ... except (可以写多个 except ) | 每个 except对应一个可能出现的异常错误; Python 3.10 已经有 match语句实现多分支 |
try ... except ... else | 加上 else 子语句可以处理 没有异常 时的分支;注意 else 只和最近一个 except 配对; |
try ... raise | 用来主动抛出一个异常消息,以便 except 捕获,还可以用子语句 from 来做“异常链”,表示异常的前因后果。如果写个 “None”,就表示“不显示原因”。 |
try ... finally | 表示不论有没有异常发生,最后都会执行的语句。finally 后面还可以写 break、continue 或 return ) |
初学者看到错误消息,不必惊慌。如果想让程序自动处理一些错误消息,就多使用 try 语句吧。本篇就到这里吧。
# 第九章 类 —— 面向对象编程
终于我们要开始讨论 面向对象编程(简称OOP)了。一大波僵尸......哦,不对,说错词儿了。一大波概念性的专业术语、名词来了,个个十级硬核、杠杠的,如:类、实例、属性、方法、对象、继承、封装、多态......哎,人呢?真的就是从入门到放弃了。
全跑光了?哈哈,这里真的是一个分水岭。卡住了很多人,我自己也被卡住了很久很久,硬是转不过来,啥是“对象”啊?
好吧,就算是头大猛虎,总是要面对的。来吧!迎难而上吧!!!
最开始的时候,编程这事儿比较简单粗暴,就是一条一条的指令,按照逻辑顺序一一执行就完了,最多也就来个条件分支,用上循环就不得了了,也没别的方式。后来给这种简单粗暴的方式起了个名字叫 一步一步的走路编程法......不对,这词儿太水了。高大上一点,叫 面向过程编程 ———— Procedure Oriented Programming,简称 POP,是不是立马档次飞升了(就是不好好说话呗)。小白初学编程都是 面向过程(一步一步的走路编程法)的,理解了这一点,就算是入门了。
再往后发展,程序猿们进化了一点,学会了使用 函数。就是把经常要用到的一些功能,写成子程序或代码块,把它们放到一个 函数 中 ———— 说白了就是把这些子程序或代码块,起个名字。要用的时候就用 名字 来调用。这样做的好处显而易见:
1、调用方便。只用写一个 函数名称,就可以调用一大段之前写好的代码;
2、一处修改,多处适用。只需要修改函数中的一处代码,那么调用这个函数的所有地方就都适用了。不必一个个的去改,那多累人啊;
3、调用函数的时候还可以传参数,还可以返回结果,各种花式玩法:高阶函数、装饰器、偏函数等等;(停停......我脑仁疼,我先休息下)
学会了运用函数之后,肉眼可见的确实提升了效率,减少了工作量。这就是 面向函数编程 ———— Functional Programming,简称 FP 。理解了 面向函数,可以说是合格的程序猿了。
但 面向函数 编程貌似不怎么有名呢?听都没听说过。这是因为程序猿们进化的很快。当熟练运用 函数 之后,没多久就发展到了 类 的阶段。就像前一个阶段一样,函数其实就是包含一条一条指令的子程序或代码块;类 就是包含函数 和变量的更大的代码块。这样做的好处也挺多:
1、省得为了一点小小的改动又重写整个函数;
2、把一些常用的数据(变量、常量等)也写在一起,省得传参数的时候老出错;这样又有效率、还更安全了。
3、有了 类 之后,那花式玩法更多了,比如 封装、继承、多态性是基本的,还有多重继承、定制类、枚举类、元类......(有一股想拔电源的冲动涌上心头!)
这就是 面向对象编程 ———— Object Oriented Programming,简称 OOP。迈向高级猿的进阶,就是要熟悉掌握运用 面向对象。
以上,就算是“编程捡屎”吧......啊呸,说错了,重说,“编程简史”!
理论说了这么多,来看一个简单的例子吧:打印输出一个乘法表:
# -*- coding: UTF-8 -*-
for i in range(1, 10):
for j in range(1, i+1):
print("{0}*{1}={2} ".format(repr(j),repr(i),repr(j*i).rjust(2)), end='')
print()
2
3
4
5
6
7
这个例子相信都能看懂吧?这就是 面向过程的编程,用了循环嵌套,相当于小学三年级的拔高题了。
接下来我们要整点有难度了,来个初中的题!还是要打印乘法表,而且,打印2遍。而且不止是 9x9 乘法表,这两个乘数是可以随意变化的,比如第一次 9x9,第二次 19x19,没准还有第三次,要 99x99。代码写简单点哈,太复杂了麻烦!加个班哈。(想掐死产品经理了。)这时候就可以用上 函数 了。
# -*- coding: UTF-8 -*-
def cfb(x):
for i in range(1, x+1):
for j in range(1, i+1):
print("{0}*{1}={2} ".format(repr(j),repr(i),repr(j*i).rjust(4)), end='')
print()
cfb(9) # 调用一次函数
cfb(19) # 又调用一次函数
2
3
4
5
6
7
8
9
10
11
这就是 面向函数 编程了。如前面描述的一样,我们把上一个例子中的代码,写到了一个函数中,并给了一个名称 cfb ,而且还写了一个圆括号跟在后面,其中可以填一个数字。表示每次想打印输出的乘法表的数值。然后在第八行和第十行,只用调用这个函数名称,传入一个数值,就可以得到想要的乘法表了。是不是高效便捷多了。自己动手看看这个程序的运行结果是什么吧?
到此为止,相信都没啥问题。接下来,该上高中的题了。看看 面向对象 是如何写代码打印输出乘法表的吧。
# -*- coding: UTF-8 -*-
class PrintCFB:
def cfb(x):
for i in range(1, x+1):
for j in range(1, i+1):
print("{0}*{1}={2} ".format(repr(j),repr(i),repr(j*i).rjust(4)), end='')
print()
PrintCFB.cfb(9)
2
3
4
5
6
7
8
9
10
这有啥子嘛,这不很简单嘛。就是第三行,在函数前面又多加一个名称 PrintCFB 嘛,前面那个 class 确实头一回见,这就是 类 的关键字,和定义函数时用到的 def 一样。
然后第十行,这不就是调用函数吗?把 类名称和函数名称写一起了,中间用了一个英文句点(.)分隔了一下嘛。没有太大意思,搞得还以为多大个事儿呢。
别急嘛,因为有一大堆概念来了,先认识了它们,才能了解 面向对象 的用处啊。
# 9.1、 类和实例
说起 面向对象 ,最重要的一个概念就是 类(Class),刚刚我们已经看到了。它以关键字 class 开头,后面空一格,写上 类 的名称,最后以冒号(:)结束。这和之前自定义函数时区别不大嘛,写函数时的关键字是 def 嘛,然后也是跟着写一个 函数 名称,不同的是函数名称后面有一对圆括号,其中可以写上参数列表,最后也是用冒号(:)结尾。
按照 Python 的语法规则,冒号(:)后面另起一行,要缩进4个空格,开始写代码块。就是要执行什么语句,实现什么功能,代码都要缩进4格就对了。在 类 包含的代码中,可以声明变量 ———— 这些变量被称为 (类的)属性;也可以自定义函数 ———— 这些函数,被称为(类的)方法。现在明白了吧?再捋一下哈:
在 类 中声明的 变量 通常称为 属性;
在 类 中声明的 函数 通常称为 方法;
如果要表达的更精确一点,那就是,类 里面写的 变量 和 函数,在 实例化对象之后,就成为了 对象的属性和方法。
我们来看个简单的例子:
# -*- coding: utf-8 -*-
class Print1_X:
i = 0
def sumX(f):
sum = 0
counter = 1
while counter <= f:
sum = sum + counter
counter += 1
return(sum)
Print1_X.i = 100
print("从 1 加到 {} 的和为: ".format(Print1_X.i))
print(Print1_X.sumX(Print1_X.i))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
哎,这个例子这么眼熟呢?这不就是学习自定义函数时写的从 1 加到 100 求和的例子吗?没错,就是它。只不过我们用到了 类(class),让我们仔细来看一看:
第三行,用关键字(class) 开头,表示我们要定义一个 类,空一格之后写上了类的名称 Print1_X,注意最后的冒号(:)别忘了。和自定义函数时很像吧,def 换成了 class ,后面没有圆括号(其实这里是省略了,通常自定义 类 时都会带一对圆括号,其中写上继承的 父 类的名称,关于 继承 后面会更详细的讨论);
第四行,就是一个简单的赋值语句,需要注意的是,这是在 类 的代码块中写的,按照 Python 语法缩进了4格。这种在 类 代码块里面声明的变量,通常被称为 属性。还记得在 函数 中声明的变量我们一般把它们叫作什么吗?————内部变量(局部变量)。啥?忘光了?有罪,那回去复习一下 《第四篇 函数》 吧。
第五行,就是我们熟悉的自定义函数了。这次是在 类(class)里面自定义一个函数;这种在 类 代码块里面自定义的函数,通常被称为 方法。
第十四行,这一行是顶格写的,也就是说这已经不是在 类(class)里面的语句了。这里我们写的是一个赋值语句,但看起来不太熟悉呢? Print1_X 这个是我们自定义的 类 名称,后面紧跟着一个英文句点(.),然后是一个变量名称 i ,但这个变量是在 类 里面的啊?这样也可以?
对了,这就是 类的 属性引用 。也就是说,类的属性可以通过这种,把类的名称和属性名一起写,中间用英文句点(.)连接的方式来访问。看着眼熟哈,有点 模块(Module) 的味道哦。但从模块中导入的函数,函数中的内部变量也不能从外部访问啊!就算用上 闭包 也得是函数嵌套函数,还要返回函数,才把内部变量传到外层来。想修改之后传回去还得用形式参数才行。啥?一点印象都没有了?这————这是要打屁股的节奏啊。赶快复习一下 《第六篇 初识模块》 吧,把其中的 命名空间、作用域 再温习一下。
第十六行,开始打印输出了。注意在自定义 类 Print1_X 的时候,属性(变量)i 的值是 0,见第四行。但在第十四行时,我们在类的外面,对这个属性(变量)i 用 属性引用 的方式重新赋值了一次。所以我们打印输出看看这个语句执行成功没有?如果成功了,i 应该等于 100;
第十八行,还是打印输出。这次是调用 类 里面的自定义函数 sumX(),注意书写的形式也是 “类名称加上英文句点(.)方法名称” Print1_X.sumX ,同时在传入参数时,书写的形式也是按 属性引用 的格式来写的。
我就常年就没分清,变量和属性、函数和方法、 啥啥的,愁人。有个最直观的方法:
普通的 变量,引用的时候就是直接写变量名称就完事儿了,如:a = 100
而一个 (类的)属性, 用到它的时候,就得用 属性引用 方式,意即 类(或实例对象) 的名称加上一个英文句点(.)连接上属性的名称,如例子中的:Print1_X.i
同理,普通的 函数,调用的时候都像一条指令语句一样直接书写,如前面例子中的
cfg(9)
cfg(19)
2
3
而一个 (类的)方法 在书写的时候,也一定是按 属性引用 的格式,“类名称加上英文句点(.)方法名称” 。如例子中的:
PrintCFB.cfb(9)
Print1_X.sumX()
2
3
认识了 属性 和 方法 之后,现在我们要来点小魔法了,看看 类 的神奇所在。
# -*- coding: utf-8 -*-
class nothing:
pass
nothing.i = 100
print("绑定了一个属性 i :",nothing.i)
nothing.a = abs
print("绑定了内置函数 abs() ",nothing.a(-199))
2
3
4
5
6
7
8
9
10
11
12
这个例子中:
第三行,定义了一个类,名为 nothing,也确实其中啥啥都没有, pass语句就是表示什么也不执行;
第六行,我们的魔法来了,这一行是给 nothing这个类的 属性(变量) i 赋值,但如前所看到的,在定义类的时候,并没有在 类 的代码块中,写任何属性;
第八行,试试打印输出这个 i ,看看真的存在吗?成功赋值了吗?
第十行,我们更厉害了,给 nothing 又添一个属性 a ,并且赋值是 abs ,没错,这是一个 Python 内置函数 abs() ,也就是说 nothing.a() 现在等同于 abs(),把一个内置函数赋值给了一个 类 的属性;
第十行,验证一下,打印输出看看是不是真的可以实现 abs() 求绝对值的功能;
请自己手动敲敲代码,看看运行的结果是否如预期吧?
这就是 类 的神奇之处。也就是说定义了一个 类 之后,其实是可以随时添加 属性 和 方法 的,这种把 变量 和 函数 赋值给一个 类 的操作,通常称为 绑定。换一个角度看,一个 普通的变量 或 函数,把它和一个类 绑定,那么它就成为了一个类的 属性 或 方法。而且 绑定 这个动作是可以随时完成的,没有什么限制条件。
Amazing ————
并且,再进一步。众所周知,类 是一个模具,就是一个模版,是用来复制更多的成品的,复制品被称为 实例(对象)。请参考下例:
# -*- coding: utf-8 -*-
class nothing:
pass
x = nothing()
y = nothing()
x.i = 100
print("绑定了一个属性 i :",x.i)
y.a = abs
print("绑定了内置函数 abs() ",y.a(-199))
2
3
4
5
6
7
8
9
10
11
12
13
与前面一例的区别仅仅在于 第六行和第七行。声明了2个变量 x 和 y ,它们都是类的实例(对象),书写的格式就是把 类 的名称加上一对圆括号,赋值给等号左边的变量名,就OK了;
然后,
给 x 绑定了属性 i,
给 y绑定了方法 abs;
看看运行结果吧?是不是和上例一模一样?
好了,魔术表演结束。上例只是为了清晰的演示,类 、属性、方法以及绑定操作,让我们便于理解它们的特性和相互的关联。在实际运用中,不会闲着没事去定义一个什么都没有的 空 类。而且也不会直接使用 类 的名称,肯定是用 类 来copy出很多实例(对象),这才是正经的运用方式———— 实例化。
所以,类 有两种使用方法,一个是前面提到的 属性引用,一个就是 实例化。实际运用中,通常都是用 实例化 的方式来使用 类 产生多个对象,这些对象就拥有了 类 中的定义的 变量和函数,在 对象 中就叫作 属性和方法 了。
就像前面提到过的,类 里面写的 变量 和 函数,在 属性引用 时,仍然是变量和函数。在 实例化 对象之后,就成为了 对象的属性和方法。
# 9.2、 封装——自定义 类 的过程
在开始写自定义 类 的时候,通常就会把必要的 变量(属性) 和 函数(方法) 直接写到 类 的代码块中,具体就是一个特殊的 函数(方法) __init__ 中。请看下例:
WARNING
注意:特殊函数(方法) __init__ 前后分别有两个下划线!!!
# -*- coding: utf-8 -*-
class X(object):
"""
这里可以写 类 的说明文本,它会保存在 __doc__ 这个属性中
"""
def __init__(self, i, j):
self.i = i
self.j = j
def print_Attribute(self):
print('类 X 有2个属性,一个是i={0} ,一个是j={1}'.format(self.i,self.j))
print(X.__doc__)
Y = X(100,3.14159)
Y.print_Attribute()
""" 运行结果
这里可以写 类 的说明文本,它会保存在 __doc__ 这个属性中
类 X 有2个属性,一个是i=100 ,一个是j=3.14159
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这个例子已经几乎是一个“五脏俱全”的 类 的例子,与实际运用中的情景也十分接近。
第三行,用 class 关键字,开始声明一个自定义 类(class),名称就是 X,后面有一对圆括号,其中有一个关键字 object,表示这个 类(class) 继承 于 object 这个 类(class),换句话说 object 是 X 的爸爸。实际上在 Python 中,每一个 类(class) 都有爸爸,如果没有,那 object 就是它的爸爸,(类(class) 是单性繁殖的,所以没有妈妈)object是所有 类(class) 的祖宗。关于 继承,我们后面还有更多的讨论。最后以英文冒号(:)结尾;
第四行到第六行,是这个 类(class) 的说明注释文本,这是一个好习惯。自定义一个 类(class) 的时候,写上这个 类(class) 的简短说明。并且这些文本也会保存在这个 类(class) 的一个名为 __doc__ 的特殊的属性中。后面可以用 print 来打印输出这个属性。
第七行,在 类(class) 的代码块中,缩进了4个空格书写,用 def 关键字自定义一个 方法(函数)。因为这个函数在 类(class) 里面定义的,所以通常被称为 方法。这个方法的名称比较特殊,就是 __init__ ,注意这个名称前后都有2个下划线(_),通常这个方法被称为 “初始化方法”。紧接着是一对圆括号,其中就是这个方法需要的形式参数了。注意第一个形式参数 self 是必须的,如字面意思,就是表示 “ X 自己”,意即这个 self 后面的 属性,都要绑定到 X 自己身上。在这个例子中,我们看到后面写了2个参数 i 和 j 。最后以英文冒号(:)结尾;
第八行和第九行,在 初始化方法 __init__ 里面,因为又缩进了4个空格。属性 i 和 j 被赋值;
第十一行,在 类(class) 的代码块中,我们又自定义一个普通的 方法(函数),名称为 print_Attribute,后面的圆括号中有一个形式参数 self ,也是表示 “ X 自己”。最后以英文冒号(:)结尾;
第十二行,这个普通的方法里面 print_Attribute,只有一条语句,就是打印输出属性值 i 和 j;到此,自定义类 X 的代码块就全部完成了。
第十四行,如前所述,我们用 print 语句来打印输出 类(class) 的一个特殊的属性 __doc__,可以看到我们书写的有关这个类的说明文本;如果没有写说明文本,那就没有什么可打印输出的。所以写注释是一个好习惯。
第十六行,声明了一个变量 Y ,赋值 X,这个语句,表示 Y 是 类 X 的一个实例对象。注意 X 后面有圆括号,其中传入了2个实际参数。但 __init__明明有3个形式参数啊? self 是不需要传入的,如字面意思,它就表示 的是 X 自已;
第十八行,因为 Y 是来自于 X 的一个实例对象,因此它也带上了 X 中定义的属性和方法。所以,这里我们直接调用方法 Y.print_Attribute(),而且都没有传递参数。因为这个方法需要的形式参数只有一个,就是 self ,这就表示X 自已,所以在这个 方法print_Attribute() 里面的 self.i 其实就是 X.i,self.j 也就是 X.j,然后打印输出,看看结果如何;
简单捋一下:
自定义一个 类,用的关键字是
class,然后空一格写个名称,比如叫 X,通常紧接着后面会有一对圆括号,其中写的是父类的名称,表示这个类 继承 于哪个类。如果没有写圆括号,那么其实在 Python 中object是所有类的 爸爸,(你大爷始终是你大爷);紧接着 类 名称的下一行,写上注释说明文本,用三个引号包括起来(""" 注释说明文本 可以写多行""")这是一个好习惯。这些文本会保存在这个 类 的特殊属性
__doc__中,之后可以打印输出;通常在一个自定义的 类 中,会写一个 初始化方法
__init__, 在这个初始化方法中,第一个参数永远是self,这是必须的,后面写了 2 个形式参数i和j表示这2个属性绑定到 X 这个类的自已身上。换句话说,X 现在已经自带了2个属性,X.i和X.j;接下来就是在 类 X 中,自定义了一个普通的方法
print_Attribute,并且形式参数只有一个self,也是表示自己。这个方法中只有一条语句,就是打印输出自己的2个属性的值。普通方法不要求必须有self参数;然后我们就可以来使用 类(class) 了,有两种方式 属性引用 和 实例化。
属性引用更像是在调用函数,直接用 类 的名称英文句点(.)属性/方法名称 来访问。例如:X.i , X.j
而实际运用中,更多的是用 实例化 的方式。就是用一个赋值语句,把 类 X 赋值 给 一个变量 Y ,注意 X 有绑定属性的时候,要在后面的圆括号中,把属性的值传递进去,颇有点调用函数传递实际参数的感觉哈。这样 Y 就是来自 X 的一个实例对象了,它就自然的带上了来自 X 的属性i和j,还有方法print_Attribute;调用 类的方法 就和调用函数一样,唯一的区别就是调用 类的方法 时,要把类的名称(或实例对象的名称)和方法(函数)名称都写出来,中间用一个英文句点(.)连接,其它方面和使用普通函数没有区别。
面向对象 的好处之一,已经初现端倪了。很明显,如果把 类(class) 里面的代码块写好了。那么在调用的时候就十分简单和高效了。几乎和调用函数一样一样的。这种把 属性 和 方法 都写到 类(class) 的代码块中的方式,被叫作————封装。
封装好的 类 ,可以通过赋值语句,生成无数多个实例对象,每个对象都拥有 类 定义时的属性和方法。如:
# -*- coding: utf-8 -*-
class X(object):
def __init__(self, i, j):
self.i = i
self.j = j
def print_Attribute(self):
print('类 X 有2个属性,一个是i={0} ,一个是j={1}'.format(self.i,self.j))
Y = X(100,3.14159)
Y.print_Attribute()
Z = X(1.27,999)
Z.print_Attribute()
""" 运行结果
类 X 有2个属性,一个是i=100 ,一个是j=3.14159
类 X 有2个属性,一个是i=1.27 ,一个是j=999
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
例子中我们可以看到,X 这个 类,我们用实例化 的方式赋值了2个对象,一个是 Y ,一个是 Z ,因为它们都来自于 类 X ,所以它们都有属性 i 和 j,并且在 实例化 的时候,Y 和 Z 传入的数值是不同的。当然也有方法 print_Attribute(),所以打印输出的结果也不同。
那么问题来了,这个 i 和 j 可以随时被实例对象修改啊。不,我不想。我不要这2个属性被修改,要固定下来。好吧,简单。只用在自定义 类 的时候,在 初始化方法 __init__中给属性(变量)的名称前加上两根下划线(__),如此一来,这个属性就变成了一个 私有属性(变量),它就只能在实例化对象时,传入一次参数,用来赋值,之后外部就不能访问了。在 Python 参考手册中,也被称为 实例变量。请看下例:
# -*- coding: utf-8 -*-
class X(object):
def __init__(self, i, j):
self.__i = i # i 前面加了2根下划线 __ 这个 i 就是一个私有属性了。
self.j = j # j 仍然是一个普通属性,外部可以访问
print("私有属性,只能在 类 里面访问 __i =",i)
print("普通属性,外部也可以访问 j =",j)
def print_Attribute(self):
print('类 X 有2个属性,但 i 是私有属性 ,只有j可以外部访问 j={0}'.format(self.j))
Y = X(100,3.14159) # 实例化对象的时候,传入参数,用于赋值 i 和 j
Y.print_Attribute()
"""下面2个语句是无法执行的,会报错。
(私有属性,只能在 类 里面访问 __i = 100
普通属性,外部也可以访问 j = 3.14159
类 X 有2个属性,但 i 是私有属性 ,只有j可以外部访问 j=3.14159)
print(Y.__i) # 外部的实例对象是无法访问 私有属性的
print(X.__i) # 在外部,用 属性引用 的方式,也是无法访问 私有属性 的
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这个例子的运行结果,请你手动写出来吧。正确(正经的)的自定义 类(class) 的书写应该使用 私有属性(变量)———— 实例变量,而尽量避免使用 普通属性(变量)
好了,新的需求又来了(就问你怕不怕?!),就是要在外部获取 私有属性 i 的值 ,怎么办?!
那就得在 类X 里面写一个 方法,名称就叫 get_i 吧。从外部通过调用这个方法,就可以访问 私有属性 i 了,请看下例:
# -*- coding: utf-8 -*-
class X(object):
def __init__(self, i, j):
self.__i = i # i 前面加了2根下划线 __ 这个 i 就是一个私有属性了。
self.j = j # j 仍然是一个普通属性,外部可以访问
print("私有属性,只能在 类 里面访问 __i =",i)
print("普通属性,外部也可以访问 j =",j)
def get_i(self):
return self.__i
def print_Attribute(self):
print('类 X 有2个属性,但 i 是私有属性 ,外部可以直接访问 j={0}'.format(self.j))
Y = X(100,3.14159)
Y.print_Attribute()
print("通过方法 get_i() 来访问私有属性 i =",Y.get_i())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
自己动手,看看这个例子的输出结果吧。
好了————需求又来了(我的刀呢?!)在外部代码不仅要获取、还要修改、私有属性 i 的值,怎么办?!!
哎,好吧,满足你。再写一个 方法,名称就叫 set_i 吧。如下例:
# -*- coding: utf-8 -*-
class X(object):
def __init__(self, i, j):
self.__i = i # i 前面加了2根下划线 __ 这个 i 就是一个私有属性了。
self.j = j # j 仍然是一个普通属性,外部可以访问
print("私有属性,只能在 类 里面访问 __i =",i)
print("普通属性,外部也可以访问 j =",j)
def get_i(self):
return self.__i
def set_i(self,i):
self.__i = i
def print_Attribute(self):
print('类 X 有2个属性,但 i 是私有属性 ,外部可以直接访问 j= ',self.j)
Y = X(100,3.14159)
Y.print_Attribute()
Y.set_i(2020) # 通过调用方法 ,来修改 私有属性 i 的值 ;
print("通过方法 get_i() 来访问私有属性 i =",Y.get_i())
""" 运行结果
私有属性,只能在 类 里面访问 __i = 100
普通属性,外部也可以访问 j = 3.14159
类 X 有2个属性,但 i 是私有属性 ,外部可以直接访问 j=3.14159
通过方法 get_i() 来访问私有属性 i = 2020
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
这个例子中,
第五行,在类 X 里面,初始化方法 __init__ 里面的 i 是一个私有属性;
第十一行,在类 X 里面,自定义了一个方法 get_i(),用来把 私有属性 i 返回到外部,这样从外部就可以获取到这个 i的值了;
第十四行,在类 X 里面,又自定义了一个方法 set_ii(),就执行一个语句,把接收到的参数,赋值给 私有属性 i,如此一来就实现了从外部修改 私有属性 i 的值了;
第二十二行,调用方法 set_i(2020),表示要把 2020 这个数值传入到 类 里面去,然后修改了 私有属性 i 的值;
最后,打印输出结果,看看是否如我们预期的一样。
好,那么需......(刀已出鞘),不是,让我说完嘛,自定义 类 的时候,就用普通的属性,不要加什么下划线不就好了吗?比如那个属性 j 本来就可以直接从外部访问,也可以从外部修改啊?你这搞来搞去,还多定义两个方法(函数),大费周折的搞啥嘛?(刹————世界安静了。)

在 类 里面的私有变量 i 是不是就真的一定不能从外部访问呢?其实也不是。因为 Python 解释器对外把 __i 变换成了 _X__i。所以,在外部仍然可以通过 _X__i 来访问 私有变量 i
WARNING
但是强烈建议你不要这么干,因为不同版本的 Python 解释器可能会把私有变量 __i 变换成不可预知的变量名。Pyhton 3.10 中已禁用这种方式访问 私有属性!!
不要干坏事,一切靠自觉。
那为什么要用 私有属性,又写2个方法分别来 获取 和 修改。直接用普通属性就很方便啊。
一,确实是甲方要求;
二,直接用普通属性确实方便,但安全性很弱。甚至会导致不可预期的错误;
用私有属性,然后用方法来获取和修改就可以加上限制条件。这样程序更安全、代码更健壮。实际工作中也更多的是用这种方式。甲方的要求当然是“又方便又安全”,如设计中的“五彩斑斓的黑”。
需要注意的是,在 Python 中,如果你看到别人写的程序中,出现了 类似 __xxx__ 的变量名称,也就是以双下划线开头,并且以双下划线结尾的变量名称,那都是特殊变量,特殊变量是可以直接访问的,不是 private 变量。所以,不能用 __name__、__score__ 这样的变量名。
有时,你还会看到以一个下划线开头的实例变量名,比如 _name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
# 9.2、 继承——节省复制粘贴的操作
前一节,我们认识了 类,自己定义了 类,经历了写一个类的全过程,这个过程就是封装。
接下来,我们要学习 继承 这个概念。如果不用上这个概念,那 类(class)就没有意义。
在 Python 中,满眼全是实例化的对象。
一个简单的变量,是一个实例化的对象;
一个列表也是一个实例化的对象;
一个字典当然也是一个实例化的对象;
我不信,(把我都说糊涂了,一个简单的变量 A ,它咋就是对象了呢?),除非你直播吃......证明给我看。
简单,前面我们已经知道了,一个 实例化的对象,肯定是来自于一个 类(class),类 里面如果 封装 了属性和方法,那必然这个对象也拥有这些属性和方法。那我们说一个普通的变量 A ,也是一个对象,那它肯定也是属于一个类(class),也肯定拥有这个类(class)里面封装的 属性 和 方法啊。来看例子:
# -*- coding: utf-8 -*-
a = 100 # 这明显是一个最简单的变量
print("变量a占用的内存字节数量:",a.__sizeof__())
print("变量a打印输出的字符:",a.__str__())
""" 运行的结果
变量a占用的内存字节数量: 28
变量a打印输出的字符: 100
"""
2
3
4
5
6
7
8
9
10
11
12
这是一个很简单的例子:
第三行,声明了一个变量 a,赋值为 100;
第五行,打印输出语句。这时书写的是 a 后面紧接着一个英文句号(.),然后紧接着是一个前后都有两根下划线的方法名称 __sizeof__,说明这是一个特殊的名称,而且最后还是以一对圆括号结尾,说明这是一个方法(函数);
第七行,再一次用了打印输出语句。后面书写的是 a 后面紧接着一个英文句号(.),然后紧接着是一个前后都有两根下划线的方法名称 __str__ ,说明这是一个特殊的名称,而且最后还是以一对圆括号结尾,说明这是一个方法(函数);
那么问题来了,这个 __sizeof__ 和 __str__ 是哪儿来的?这程序一共也才 7 行。a 就是一个简单得不能再简单的变量了,哪儿来的方法(函数)?又没有引用模块,又没有定义类,这就奇了怪了。
原因就是,在 Python 中,就像有 内置函数 一样,也有 内置的 类(class)。不需要导入引用,不需要声明,启动 Python 的时候就已经准备好了,可以直接用。上一节中,我们已经提到过了,有一个名称叫 object的 类(class),是所有 类(class) 的爸爸。(在 Java 和 JavaScript 中也有一个类似的祖宗,也叫 Object ,首字母是大写)也就是说,在 Python 中,所有的 对象 都自带有 object 中定义的属性和方法。那么 object 中倒底有些什么东西呢?通过一条指令,就可以知道了,那就是:
print(dir(object))
dir 是一个内置函数,不带参数时,返回的是一个列表,其中包含的是当前范围内的变量、方法和自定义的 类(class) 。这里我们传入的参数就是 object ,表示把 object 中的属性、方法放在一个列表中,给打印输出看看。
得到的结果是一个列表,其中包含了 object 中所有的属性和方法,如下所示:(注意:Python 版本不同略有差异)
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
2
这下就明白了,我们刚刚在一个最简单的变量 a 后面加上一个英文句点符号(.),然后居然可以接着写 __sizeof__ 和 __str__,而且还不出错,还有效。原因就在这里了,因为在 Python 中,有一个最厉害的 object ,它是所有对象的爸爸,通常称为 父类、基类 或 超类。所以,在 a 的后面,还可以加上 __doc__ 啊,__repr__ 啊,你可以自己动手试试。这些 方法 的具体意思可以参考手册中的链接:
https://docs.python.org/zh-cn/3/reference/datamodel.html?highlight=dir%20object#basic-customization
现在,我们还是初学者,所以有个概念和印象就可以了,以后再深入的讨论。
如上所说,object 是 Python 中所有 对象 的祖宗,一个最简单的变量,都带有 object 中的方法。那自定义一个 类(class) ,肯定也带有 object 中的啰,我不信!实践出真知,我们看例子:
# -*- coding: utf-8 -*-
class Y:
pass
print("自定义一个空的 类 Y,它带有 ` object ` 的方法:\n",dir(Y))
2
3
4
5
6
7
这个例子中,自定义了一个 类, 名称为 Y,其中什么也没有,只有一个 pass语句。但在打印输出 Y 的方法时,可以看到,其实有很多内容的,它们都来自于 object 这个祖宗。事实胜于雄辩!
运行结果:
自定义一个空的 类 Y,它带有 ` object ` 的方法:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
2
3
这就说明 object 基因强大,Y 全部 继承 了 object 中的所有的方法。
那么问题来了,Y 也是一个 类, 它能不能下崽儿? 它的优秀基因也要传宗接代啊。当然是可以了,请看下例:
# -*- coding: utf-8 -*-
class Y:
y1 = 100
def y2():
return ("我是Y的方法y2")
class Z(Y):
pass
print("Z自己啥也没有,但继承了Y:",dir(Z))
print(Z.y1)
print(Z.y2())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
我们来仔细看看这个例子:
第三行,自定义一个 类,名称为 Y,后面不带圆括号,那默认情况下,object 就是 Y 的爸爸;
第四行到第七行,在 Y这个 类 里面,我们声明了一个普通的属性(变量)y1 并赋值为 100,又声明了一个方法(函数),名称为y2,只执行一个指令,返回一个字符串“我是Y的方法y2”。到此,自定义 Y 结束。
第九行,自定义一个 类,名称为Z,名称后面有一对圆括号,其中写着 Y ,这就表示,Y 是 Z 的爸爸,Z 是 Y 的儿子(子类),自然的就拥有了父类的属性和方法。当然,因为 Y 同时也带有来自 object 的方法,所以 Z 也顺其自然的带有来自 object 的方法;
第十行,Z 这个类中,啥啥也没有,只有一个 pass
第十二,十四,十六行,打印输出看看,验证一下。
通过这个例子,就应该可以理解 继承 了吧?很明显的好处就是,儿子可以轻松的拥有爸爸的属性和方法。同时,还可以写自己的属性和方法,再传给自己的儿子。妙啊————
其实 Z 不仅 继承了 Y 的属性和方法,当然也 继承了 object的属性和方法啊。不信就用指令:
print(dir(Z))
看看结果吧。这就是 多重继承 ,也就是说自定义一个 类(class)的时候,不需说明,肯定是会 继承 object 中的所有属性和方法的,同时也可以在圆括号中,指定不限于 1 个父类,可以有多个父类。这样做的好处很明显,可以很轻松的 继承(获得)已有 类(class) 中的属性和方法,但同时又可以书写属于自己的。妙不可言啊————
那么问题来了,(我头上的老筋啊都开始跳了)如前所述,类 Z 的对象,可以 继承 类 Y 的属性和方法,这个很通顺了,自然而然的事情。但是, 类 Y 有想法,y1 这个属性,我只想给 Y 的对象,不让 Z 的对象用,可不可以?行不行?我就要!(OK,你厉害!)
如果要达到这个目的,就要使用 __slots__
可以定义一个特殊的 __slots__ 变量,来限制 类(class)的 实例化对象 获取属性或方法。
WARNING
因版本变化,__slots__ 的用法尚有不确定性,因此暂不讨论。实际工作中也较少运用。
# 9.3、 多态——子类用同名属性或方法 覆盖(Upgrade)父类
那么问题又来了,Z 自身就是一个类,当然也可以有自己 属性和方法,它作为 Y 的子类,也 继承 了 Y 的属性和方法。那 Z 的属性,可不可以起名称为 y1 呢?,Z 的方法,可不可以起名称为 y2。(你就不能用 z1,z2,区分开多好呢?————不,我就要!我喜欢!)好吧,来看例子吧:
# -*- coding: utf-8 -*-
class Y:
y1 = 100
def y2():
return ("我是Y的方法y2")
class Z(Y):
y1 = 1.99999
def y2():
return ("我是Z里面的方法y2")
print(Z.y1)
print(Z.y2())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
从这个例子,可以看到。Z 是 Y 的子类,自然就 继承 了 Y 的属性 y1 和 方法 y2 。但是在 Z 自己的代码块里面,又声明了属性 y1 和 方法 y2。由于名称和父类 Y 中属性方法是一样的,于是就把 继承 来的属性和方法给 覆盖 了。也就是说,在 子类 中如果重新声明了属性和方法,与父类中的属性和方法重名,则 子类中的属性和方法有效————这就是 多态。换句话说,儿子可继承,还可以修改,变强(也可能败家)。
理解了 多态 ,聪明如你一定也看到这种特性的好处了。从一个 object 开始,就可以有儿子、有孙子、并且每个儿子、孙子还都可以有自己的属性和方法、并且还允许使用相同的名称、新一代的相同名称的属性和方法会 覆盖 上一代的功能。真是一生万物、繁荣昌盛啊。
这些 类 的特性,其中就包含着“开闭”原则,简单说就是,一个 类 里面定义好的属性和方法,一次 封装 之后随时可以调用,不必频繁修改。这叫————修改封闭;子类 自然就拥有 父类 的属性和方法,继承 不受限制,子类的数量也不限,父 类 可以 无数个子类,这叫————扩展开放(放开生育的味道啊);
在这里要提一下 静态语言 VS 动态语言
静态语言(例如Java,C)来说,对于数据类型,类 有比较严格的限制。意即计算处理的时候,必须先搞清楚要处理的数据类型,严谨,有学究范儿。否则,将无法执行。
动态语言(例如 Python ,JavaScript ,PHP) 就比较随性了。一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被当作是鸭子。也就是 Python 中的 “file-like object” 就是一种鸭子类型。对真正的文件对象,它有一个read()方法,返回其内容。但是,许多对象,只要有read()方法,都被视为“file-like object“。许多函数接收的参数就是“file-like object“,你不一定要传入真正的文件对象,完全可以传入任何实现了read()方法的对象。
(我本人更喜欢 静态语言,精准无歧意。可能时代不同了吧?编程也要任性了,从 PHP 开始风气就变了。)
# 9.4、 优先用 isinstance() 判断类型
那么问题来了。我们说过在 Python 中,一切皆对象。一个普通的变量是对象、一个函数也是对象、自定义的类生成的实例那更加确定是一个对象了。乱了乱了,我得捋捋。
那之前,我们学习过的什么数据类型又是啥?还记得有个内置函数 type() 吗?可以用来获取一个数据的类型,如下例:
# -*- coding: utf-8 -*-
print(type(123))
print(type('这是一个字符串'))
print(type(None))
print(type(abs))
2
3
4
5
6
7
8
9
那我们刚刚定义的 类 呢? 生成的对象呢?它们的 type() 是啥?实践出真知,承接上面的例子:
# -*- coding: utf-8 -*-
class Y:
y1 = 100
def y2():
return ("我是Y的方法y2")
class Z(Y):
y1 = 1.99999
def y2():
return ("我是Z里面的方法y2")
a = Y()
b = Z()
print("实例对象 a 是来自哪个类?",type(a))
print("实例对象 b 是来自哪个类?",type(b))
"""
实例对象 a 是来自哪个类? <class '__main__.Y'>
实例对象 b 是来自哪个类? <class '__main__.Z'>
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
由上例可以看到,自定义的类,生成的对象,用 type() 即可返回这个 实例对象 的 类 名称。但是 type() 无法显示出继承关系。因此,在日常工作中,更多的是使用 isinstance() 来判断对象的类型,意即,a 是 Y 的实例化对象吗?返回的结果非真即假(True/False)。在上例中,加上以下语句,看看结果吧:
print("a 是 Y 的实例化对象吗?",isinstance(a, Y))
print("b 是 Y 的实例化对象吗?",isinstance(b, Y))
2
3
其实在更多的情况下,isinstance() 完全可以代替 type() 存在。如:
print(isinstance('a', str)) # a 是否是 字符串类型
print(isinstance(123, int)) # 123 是否是 整数类型
print(isinstance(b'a', bytes)) # b'a' 是否是 二进制数
print(isinstance([1, 2, 3], (list, tuple))) # [1,2,3] 是否是 列表 或 元组?
print(isinstance((1, 2, 3), (list, tuple))) # (1,2,3) 是否是 列表 或 元组?
2
3
4
5
6
7
8
9
10
TIP
总是优先使用isinstance()判断类型,可以将指定类型及其子类“一网打尽”。
# 9.5、 获取属性和方法的常用函数
- dir()
这个函数,在介绍所有 类 的祖爷爷 object 的时候,我们已经见过一次了。就是把一个 对象/类 的全部属性 和 方法给打印输出显示。(仍然还记得 DOS 时代,dir 指令就是列出目录列表的指令,同理。)再复习一下吧:
print(dir(object))
- getattr()、setattr()和hasattr()
这 3 个内置函数当然是一起说,它们就是字面意思:
getattr() ———— 获取属性;
setattr() ———— 设置属性;
hasattr() ———— 有这个属性吗?
还是来看例子,比较直观:
# -*- coding: utf-8 -*-
class Y:
y1 = 100
def y2():
return ("我是Y的方法y2")
class Z(Y):
y1 = 1.99999
def y2():
return ("我是Z里面的方法y2")
a = Y()
b = Z()
print("实例对象 a 有 y1 这个属性吗?",hasattr(a,'y1'))
print("实例对象 b 有 y1 这个属性吗?",hasattr(b,'y1'))
print("获取对象 a 的属性 y1 的值: ",getattr(a,'y1'))
print("获取对象 b 的属性 y1 的值: ",getattr(b,'y1'))
setattr(a,'y1',666)
print("修改后对象 a 的属性 y1 的值: ",getattr(a,'y1'))
setattr(b,'y1',3.1415926)
print("修改后对象 b 的属性 y1 的值: ",getattr(b,'y1'))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
请自己动手运行一下这个例程吧,看看结果如何?
WARNING
注意:如果试图获取不存在的属性,就会遇到 AttributeError 的错误
同样,这些内置函数,也可以获取到 对象 内部的方法。
通常情况下只有在不知道 对象 内部信息的时候,才会去用这些函数。聪明如你,一定想到了,其实明明可以直接写:
print(a.y1) # 这不就直接获取了 a 的 属性 y1 么?费那事儿?
a.y1 = 666 # 这不就直接修改了 a 的 属性 y1 的值么?
# 没毛病!
2
3
4
5
所以,getattr() 、 setattr() 和 hasattr() 这 3 个内置函数只会在剖析一个 对象/类 的内部信息时才会用到。更多的时候,直接去翻阅 api 手册之类的详细资料就可以了。
前面提到过,Python 是一种动态语言,说白了就是一种“随便”的语言,写代码的时候可以更淘气一些。比如,变量直接用不声明啊、继承了 类 的属性还可以用重名给覆蓋掉啊,甚至一个 实例化的对象,也可以随时加个英文句点带上自己的属性啊,这样一个对象自己随意添加的属性名称还居然可以和从 类 中继承下来的属性 重名,程序也不会报错。—————(真是乱套,都用同样的名称,脑子都乱了)
WARNING
所以,再次提醒。虽然 Python 语言给了我们更大的自由度,让我们书写代码时可以更随性。
但一切靠自觉,不要干坏事儿。
# 本篇小结
终于到了本篇小结了,不容易啊。曾经在 类(class) 这个概念上掉进了大坑。仔细想想,主要还是前面的基础不牢、迷糊不清。再加上很多教程上描述得不知所云,总和你扯什么猫猫狗狗四条腿、鸭子和人两条腿之类的例子,愁人。就好像刚开始学数数,2个苹果 加 3个 苹果 等于几个苹果,结果小朋友关心的不是数学,而是自己能吃到几个苹果。O了,吐槽没完了,来劲儿了,是吧?
编程从一开始就是一条一条的写指令(语句),敲代码。逻辑顺序排好、别敲错。程序就运行(跑)起来了,得到了预期的结果,就是如此简单。
随着需求越来越多、越来越复杂、要敲的代码自然就越来越多啰。程序猿们发现,其实有很多代码都是重复的,执行的指令是一模一样的,或者只有小小的改动 ———— 比如1-2个变化的数字。于是,就把这种重复的代码块,写到一个 函数 里,需要执行的时候,就通过一个 函数名 调用就可以了,还可以把变化的数字,以 形式参数 的方式传过去,把计算之后的结果传回来。这下方便多了,工作量一下减轻不少。而且前辈们已经写了不少很好用的 函数 ,可以在导入模块后即可调用,多么方便啊。
接下来项目的复杂程度与日俱增,敲代码的工作量何止是指数级暴涨?简直是令人发指!(奇葩的 脑回路 比 最复杂的打结缠绕的耳机线更可怕1000倍,而且他还坐在甲方/BOSS的位置上,但凡是个产品经理早被拖到厕所打死10000遍了。)于是爱动脑筋的程序猿们就把经常要重复用到的 函数 和 与之相关的变量 也组合起来,形成一个 类(class)
写在 类(class) 里面的 变量,实例化对象之后,被称为 属性,
写在 类(class) 里面的 函数,实例化对象之后,被称为 方法,
这样做的好处,又进一步减少了敲代码的工作量:
通过 继承 就可以轻松简单的把之前写过的诸多的 类(class)的代码,一下子全都搬过来了。(就是复制粘贴嘛,说得这么理直气壮)
通过 封装 来新添自己的代码以适应新的需求。或参考前辈们的代码,重头写一个自己的 类(class)(直说照抄就得了)
通过 多态 可以用一模一样的 属性/方法 名称,来 覆盖 即有的属性和方法,多么的方便。
理解了 封装、继承和多态,那就可以说关于 类(class),你及格了。
在 Python 中,所有的 类(class) 都有一个祖宗,它就是 object。意即,只要是在 Python 中的 类(class) 都自动继承了 object 的 属性和方法。
那么 object 这个祖宗 类(class)都有什么属性和方法呢?我们可以用内置函数 dir() 来查看;内置函数中还有几个和 类(class)有关的函数,我们也用到了,比如:
getattr()
hasattr()
setattr()
isinstance()
2
3
4
所以,现在做一个项目,编写一个程序。真的和以前不同了。
以前写一个程序,自己从第一行代码开始写,每一个变量、每一条语句,都要自己先反复思考、仔细琢磨。然后才敢战战兢兢的动手敲代码;
现在写一个程序,先找找有没有合适的 框架(就是现成的,集合了很多类、模块、包,可以直接调用的程序源码文件),看看文档,学习下有没有合用的、趁手的金箍棒,不,说错了,适用的模块、包。先导入再说,然后调用需要的功能,满足需求就可以了。
好了,就小结到这里吧,再说多了,就超纲了。
# 期中复习
什么?才期中?都走了这么远了,才走了一半?
你想多了。一半还差得远呢,象征性的用“期中”这个词儿意思意思。
确实内容也不少了,所以需要复习总结一下。
从我们认识 Python 开始,无论是安装了什么环境和代码编缉器,比如 IDLE、Jupyter、PyCharm、VS code(我就是用的这个)、Spyder......
只要是运行了 Python,那么在你的电脑世界的内存中,就有了一些 Python 的内置函数 和 一个祖宗类 Object
| Built-in Functions 内置函数 | |||
|---|---|---|---|
A
abs() B
bin() C
callable() D
delattr() | E
enumerate() F
filter() G
getattr() H
hasattr() I
id() | L
len() M
map() N
next()
O
object() P
pow() | R
range() S
set() T
tuple() V
vars() Z
zip() _
__import__() |
官网链接:
https://docs.python.org/zh-cn/3/library/functions.html?highlight=built#ascii
关于 Object 这个所有类(class) 的祖宗,可以运行以下代码以帮助理解:
# -*- coding: utf-8 -*-
print(dir(object)) # 用内置函数 dir() 来获取 object 中的全部方法和属性,然后打印输出。
print(object.__doc__) # 打印输出 objet 的一个属性 __doc__ 的值。这是关于这个类的简单描述文本。
2
3
4
5
运行结果应该如下:
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
The base class of the class hierarchy.
When called, it accepts no arguments and returns a new featureless
instance that has no instance attributes and cannot be given any.
2
3
4
5
6
第三行 输出的内容是一个 列表(List),其中的内容是 object 这个类(class)中的全部属性和方法;
第五行 输出的内容是 object 这个类(class) 的一个属性 __doc__ 的值,通常是一段描述这个 类(class) 的文本;大致翻译如下:
类层次结构的基类。
当被调用时,它不接受任何参数并返回一个新的无特征的 实例,它没有实例属性,也不能被赋予任何属性。
这是我们刚刚才学习完的内容,应该不至于都忘了。
那么很可能已经忘了内容,再复习一下吧。
Python 里的数字包括:整型(Int)、长整型(long integers)、浮点型(floating point real values) 和 复数(complex numbers) 。其中复数用得少。(数学渣不敢说话)
Python 里有特色的数据类型包括:String(字符串)、List(列表)、Tuple(元组)和 Dictionary(字典)。
还记得它们的索引编号规则吗?记得哪些是有序的?那些是无序的?哪些是可变的?哪些是不可变的? 切片是什么?
全忘了?那你厉害了!牛批妈妈给牛批开门————牛批到家了!
Python 中的运算符有七种:其中 “成员运算符” 比较有特色,经常和 for 循环一起用,必须得掌握。 “身份运算符”用于比较2个对象的 id 是否一样,涉及到内存指针等概念,用得少。其它的如:算术运算符、比较(关系)运算符、赋值运算符、逻辑运算符(与、或、非)、以及用得较少的位运算符,与其它计算机语言中的意思一样,没什么难点。
Python 的执行语句也就是基本的:条件分支 和 循环。不过 for 循环比较有特色,通常与“成员运算符”一并使用,这个与其它语言中略有区别。其它常见的 break 、 continue 语句,Python 也是支持的,还有一个 pass 语句算是一个占位指令吧。
如果以上这些,都还在脑袋里装着呢。那么,
恭喜你,Python 可以说是有基础了,入门了!
# 第十章 虚拟环境和打包
一直有个疑问,好不容易写好一个程序,怎么交给别人用呢,特别是在 Windows 环境下。说好的一处编写、随处运行呢?结果呢?给源码人家,人家也要会用啊,还得装好 Python 、装好环境?你想 装逼 就直说呗?
“你的程序有bug?”
“怎么可能?”
“都跑不起来,一大堆乱码!”
“你丫不会用吧?”
“你说什么?就你天天写的这bug!”
......
直接给个可执行文件 .exe 不结了?
那么第二个问题来了:这点功能,程序文件这么大?玩啥呢?让你打印输出个 “Hellow World”,你给我几百兆的一个文件?你脑子有大病吧?
好吧好吧,为了世界和平、peace & love;
# 10.1、 从虚拟环境开始
在 Windows 平台,为了把写好的程序交给别人使用,当然是打包成一个可执行文件 .exe 是最直接的方式。同时,为了打包后的文件不要太大,也就是避免把那些用不上的 包、库、模块都给一股脑儿塞进去了,准备一个干净的虚拟环境是十分必要的。
如前所述,我们学习、开发的时候,安装了 AnaConda 或 MiniConda ,少说也安装了几百个库,为得是自己开发时方便,但并不是每一个都用上了(你的项目有那么复杂吗?),如果打包时把这些都塞进去了,那真是为了一句 Hellow World ,搞了一个几百兆的文件,这就搞笑了。
# 10.2、 创建一个 虚拟环境(也称虚拟机)
可以理解为新装一台电脑,里面只安装必要的库就可以了,这样就方便清爽多了。一条指令就OK了。
python -m venv myvenv
快看看,你的路径中是不是新建了一个文件夹,名为 myvenv;其中应该包含:
|--Include # 文件夹
|--Lib # 文件夹
|--Scripts # 文件夹
|pyvenv.cfg # 文件
2
3
4
实际工作中,为每个项目,单独创建一个文件夹 和 对应的虚拟环境是个好习惯。
# 10.3、 激活虚拟环境
创建虚拟环境成功之后,就可以在 Scripts 文件夹中看到有 activate.bat 这个执行文件,就是字面意思,它就是用来激活虚拟环境的批处理命令。巨坑也在此,在 Windows 10 环境中,指令前一定要加上 .\,即
.\activate.bat
回车成功之后,你会发现你的命令提示符前面,多了一对圆括号,其中就是虚拟环境文件夹的名称,如下类似:
(myvenv) PS C:\test\myvenv\scripts>
如果没有这个圆括号,说明虚拟环境,没有激活。很有可能是执行了 conda 指令。(用 conda 也可以创建、激活虚拟环境,但是.......巨坑,新手以后慢慢尝试吧。)
如果你有留心,看到 deactivate.bat ,真的要表扬你,观察仔细啊。没错,用脚也想到了,这个批处理就是 退出虚拟环境 的指令。
# 10.4、 安装/删除必要的库
已经在 虚拟环境 中了,可以用 pip list 指令来查看下,已经安装了哪些 库。有些是必须用的,有些是没必要的,根据自己的需要,添添删删吧。简单打包一个 Hellow World 根本就用不上什么库。
(myvenv) PS C:\test\myvenv\scripts> pip list
Package Version
------------------------- ---------
altgraph 0.17.3
future 0.18.2
pefile 2022.5.30
pip 22.3.1
pywin32-ctypes 0.2.0
setuptools 49.2.1
2
3
4
5
6
7
8
9
在虚拟环境中,就算把库全删了,也不用跑路。因为虚拟环境中的操作,并不会影响整个系统环境。(当然,新手最好把删库这个动作忘了,为了安全!)
# 10.5、 安装 Pyinstaller
主角登场了,就是用这个工具来打包执行文件的。当然,相似功能的工具也有,但这个相对来说简单、好用。安装的指令就是:
pip install pyinstaller
这一步应该没有什么障碍,简单。
# 10.6、 开始打包
一个打印输出 Hellow World 的程序,总共才几个字节,当然就打包成一个 .exe 文件就完事儿了呗,用以下指令:
pyinstaller -F HW.py
HW.PY 这个文件,猩猩都会写吧? 为了让我们看得很清楚,加一行等待输入的函数吧:
print("Hello World")
input("输入 Q 退出")
2
3
好了,这个打包过程真是比眨眼还快。看看你的文件夹中,是不是又新出现了2个文件夹,一个是 build、一个是 dist,我们需要的那个最终的执行文件就在 dist 中,看看它有多少字节,双击是不是可以正常运行。
到此,在 Windows 平台中,把一个 .py 的文件,打包成一个可执行的 .exe 文件,就全部完成了。(如此简单🎈)
# 本篇小结
这么简单还要小结,好吧,小结一下。
重点就是先创建一个 虚拟环境,用 python -m venv 环境名称 就好,这个指令会自动创建一个新的文件夹。然后,激活这个虚拟环境、在其中安装好必要的 库 和 Pyinstaller,最后一步,用 Pyinstaller 打包成 .exe 文件,最终的结果在 dist 这个文件夹中。
当然, Pyinstaller 功能不限于此,也支持 Linux 环境的,有兴趣的话继续探索更多玩法吧。
内置函数 →